ZK(1)——分布式系统概念与ZK简介
1. ZK 简介
ZK 是一种【分布式协调服务】,功能简介:
- 配置维护
- 域名服务
- 分布式同步
- 集群管理
1.1一致性要求
- 顺序一致性
- 原子性
- 单一视图
- 可靠性
- 实时性
1.2 Session
Session 是指客户端会话。ZK对外的服务端口默认是 2181,客户端启动时,首先会与ZK服务器建立一个TCP长连接,从第一次链接建立开始,客户端会话的生命周期也开始了,通过这个长连接,客户端能够通过心跳检测保持与服务器的有效会话,也能够向ZK服务器发送请求并接受响应,同时还能通过该连接收到来自服务器的Watcher时间通知。
Session 的 SessionTimeout 值用来检测一个客户端回话的超时时间。当由于服务器压力太大、网络故障或是客户端主动断开连接等各种原因导致客户端连接断开时,只要在Session Timeout 规定的时间内客户端能够重新开始连接上集群中任意一台服务器,那么之前创建的会话仍然有效。
1.3 zk的数据模型
ZK的文件系统采用树形结构层次化的目录结构,与Unix文件系统非常相似。每个目录在ZK中叫做一个ZNode,每个ZNode拥有一个唯一的路径标识,即名称。ZNode可以包含数据和子ZNode(临时节点不能有子ZNode)。ZNode中的数据可以有多个版本,所以查询某路径下的数据需要带上版本号。客户端应用可以在ZNode上设置监视器(Watcher)。
它很像是数据结构当中的树,也很想文件系统的目录。

树是由节点组成,zk的数据存储也同样是基于节点,这种节点叫做Znode。但是不同于树的结点,Znode的引用方式是路径引用,类似于文件路径:/动物/仓鼠 ; / 植物/荷花。
Znode包含了数据、子节点医用、访问权限等等。

- data:存储数据信息
- ACL:记录Znode的访问权限,即哪些人或者哪个IP可以访问本结点
- stat:包含Znode的各种元数据,比如:事务ID、版本号、时间戳、大小等
- child:当前节点的子节点引用,类似于二叉树的左孩子和右孩子
ZK是为了读多写少的场景所设计。Znode并不是用来存储大规模业务数据,而是用于存储少量的状态和配置信息,每个节点的数据最大不超过1MB。
- 中间件,提供协调服务
- 作用于分布式系统,发挥其优势,可以为大数据服务
1.4 Watcher
ZK通过Watcher机制实现了发布订阅模式,ZK提供了分布式数据的发布订阅功能,一个发布者能够让多个订阅者同时监听某一主题对象,当这个主体对象状态发生变化时,会通知所有订阅者,使它们能够做出相应的处理,ZK引入了Watcher机制来实现这种分布式的通知功能。ZK允许客户端向服务端注册一个Watcher监听,当服务端的一些指定事件触发这个Watcher,那么就会向指定客户端发送一个事件通知。而这个事件通知是通过TCP长连接的Session完成的。
2. 什么是分布式系统
- 概念
- 很多台计算机组成一个整体,一个整体一致对外,并且处理同一请求
- 内部的每台计算机都可以相互通信(rest/rpc)
- 客户端到服务端的一次请求到相应结束会经历多台计算机
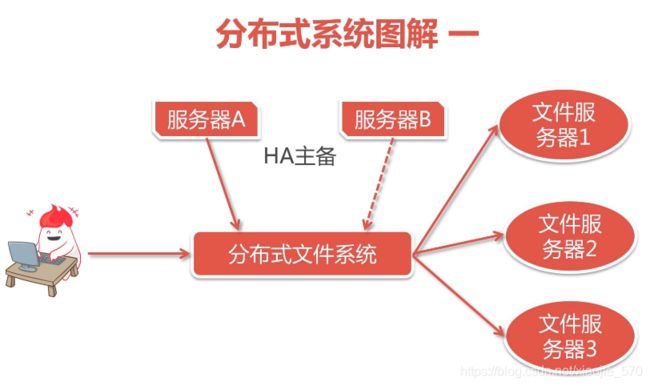

分布式系统就是将原有的一个系统拆分成不同的小系统,分布式系统对客户是不透明的。
加入我们现在有三台机器,每台机器跑同样的一个应用程序。然后我们将这三台机器通过网络将其连接起来,构成一个系统来为用户提供服务,用户是不知道这个系统的具体架构的。那么,我们就可以把这个系统称作一个分布式系统。
那么,问题来了:
【问题一】程序的运行往往依赖很多配置文件,比如数据库地址、黑名单控制、服务地址列表等,而且有些配置信息需要频繁地进行动态变更,这时候怎么保证所有机器共享的配置信息保持一致?
【问题二】如果有一台机器挂掉了,其他机器如何感知这一变化并接管服务?如果用户激增,需要增加机器来缓解压力,如何做到不重启集群而完成机器的添加?
【问题三】用户数量增加或者减少,会出现有的机器资源使用率繁忙,有的却空闲,如何让每台机器感知到其他机器的负载状态从而实现负载均衡?
【问题四】在一台机器上奥多个进行或者多个线程操作同一个资源比较简单,因为可以有大量的状态信息或者日志提供保证,比如进行A和B同时写一个文件,我们可以通过加锁的方式来实现同步。但是分布式系统怎么办?需要一个第三方的分配锁机制,几百台worker都对同一个网络中的文件写操作,怎么协同?还有怎么保证高效的运行?
3. 分布式系统的瓶颈
ZK的特性
-
一致性
- 数据一致性,数据按照顺序分批入库
-
原子性
- 事务要么成功要么失败,不会局部化
-
单一视图
- 客户端连接集群中的任意zk结点,数据都是一致的
-
可靠性
- 每次对zk的操作状态都会保存在服务端
-
实时性
- 客户端可以读取到zk服务端的最新数据
ZK身为分布式系统的协调服务,如果自身挂掉了,怎么办呢?
为了防止单机挂掉的情况,ZK维护了一个集群。ZK的集群:

ZK Service集群是一主多从结构。
在更新数据时,首先更新到主节点(这里的结点是指服务器,不是Znode),再同步到从节点。
在读取数据时,直接读取任意从节点。
ZK 是一个由多个 server 组成的集群,一个leader, 多个 follower。leader 为客践席提供读写服务,除了leader外其他的机器只能提供读服务。
每一个 server 保存一份数据副本全数据一致,分布式读 follower,写由 leader 实时更新请求转发,由leader实时更新请求顺序进行,来自同一个client 的更新请求按其发送顺序依次执行数据更新原子性,依次数据更新要么成功,要么失败。全局唯一数据视图,client无论连接到哪个 server, 数据视图都是一致的实时性,在一定事件范围内, client 能读到最新数据。
4. ZK的应用场景
- 分布式锁
这是雅虎研究院设计ZK的初衷。利用ZK的临时顺序节点,可以轻松实现分布式锁
- 服务注册和发现
利用Znode 和 Watcher,可以实现分布式服务的注册和发现。最著名的应用就是阿里的分布式RPC框架Dubbo
- 共享配置和状态信息
Redis的分布式解决方案Codis,就利用了ZK来存放数据路由表和codis-proxy节点的元信息。同时 codis-config 发起的命令都会通过ZK同步到各个存货的 codis-poroxy。
此外,Kafka、HBaee、Hadoop也都依靠ZK同步节点信息,实现高可用。
5. zk文件夹主要目录介绍
bin目录 : 主要的一些运行命令conf:存放配置文件,其中我们需要修改zk.cfgcontrib:附加的一些功能dist-maven: mvn 编译后的目录docs:文档lib:需要依赖的jar包recipes:案例demo代码src:源码
6.zk.cfg 配置
tickTime: 用于计算的时间单元。比如 session 超时: N * tickTimeinitLimit:用于集群,允许从节点连接并同步到 master 结点的初始化连接时间,以 tickTime 的倍数来表示syncLimit:用于集群,master主节点 与 从节点 之间发送消息,请求与应答时间长度(心跳机制)dataDir:必须配置,系统的快照dataLog:日志目录,如果不配只会和dataDir公用clientPort:连接服务器的端口,默认2181。


参考并感谢
[1] https://juejin.im/post/5b037d5c518825426e024473
[2] https://blog.csdn.net/u012152619/article/details/52901319
[3] https://www.imooc.com/article/251135