Flink零基础学习(二)DataSource以及kafka和Socket信息源传输实例
一:数据源有以下几种类型
* 1.基于集合:有界数据集,更偏向本地测试
* 2.基于文件,适合监听文件修改并读取内容
* 3.基于socket:监听主机的host port,从socket中获取数据
* 4.自定义addSource:无界二:详细分析
1.集合 DataStreamSourceinput =env.fromCollection(Collection data); 2.迭代器 DataStreamSource input =env.fromCollection(Iterable,Class); 3.给定的数据 DataStream input =env.fromElements(); 4.从一个迭代器里创建并行数据流 DataStreamSource input = env.fromParallelCollection(SplittableIterator,Class) 5.创建一个生成制定区间范围内的数字序列的并行数据流 DataStreamSource input = env.generateSequence(from,to); 6.基于文件 DataStreamSourcetext = env.readFile(path); 指定格式的文件输入格式读取文件 DataStreamSource text = env.readFile(fileInputFormat,path); 解释:上面两个方法内部调用的方法。它根据给定的 fileInputFormat 和读取路径读取文件。 根据提供的 watchType,这个 source 可以定期(每隔 interval 毫秒) 监测给定路径的新数据(FileProcessingMode.PROCESS_CONTINUOUSLY), 或者处理一次路径对应文件的数据并退出(FileProcessingMode.PROCESS_ONCE)。 你可以通过 pathFilter 进一步排除掉需要处理的文件,如下: DataStreamSource stream = env.readFile( myFormat,myFilePath, FileProcessingMode.PROCESS_CONTINUOUSLY,100, FilePathFilter.createDefaultFilter(),typeInfo );
三:Socket实现demo
1.maven引入
org.apache.flink
flink-java
${flink.version}
provided
org.apache.flink
flink-streaming-java_${scala.binary.version}
${flink.version}
provided
1.8.1
2.11 一个是flink版本,一个是scala预言版本
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream> dataStream=env.socketTextStream("localhost",9999)
.flatMap(new SocketTextStreamWordCount.LinSplitter())
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1); 统计方法类:
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @author zhouxl
* 实例demo
*/
public class SocketTextStreamWordCount {
public static void main(String[] args) throws Exception{
//参数检查
if(args.length !=2){
System.err.println("USAGE:\\nSocketTextStreamWordCount ");
return;
}
String hostname =args[0];
Integer port =Integer.parseInt(args[1]);
//设置流执行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//获取数据
DataStreamSource stream =env.socketTextStream(hostname,port);
//计数
SingleOutputStreamOperator> sum =stream.flatMap(new LinSplitter())
.keyBy(0)
.sum(1);
sum.print();
env.execute("Java WordCount from SocketTextStream Example");
}
public static final class LinSplitter implements FlatMapFunction>{
@Override
public void flatMap(String s, Collector> collector) throws Exception {
String[] tokens =s.toLowerCase().split("\\W+");
for(String token :tokens){
if(token.length()>0){
collector.collect(new Tuple2(token,1));
}
}
}
}
} 实验结果
1maven打包好启动jar
flink run -c com.tuya.SocketTextStreamWordCount /Users/zhouxl/flinkdemo/target/original-flinkdemo-1.0-SNAPSHOT.jar 127.0.0.1 9000
2设置控制台监听 nc -l 9000
3启动flink(sh文件启动)
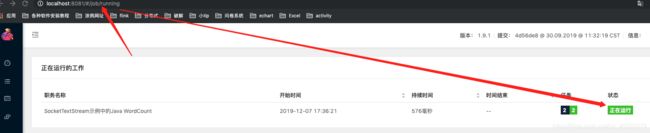
启动后

在idea控制台打印任意字符,都可以在日志(flink的log文件夹下面)看到统计结果
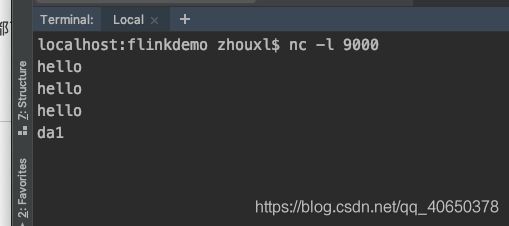
![]()
四:kafka实现demo
1.引入参考三
2.定义传递dto
@data
public class Metric {
public String name;
public long timestamp;
}
3.kafka发布类
/**
* @author zhouxl
* kafka发送工具类
*/
public class kafkaUtils {
public static final String broker_list ="kafka地址";
public static final String topic ="flink_demo";
public static void writeTokafak(Integer count) throws InterruptedException{
//生产者配置文件,具体配置可参考ProducerConfig类源码,或者参考官网介绍
Map config=new HashMap(16);
//kafka服务器地址
config.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,kafka地址);
config.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
config.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
config.put(ProducerConfig.PARTITIONER_CLASS_CONFIG," org.apache.kafka.clients.producer.internals.DefaultPartitioner");
config.put(ProducerConfig.BATCH_SIZE_CONFIG, 1024*1024*5);
KafkaProducer producer =new KafkaProducer(config);
Metric metric =new Metric();
metric.setTimestamp(System.currentTimeMillis());
metric.setName("mem");
JSON.toJSONString(metric));
ProducerRecord record =new ProducerRecord(topic,metric.toString());
Future future= producer.send(record);
producer.flush();
try{
future.get();
System.out.println("发送"+future.isDone()+"数据:"+JSON.toJSONString(metric));
}catch (Exception e){
}
}
/**
* 模拟kafka发送数据
* @param args
*/
public static void main(String[] args)throws InterruptedException{
Integer count=1;
while(true){
Thread.sleep(3000);
writeTokafak(count++);
}
}
4.flink流处理
/**
* @author zhouxl
* 接受kafka消息
*/
public class Main {
public static void main(String[] args) throws Exception{
final StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
Properties props =new Properties();
props.put("bootstrap.servers",kafka地址);
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.offset.reset","latest");
DataStreamSource dataStreamSource =env.addSource(
new FlinkKafkaConsumer("flink_demo",
//String序列化
new SimpleStringSchema(),
props
)
).setParallelism(1);
//将从kafka读到的数据打印在控制台
dataStreamSource.print();
env.execute("Flink添加kafka资源");
}
}
5实验结果
发送的结果

接受到的结果

总结:挤出点时间不容易啊