阿里天池:淘宝用户行为分析项目
数据来源:阿里天池 - 淘宝用户商品行为数据
(在这里仅选用表名为 “tianchi_mobile_recommend_train_user” 中的数据,用作淘宝用户行为分析)
项目未完待续,持续更新中。。。
一、项目背景
本数据分析报告,以阿里天池的淘宝平台交易数据集为基础,通过行业指标对淘宝用户行为进行分析,从而探索电商行业用户行为模式,并从拉新、留存、促活、转化等多运营维度提出优化建议。
- 具体指标包括:PV、UV、付费率、复购率、漏斗流失分析、用户价值RFM分析等。
- 具体分析方法:多维度拆解分析、对比分析、假设检验、复合指标分析等。
二、数据概览
表名:tianchi_mobile_recommend_train_user
包含了抽样出来的一定量用户在一个月时间(11.18~12.18)之内的移动端行为数据。
| 字段 | 字段说明 | 提取说明 |
|---|---|---|
| user_id | 用户标识 | 抽样&字段脱敏 |
| item_id | 商品表示 | 字段脱敏 |
| behavior_type | 用户对商品的行为类型 | 1 浏览、2 收藏、3 加购、4 购买 |
| user_geohash | 用户位置的空间标识,可以为空 | 由经纬度通过保密的算法生成 |
| item_category | 商品分类标识 | 字段脱敏 |
| time | 行为事件 | 精确到小时 |
三、分析思路(多维度拆解)
本次分析的目的是提高销量,将采用对比分析、多维度拆解分析、漏斗模型、RFM模型等方法,并从以下四个维度进一步拆解,通过假设检验、复合指标分析等方式,寻找优化切入点,并提出改进建议。

四、数据清洗
4.1 缺失值处理
missing_count = data.isnull().sum()
missing = missing_count[missing_count>0].sort_values(ascending=False)
missing
[Out] user_geohash 8334824 dtype: int64
缺失值仅有地理位置这一项,而由于该项经过加密处理,可作为机器学习特征,而购买行为做预测,但对于实际行为分析意义不大,因此暂时不考虑该项。
4.2 一致化处理(时间类别)
# 从 time 特征中提取出 date 与 hour,方便在不改变原数据的基础上,得到利于后续分析的时间类别
data['date'] = data['time'].map(lambda x: re.compile(' ').split(x)[0])
data['hour'] = data['time'].map(lambda x: re.compile(' ').split(x)[1])
# 将数据中的 time 与 date 转换为 datetime 类别,将 hour 类别转换为数字类别
data['time'] = pd.to_datetime(data['time'])
data['date'] = pd.to_datetime(data['date'])
data['hour'] = data['hour'].astype('int64')

4.3 异常值处理
由于数据多为时间数据、id数据,describe() 得出结果意义不大,因此采用可视化的方式,观察指标。
# behavior_type:查看是否仅有 [1, 2, 3, 4] 四类用户行为
data.behavior_type.value_counts()
# item_category:查看各个分类下用户操作行为数的分布
plt.figure(figsize=(16,3))
category_pic = data.item_category.value_counts().sort_index()
sns.scatterplot(x=category_pic.index,y=category_pic.values,alpha=0.5)
# time:查看给定时间段内用户操作行为数的分布,以及是否存在离群值
plt.figure(figsize=(16,3))
time_pic = data.time.value_counts().sort_index()
tm.plot(x=time_pic.index,y=time_pic.values)
[Out]
1 11550581
3 343564
2 242556
4 120205
Name: behavior_type, dtype: int64
behavior_type:仅有 [1, 2, 3, 4] 四类用户行为,但值得注意的是:2 类行为数(收藏)少于3 类行为数(加购),在后续将进一步对其进行分析。
item_category 与 time 列值也无明显异常值。


4.4 索引重构
data.sort_values(by='time',ascending=True,inplace=True)
data.reset_index(drop=True,inplace=True)
data.head()

五、数据分析
5.1 流量指标分析
# pv、uv 按日构建变量
# pv_daily 记录每天用户操作次数
pv_daily=data.groupby('date')['user_id'].count().reset_index().rename(columns={'user_id':'pv'})
# uv_daily 记录每天操作的用户数
uv_daily = data.groupby('date')['user_id'].apply(lambda x: x.drop_duplicates().count())
# 合并生成新表,方便后续相关性及可视化处理
pv_uv_daily = pd.merge(pv_daily,uv_daily,on='date').rename(columns={'user_id':'uv'})
# 相关性分析
# 斯皮尔曼相关性分析
s_corr_d = pv_uv_daily.corr(method='spearman').rename(columns={'pv':'s_pv','uv':'s_uv'})
# 皮尔森相关性分析
p_corr_d = pv_uv_daily.corr(method='pearson').rename(columns={'pv':'p_pv','uv':'p_uv'})
# 合并生成新表,方便可视化
corr_d = pd.concat([s_corr_d,p_corr_d],axis=1)
corr_d
# PV、UV 可视化处理(按日绘制)
x = pd.date_range(data.date.min(),data.date.max())
pv = pv_uv_daily['pv']
uv = pv_uv_daily['uv']
fig, ax1 = plt.subplots(figsize=(16,6))
ax2 = ax1.twinx()
line1, = ax1.plot(x,pv,color='steelblue')
line2, = ax2.plot(x,uv,color='red',alpha=0.7)
ax1.set_xlabel("date",fontsize=15)
ax1.set_ylabel("pv_count",color='steelblue',fontsize=15)
ax2.set_ylabel("uv_count",color='red',alpha=0.8,fontsize=15)
plt.grid(True,alpha=0.4)
plt.legend((line1,line2),('pv','uv'),fontsize=15)
plt.show()

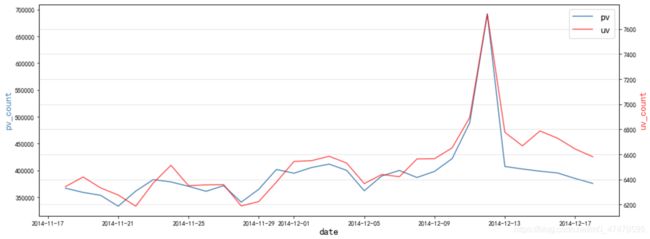
5.1.1 问题1:PV、UV 曲线整体呈现间隔性的波动起伏
- 除双十二当天外,每周周五的流量最低,推测 PV、UV 的波动工作日/周末的周期性有关,将从周期维度进一步拆分数据,从时间角度提出运营优化建议。
- 由于总数据为 2014-11-18 至 2014-12-18 期间数据,周一、周五、周六、周日均只有4天,周二、周三、周四则有五天,因此,选取周期的平均值进行可视化处理:
# 定义周期转化函数
def w_trans(w):
if w.weekday() == 0:
return 'w1'
elif w.weekday() == 1:
return 'w2'
elif w.weekday() == 2:
return 'w3'
elif w.weekday() == 3:
return 'w4'
elif w.weekday() == 4:
return 'w5'
elif w.weekday() == 5:
return 'w6'
elif w.weekday() == 6:
return 'w7'
else:
return 'error'
# 新增 weekday 特征
data['weekday'] = data['date'].apply(w_trans)
pv_uv_daily['weekday'] = pv_uv_daily['date'].apply(w_trans)
# 按周期创建新变量,包含总pv、总uv、平均pv、平均uv
w_pv = pv_uv_daily.groupby('weekday')['pv'].sum().reset_index().rename(columns={'pv':'w_pv'})
w_uv = pv_uv_daily.groupby('weekday')['uv'].sum().reset_index().rename(columns={'uv':'w_uv'})
m_pv = pv_uv_daily.groupby('weekday')['pv'].mean().reset_index().rename(columns={'pv':'m_pv'})
m_uv = pv_uv_daily.groupby('weekday')['uv'].mean().reset_index().rename(columns={'uv':'m_uv'})
w_pv_uv = pd.concat([w_pv,w_uv['w_uv'],m_pv['m_pv'],m_uv['m_uv']],axis=1)
# weekday 平均值数据可视化
x = np.arange(0,7)
m_pv = w_pv_uv['m_pv']
m_uv = w_pv_uv['m_uv']
fig,ax1=plt.subplots(figsize=(16,5))
ax2 = ax1.twinx()
line1, = ax1.plot(x,m_pv,color='steelblue')
line2, = ax2.plot(x,m_uv,color='red',alpha=0.7)
ax1.set_xlabel('weekday',fontsize=15)
ax1.set_ylabel('m_pv_count',color='steelblue',fontsize=15)
ax2.set_ylabel('m_uv_count',color='red',alpha=0.8,fontsize=15)
plt.xticks(x,['w 1','w 2','w 3','w 4','w 5','w 6','w 7'])
plt.grid(True,alpha=0.4)
plt.legend((line1,line2),('m_pv','m_uv'),fontsize=15)
plt.show()

- 从周期的流量平均值观察,周一至周三的用户行为平均次数较为稳定,而在周四与周五用户数激增后,周六流量数据迅速跌落谷底。
- 相对PV数据,浏览的用户数平均值较为稳定,尽管与PV一样,在周五上升后,周六回落,但总体偏差较小,且周一拥有较高的浏览用户平均数。
- 考虑到 12.12 双十二活动为周五,对周期性结果产生影响可能较大,因此排除双十二期间及之后数据,选取3个完整周,即 2014-11-18 至 2014-12-08 期间,流量数据,重新绘制周期流量图如下:
# 为新的区间数据建立新的变量,包含总pv、总uv、平均pv、平均uv
data_before_1208 = pv_uv_daily[pv_uv_daily['date']<='2014-12-08']
w_pv_b = data_before_1208.groupby('weekday')['pv'].sum().reset_index().rename(columns={'pv':'w_pv'})
w_uv_b = data_before_1208.groupby('weekday')['uv'].sum().reset_index().rename(columns={'uv':'w_uv'})
m_pv_b = data_before_1208.groupby('weekday')['pv'].mean().reset_index().rename(columns={'pv':'m_pv'})
m_uv_b = data_before_1208.groupby('weekday')['uv'].mean().reset_index().rename(columns={'uv':'m_uv'})
w_pv_uv_before = pd.concat([w_pv_b,w_uv_b['w_uv'],m_pv_b['m_pv'],m_uv_b['m_uv']],axis=1)
# 将创建的新变量(指定区间流量数据)与总表的流量数据做可视化对比
x = np.arange(0,7)
m_pv_total = w_pv_uv['m_pv']
m_uv_total = w_pv_uv['m_uv']
m_pv_before = w_pv_uv_before['m_pv']
m_uv_before = w_pv_uv_before['m_uv']
fig,ax1=plt.subplots(figsize=(16,5))
ax2 = ax1.twinx()
line1, = ax1.plot(x,m_pv_total,color='steelblue')
line2, = ax2.plot(x,m_uv_total,color='red',alpha=0.8)
line3, = ax1.plot(x,m_pv_before,color='steelblue',alpha=0.6)
line4, = ax2.plot(x,m_uv_before,color='red',alpha=0.5)
ax1.set_xlabel('weekday',fontsize=15)
ax1.set_ylabel('pv',color='steelblue',fontsize=15)
ax2.set_ylabel('uv',color='red',alpha=0.8,fontsize=15)
plt.xticks(x,['w 1','w 2','w 3','w 4','w 5','w 6','w 7'])
plt.grid(True,alpha=0.4)
plt.legend((line1,line2,line3,line4),('m_pv_total','m_uv_total','m_pv_before','m_uv_before'),fontsize=15)
plt.show()

将活动前后三天的流量图单独可视化如下:
pv_uv_key = pv_uv_daily[pv_uv_daily['date']>='2014-12-09']
pv_uv_key = pv_uv_key[pv_uv_key['date']<='2014-12-15']
x = pd.date_range(pv_uv_key.date.min(),pv_uv_key.date.max())
pv = pv_uv_key['pv']
uv = pv_uv_key['uv']
fig,ax1=plt.subplots(figsize=(16,5))
ax2 = ax1.twinx()
line1, = ax1.plot(x,pv,color='steelblue')
line2, = ax2.plot(x,uv,color='red',alpha=0.7)
ax1.set_xlabel('weekday',fontsize=15)
ax1.set_ylabel('pv',color='steelblue',fontsize=15)
ax2.set_ylabel('uv',color='red',alpha=0.8,fontsize=15)
plt.grid(True,alpha=0.4)
plt.legend((line1,line2),('pv','uv'),fontsize=15)
plt.show()

- 从双十二活动前(2014-11-18 至 2014-12-08)的流量数据平均值来看,周五是每周的流量谷底,而在周五之后,浏览用户数有所增长但仍不及平日,用户行为次数增长较快,推测尽管周末的浏览用户数有所下滑,但人均行为次数有所上升。
- 从流量数据的双十二活动前后对比可知,双十二带来的流量增长是巨大的。从活动前后的增长趋势对比来看,活动对流量数据的影响主要体现在活动前2天、活动当天、以及活动后一天。
- 将活动前后三天的流量数据可视化后,可以观察得到,与活动前后的平均流量数据趋势一致,活动带来的影响从前两天开始流量上涨。而在活动结束后,pv 数据迅速回落,uv 数据对比平日有所增加,推测活动结束后,尽管用户数有所上升,但人均浏览次数相对下滑。
【后续,将进一步从用户行为维度拆分数据,验证与分析用户行为转化趋势】
5.1.2 问题2:周末活跃用户数降低,但总用户行为数上升?
5.1.3 问题3:活动结束后,总用户行为数回落,但活跃用户数上升?
- 维度1:从新老顾客维度,拆分数据,分析PV/UV的变动更多是源自拉新,还是老客户回流 ?
- 维度2:从 behavior_type 维度,拆分数据,分析具体增长行为出现在哪一步 ?
behavior_type:UV 对比
behavior_uv_series = data.groupby(['date','behavior_type'])['user_id'].apply(lambda x: x.drop_duplicates().count())
# 因为得到的 behavior_uv_series 为series类型,其可视化操作我还不太熟练,因此采用本办法,一列列提取新建 DataFrame 对象,而后再进行可视化处理
behavior_uv = pd.DataFrame()
date_i = []
behavior_i = []
for i in behavior_uv_series.index:
date_i.append(i[0])
behavior_i.append(i[1])
behavior_uv['date'] = date_i
behavior_uv['behavior_type'] = behavior_i
behavior_uv['uv'] = behavior_uv_series.values
# 数据可视化
plt.figure(figsize=(16,6))
sns.lineplot(x='date',y='uv',hue='behavior_type',data=behavior_uv)

