毕业设计(基于TensorFlow的深度学习与研究)之核心篇CNN-AlexNet详解
前言
在本文中,我将会对我本科毕业设计的核心AlexNet卷积神经网络进行详细的讲解,我将会分成三个部分来进行阐述:
-
AlexNet论文讲解
-
图解AlexNet(8层)结构
-
五种花分类识别项目展示(部分代码展示)
01 - AlexNet论文讲解
在此部分中,我将围绕论文摘要简介、数据集简介、网络结构简介、减少过拟合、模型学习细节、结果展示6个方面来介绍该论文,AlexNet论文的PDF版本还请各位小伙伴们自行网上搜索。
1.1 摘要简介
首先,我们来了看一下AlexNet论文的摘要部分。从中,我们可以了解到,AlexNet神经网络具有6000万个参数和650000个神经元,包含有5个卷积层(其中某些卷积层后面带有池化层)和3个全连接层,最后是一个1000维的softmax。为了训练的更快,我们使用了一个非饱和的神经元并对卷积操作进行了非常有效的GPU实现。为了减少全连接层的过拟合,我们采用了一个最近开发的名为dropout的正则化方法,结果证明是非常有效的。
图1.1 论文摘要信息介绍:

1.2 数据集简介
紧接着,我们再来看看论文中提到的数据集ImageNet。
ImageNet数据集有超过1500万的标注高分辨率的图像,这些图像属于大约22000个类别。这些图像是从网络上收集的,使用了Amazon’s Mechanical Turk的众包工具通过人工进行标注的。从2010年起,作为Pascal视觉对象挑战赛的一部分,每年都会举办ImageNet大规模视觉识别挑战赛(ILSVRC)。ILSVRC使用ImageNet的一个子集,1000个类别每个类别大约1000张图像。总计,大约120万张训练图像,50000张验证图像和15万张测试图像。

ImageNet包含各种分辨率的图像,而我们的系统要求不变的输入维度。因此,我们将图像进行下采样到固定的256*256分辨率。给定一个矩阵图像,我们首先缩放图像短边长度为256,然后从结果图像中剪裁中心的256*256大小的图像块。除了在训练集上对像素减去平均活跃度外,我们不对图像做任何其他的预处理。因此我们在原始的RGB像素值(中心的)上训练我们的网络。
图1.2 论文数据集介绍:

1.3 网络结构简介
我们可以讲AlexNet的网络结构概括为图1.3所示。它包括8个学习层(5个Conv和3个Dense)。
图1.3 论文数据集介绍:
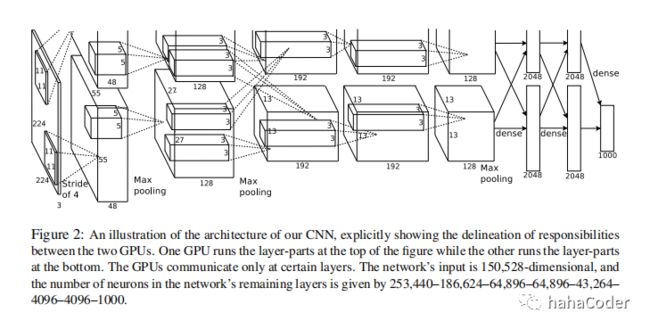
如图1.3所示,我们的网络包含8个带权重的层;前5层是卷积层,剩下的3层是全连接层。最后一层全连接层的输出是1000维softmax的输入,softmax会产生1000类标签的分布。我们的网络最大化多项逻辑回归的目标,这等价于最大化预测分布下训练样本正确标签的对数概率的均值。第2,4,5卷积层的核只位于同一GPU上的前一层的核映射相连接(见图1.3),第3卷积层的核与第2层的所有核映射相连,全连接层的神经元与前一层的所有神经元相连。第1,2卷积层之后是响应归一化层。最大池化层在响应归一化层和第五卷积层之后。ReLU非线性应用在每个卷积层和全连接层的输出上。
第一卷积层使用96个核对224*224*3的输入图像进行滤波,核大小为11*11*3,步长是4个像素(核映射中相邻神经元感受野中心之间的距离)。第2卷积层使用第1卷积层的输出(响应归一化和池化)作为输入,并使用256个核进行滤波,大小为5*5*48。第3,4,5卷积层互相连接,中间没有接入池化层或归一层。第3卷积层有384个核,核大小为3*3*256,与第2卷积层的输出(归一化,池化)相连。第4卷积层有384个核,核大小为3*3*192。第5卷积层有256个核。每个全连接层有4096个神经元。
对于AlexNet网络中涉及的一些特性,包括Relu非线性、多GPU训练、局部响应归一化以及重叠池化我们将会在毕业设计系列推文的基础知识部分进行讲解,故在本文中不再赘述。

1.4 减少过拟合
我们的神经网络架构有6000万参数。尽管ILSVRC的1000类使每个训练样本从图像到标签的映射上强加了10比特的约束,但这不足以学习这么多的参数而没有相当大的过拟合。下面,我们会描述我们用来克服过拟合的两种主要方式。
首先我们来看第一种克服过拟合的方式:数据增强。
-
第一种数据增强方式包括产生图像变换和水平翻转。我们从256*256图像上通过随机提取224*224的图像块实现了这种方式(还有它们的水平翻转),然后在这些提取的图像块上进行训练。尽管最终的训练结果是互相依赖的,但是这也通过2048因子增大了我们的训练集。没有这个方案,我们的网络会有大量的过拟合,这会迫使我们使用更小的网络。在测试时,网络会提取5个224*224的像素块(四角上的图像块和中心的图像块)和它们的水平翻转(因此总共10个图像块)进行预测,然后对网络在10个图像上的softmax层进行平均。
-
第二种数据增强方式包括训练图像的RGB通道的强度。具体地,我们在整个ImageNet训练集上对RGB像素值集合执行PCA。对于每幅训练图像,我们加上多倍找到的主要成分,大小成对比的对应特征值乘以一个随机变量,随机变量通过均值为0,标准差为0.1的高斯分布得到。
图1.4 过拟合之数据增强:

接下来,我们在看第二种克服过拟合的方式:失活。
图1.5 过拟合之失活:

将许多不同模型的预测结合起来是降低测试误差的一个非常成功的方法,但是对于需要花费几天来训练的大型神经网络来说,这似乎太昂贵了。然而,有一个非常有效的模型版本结合,它只花费两倍的训练成本。这种最近引入的技术,叫做dropout,它会以0.5的概率对每个隐层神经元的输出设为0。那些失活的神经元不再进行前向传播并且不参与反向传播。因此每次输入时,神经网络会采用一个不同的架构,但是所有架构共享权重。这个技术减少了复杂的神经元互适应,因为一个神经元不能依赖特定的其他神经元的存在。因此,神经元被强迫学习更强劲的特征,它与许多不同的其他神经元的随机子集合结合时是有用的。在测试时,我们使用所有的神经元给它们的输出乘以0.5,对指数级的许多失活网络的预测分布进行几何平均,这是合理的近似。
我们在图1.3的前两个全连接层使用失活。如果没有失活,我们的网络将表现出大量的过拟合。失活大致上使要求收敛的迭代次数翻了一倍。

1.6 模型学习细节
我们使用随机梯度下降法来训练我们的模型,样本的batch_size为128,动量为0.9,权重衰减为0.0005。我们发现少量的权重衰减对于模型的学习是重要的。换句话说,权重衰减不仅仅是一个正则项:它减少了模型的训练误差。权重更新的细节请参考图1.6中标红的部分。
图1.6 模型学习细节:

我们使用均值为0,标准差为0.01的高斯分布对每一层的权重进行初始化。我们在第2、4、5卷积层和全连接层将神经元偏置初始化为常量1。这个初始化通过为ReLU提供正输入加速了学习的早期阶段。我们在剩下的层将神经元偏执初始化为0。
我们对所有的层使用相同的学习率,这个是在整个训练过程中我们手动调整得到的。当验证误差在当前的学习率下停止提供时,我们遵循启发式的学习方法将学习率除以10。学习率初始化为0.01,在训练停止之前降低三次。我们在120万图像的训练数据集上训练神经网络大约90个循环,在两个NVIDIA GTX 580 3GB GPU上花费了五到六天。
1.7 结果展示
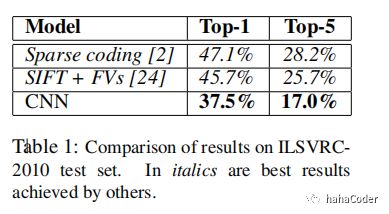
我们在ILSVRC-2010上的结果概括为图1.7(斜体字是其他人取得的最好的结果)。我们的网络获得了top-1 37.5%,top-2 17.0%的错误率。在ILSVRC-2010竞赛中最好的结果是 top-1 47.1%,top-2 28.2%。
图1.7 结果展示:

02 - 图解AlexNet(8层)结构
我们从图1.3中对AlexNet的大概网络结构有了一定的了解,接下来我们将通过图示的方法来深入解释每一层的作用原理,以及相关数据的计算。
我们首先来了解一个计算公式![]() : ,其中
: ,其中
其中输入图片大小为W*W,Filter(过滤器)大小为F*F,步长为s,padding像素数为p。
【声明】:图2.1 - 图2.8中,靠左边的为已知参数,右边的为上一层的输入数据信息(input_size)和本层的输出数据信息(output_size),其中所有output_size的计算均通过上述我们所提及的公式,这里不再展开赘述,请看下述图解过程:
图2.1 Conv1层数据计算:
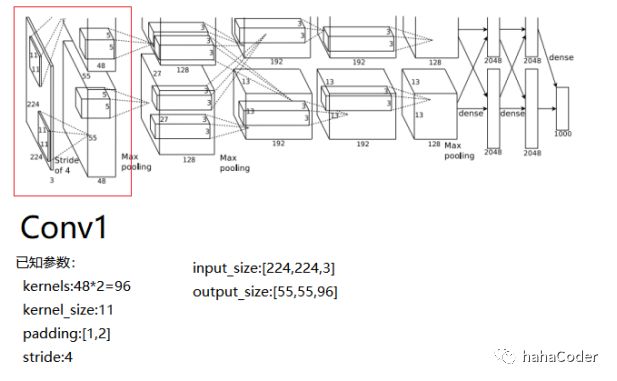
图2.2 MaxPool1层数据计算:
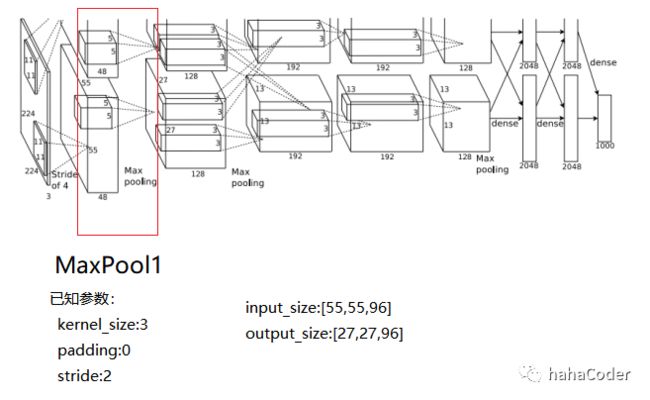
图2.3 Conv2层数据计算:
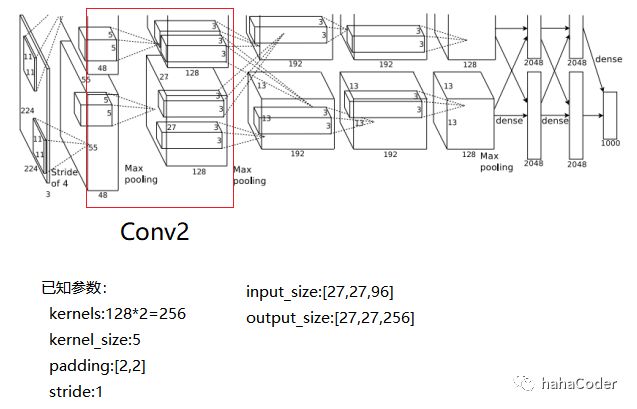
图2.4 MaxPool2层数据计算:
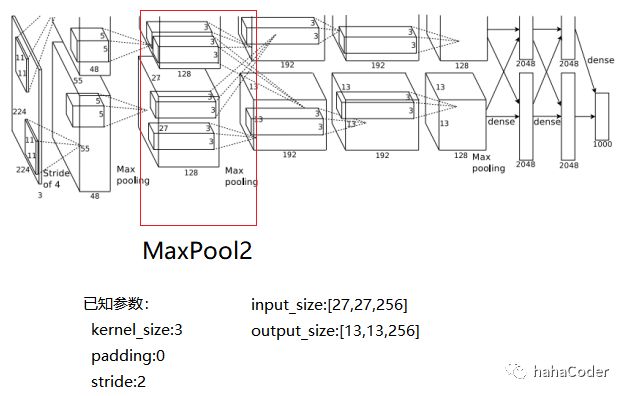
图2.5 Conv3层数据计算:
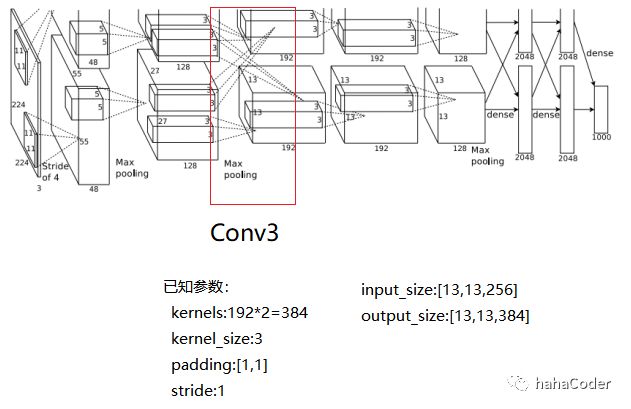
图2.6 Conv4层数据计算:
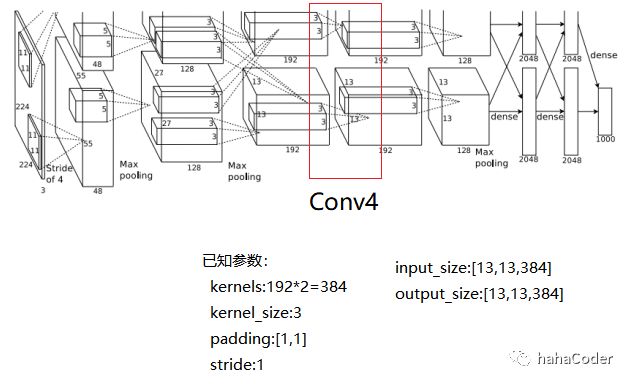
图2.7 Conv5层数据计算:
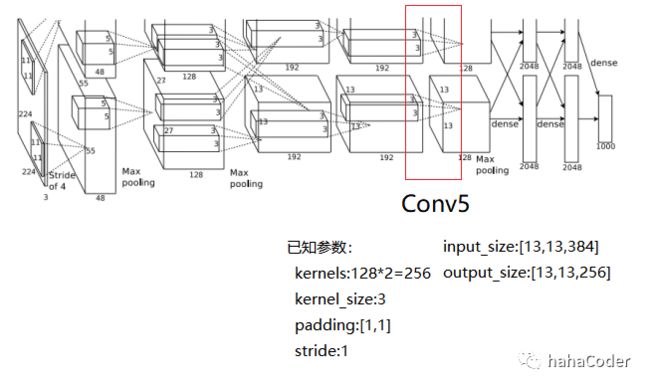
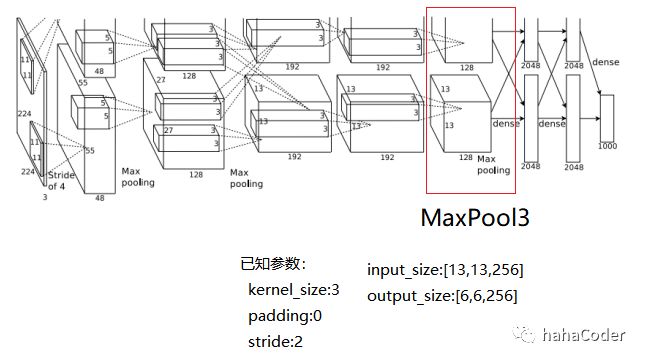
图2.8 MaxPool3层数据计算:
03 - 五种花分类识别项目展示(附部分代码展示)
我们在之前的文章毕业设计(基于TensorFlow的深度学习与研究)之完结篇中提到,我们曾通过华为云AI开发平台ModelArts将我们关于五种花分类识别的案例进行了线上的部署及测试,在这一部分中我们将通过代码来实现对数据集的训练,并通过对测试集图片的验证来观察准确率。
训练模型部分代码展示:
def AlexNet_v1(im_height=224, im_width=224, class_num=1000):
# tensorflow中的tensor通道排序是NHWC
input_image = layers.Input(shape=(im_height, im_width, 3), dtype="float32") # output(None, 224, 224, 3)
x = layers.ZeroPadding2D(((1, 2), (1, 2)))(input_image) # output(None, 227, 227, 3)
x = layers.Conv2D(48, kernel_size=11, strides=4, activation="relu")(x) # output(None, 55, 55, 48)
x = layers.MaxPool2D(pool_size=3, strides=2)(x) # output(None, 27, 27, 48)
x = layers.Conv2D(128, kernel_size=5, padding="same", activation="relu")(x) # output(None, 27, 27, 128)
x = layers.MaxPool2D(pool_size=3, strides=2)(x) # output(None, 13, 13, 128)
x = layers.Conv2D(192, kernel_size=3, padding="same", activation="relu")(x) # output(None, 13, 13, 192)
x = layers.Conv2D(192, kernel_size=3, padding="same", activation="relu")(x) # output(None, 13, 13, 192)
x = layers.Conv2D(128, kernel_size=3, padding="same", activation="relu")(x) # output(None, 13, 13, 128)
x = layers.MaxPool2D(pool_size=3, strides=2)(x) # output(None, 6, 6, 128)
x = layers.Flatten()(x) # output(None, 6*6*128)
x = layers.Dropout(0.2)(x)
x = layers.Dense(2048, activation="relu")(x) # output(None, 2048)
x = layers.Dropout(0.2)(x)
x = layers.Dense(2048, activation="relu")(x) # output(None, 2048)
x = layers.Dense(class_num)(x) # output(None, 5)
predict = layers.Softmax()(x)
model = models.Model(inputs=input_image, outputs=predict)
return model
【声明】:在上述代码中,我们并没有使用TensorFlow 2.0版本中的高阶API(包括tf.keras等),故读者在查看代码的时候请务必看准版本号,切记误将1.x版本的代码跑在2.x版本的环境下。

由于此案例中数据集数量仅有3600余张,故最终准确率相比我的推文毕业设计(基于TensorFlow的深度学习与研究)之完结篇所提及的关于MNIST手写字识别95%+的识别率稍逊一筹。
我们可以来看看通过代码训练出来的模型对五种花分类识别过程中的一些效果图:
图3.1 拟合效果图:
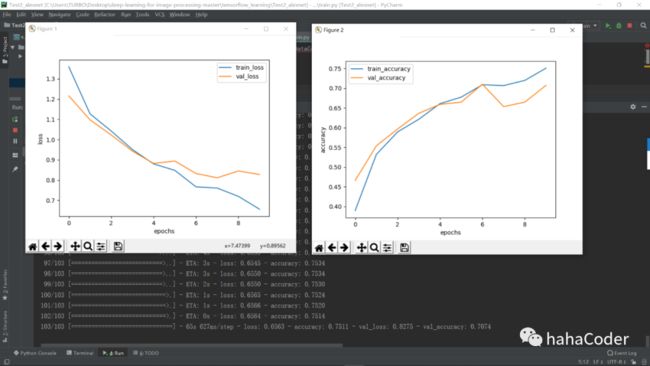
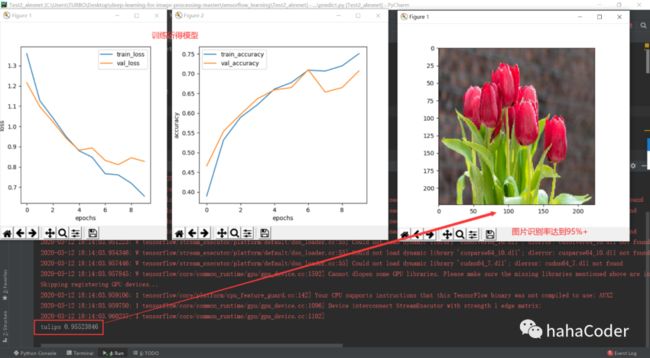
图3.2 数据集测试:
ok,我们在上文中通过对AlexNet论文的分块讲解,并结合实际案例,相信大家已经了然于心,小伙伴们可以在学习了CNN-AlexNet的基础上,再去学习GoogleNet或者LeNet等,相信学习起来一定事半功倍。
声明
本文属于我毕业设计系列推文中的一篇,其他所有的系列文章我将在答辩结束之后发布在我的微信公众平台上,届时CSDN等平台也会做相应更新。
延伸阅读
-
毕业设计(基于TensorFlow的深度学习与研究)之完结篇
-
【东拼西凑】毕业设计之论文查重篇
-
毕业设计(基于Tensorflow的深度研究与实现)之番外篇
-
TensorFlow环境搭建
-
MVVM之卡哇伊Vue源码分析plus