Redis分布式锁
Redis分布式锁
- [1] 分布式锁
- [2] redis
- [3] redisson
- [4] 牛客网总结
- [5] 常用的分布式锁
- [6] 分布式锁三种实现方式
https://www.jianshu.com/p/47fd7f86c848
在Java中,关于锁我想大家都很熟悉.在并发编程中,我们通过锁,来避免由于竞争而造成的数据不一致问题.通常,我们以synchronized 、Lock来使用它.但是Java中的锁,只能保证在同一个JVM进程内中执行.如果在分布式集群环境下呢?
[1] 分布式锁
分布式锁,是一种思想,它的实现方式有很多.比如,我们将沙滩当做分布式锁的组件,那么它看起来应该是这样的:
-
加锁:在沙滩上踩一脚,留下自己的脚印,就对应了加锁操作.其他进程或者线程,看到沙滩上已经有脚印,证明锁已被别人持有,则等待.
-
解锁:把脚印从沙滩上抹去,就是解锁的过程.
-
锁超时:为了避免死锁,我们可以设置一阵风,在单位时间后刮起,将脚印自动抹去.
分布式锁的实现有很多,比如基于数据库、memcached、Redis、系统文件、zookeeper等.它们的核心的理念跟上面的过程大致相同.
[2] redis
我们先来看如何通过单节点Redis实现一个简单的分布式锁.
1、加锁
加锁实际上就是在redis中,给Key键设置一个值,为避免死锁,并给定一个过期时间.
SET lock_key random_value NX PX 5000
值得注意的是:
random_value 是客户端生成的唯一的字符串.
NX 代表只在键不存在时,才对键进行设置操作.
PX 5000 设置键的过期时间为5000毫秒.
这样,如果上面的命令执行成功,则证明客户端获取到了锁.
2、解锁
解锁的过程就是将Key键删除.但也不能乱删,不能说客户端1的请求将客户端2的锁给删除掉.这时候random_value的作用就体现出来.
为了保证解锁操作的原子性,我们用LUA脚本完成这一操作.先判断当前锁的字符串是否与传入的值相等,是的话就删除Key,解锁成功.
if redis.call('get',KEYS[1]) == ARGV[1] then
return redis.call('del',KEYS[1])
else
return 0
end
3、实现
首先,我们在pom文件中,引入Jedis.在这里,笔者用的是最新版本,注意由于版本的不同,API可能有所差异.
<dependency>
<groupId>redis.clientsgroupId>
<artifactId>jedisartifactId>
<version>3.0.1version>
dependency>
加锁的过程很简单,就是通过SET指令来设置值,成功则返回;否则就循环等待,在timeout时间内仍未获取到锁,则获取失败.
@Service
public class RedisLock {
Logger logger = LoggerFactory.getLogger(this.getClass());
private String lock_key = "redis_lock"; //锁键
protected long internalLockLeaseTime = 30000;//锁过期时间
private long timeout = 999999; //获取锁的超时时间
//SET命令的参数
SetParams params = SetParams.setParams().nx().px(internalLockLeaseTime);
@Autowired
JedisPool jedisPool;
/**
* 加锁
* @param id
* @return
*/
public boolean lock(String id){
Jedis jedis = jedisPool.getResource();
Long start = System.currentTimeMillis();
try{
for(;;){
//SET命令返回OK ,则证明获取锁成功
String lock = jedis.set(lock_key, id, params);
if("OK".equals(lock)){
return true;
}
//否则循环等待,在timeout时间内仍未获取到锁,则获取失败
long l = System.currentTimeMillis() - start;
if (l>=timeout) {
return false;
}
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}finally {
jedis.close();
}
}
}
解锁我们通过jedis.eval来执行一段LUA就可以.将锁的Key键和生成的字符串当做参数传进来.
/**
* 解锁
* @param id
* @return
*/
public boolean unlock(String id){
Jedis jedis = jedisPool.getResource();
String script =
"if redis.call('get',KEYS[1]) == ARGV[1] then" +
" return redis.call('del',KEYS[1]) " +
"else" +
" return 0 " +
"end";
try {
Object result = jedis.eval(script, Collections.singletonList(lock_key),
Collections.singletonList(id));
if("1".equals(result.toString())){
return true;
}
return false;
}finally {
jedis.close();
}
}
最后,我们可以在多线程环境下测试一下.我们开启1000个线程,对count进行累加.调用的时候,关键是唯一字符串的生成.这里,笔者使用的是Snowflake算法.
@Controller
public class IndexController {
@Autowired
RedisLock redisLock;
int count = 0;
@RequestMapping("/index")
@ResponseBody
public String index() throws InterruptedException {
int clientcount =1000;
CountDownLatch countDownLatch = new CountDownLatch(clientcount);
ExecutorService executorService = Executors.newFixedThreadPool(clientcount);
long start = System.currentTimeMillis();
for (int i = 0;i<clientcount;i++){
executorService.execute(() -> {
//通过Snowflake算法获取唯一的ID字符串
String id = IdUtil.getId();
try {
redisLock.lock(id);
count++;
}finally {
redisLock.unlock(id);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
long end = System.currentTimeMillis();
logger.info("执行线程数:{},总耗时:{},count数为:{}",clientcount,end-start,count);
return "Hello";
}
}
至此,单节点Redis的分布式锁的实现就已经完成了.比较简单,但是问题也比较大,最重要的一点是,锁不具有可重入性.
[3] redisson
Redisson是架设在Redis基础上的一个Java驻内存数据网格(In-Memory Data Grid).充分的利用了Redis键值数据库提供的一系列优势,基于Java实用工具包中常用接口,为使用者提供了一系列具有分布式特性的常用工具类.使得原本作为协调单机多线程并发程序的工具包获得了协调分布式多机多线程并发系统的能力,大大降低了设计和研发大规模分布式系统的难度.同时结合各富特色的分布式服务,更进一步简化了分布式环境中程序相互之间的协作.
相对于Jedis而言,Redisson强大的一批.当然了,随之而来的就是它的复杂性.它里面也实现了分布式锁,而且包含多种类型的锁,更多请参阅分布式锁和同步器
1、可重入锁
上面我们自己实现的Redis分布式锁,其实不具有可重入性.那么下面我们先来看看Redisson中如何调用可重入锁.
在这里,笔者使用的是它的最新版本,3.10.1.
<dependency>
<groupId>org.redissongroupId>
<artifactId>redissonartifactId>
<version>3.10.1version>
dependency>
首先,通过配置获取RedissonClient客户端的实例,然后getLock获取锁的实例,进行操作即可.
public static void main(String[] args) {
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
config.useSingleServer().setPassword("redis1234");
final RedissonClient client = Redisson.create(config);
RLock lock = client.getLock("lock1");
try{
lock.lock();
}finally{
lock.unlock();
}
}
2、获取锁实例
我们先来看RLock lock = client.getLock("lock1"); 这句代码就是为了获取锁的实例,然后我们可以看到它返回的是一个RedissonLock对象.
public RLock getLock(String name) {
return new RedissonLock(connectionManager.getCommandExecutor(), name);
}
在RedissonLock构造方法中,主要初始化一些属性
public RedissonLock(CommandAsyncExecutor commandExecutor, String name) {
super(commandExecutor, name);
//命令执行器
this.commandExecutor = commandExecutor;
//UUID字符串
this.id = commandExecutor.getConnectionManager().getId();
//内部锁过期时间
this.internalLockLeaseTime = commandExecutor.
getConnectionManager().getCfg().getLockWatchdogTimeout();
this.entryName = id + ":" + name;
}
3、加锁
当我们调用lock方法,定位到lockInterruptibly.在这里,完成了加锁的逻辑.
public void lockInterruptibly(long leaseTime, TimeUnit unit) throws InterruptedException {
//当前线程ID
long threadId = Thread.currentThread().getId();
//尝试获取锁
Long ttl = tryAcquire(leaseTime, unit, threadId);
// 如果ttl为空,则证明获取锁成功
if (ttl == null) {
return;
}
//如果获取锁失败,则订阅到对应这个锁的channel
RFuture<RedissonLockEntry> future = subscribe(threadId);
commandExecutor.syncSubscription(future);
try {
while (true) {
//再次尝试获取锁
ttl = tryAcquire(leaseTime, unit, threadId);
//ttl为空,说明成功获取锁,返回
if (ttl == null) {
break;
}
//ttl大于0 则等待ttl时间后继续尝试获取
if (ttl >= 0) {
getEntry(threadId).getLatch().tryAcquire(ttl, TimeUnit.MILLISECONDS);
} else {
getEntry(threadId).getLatch().acquire();
}
}
} finally {
//取消对channel的订阅
unsubscribe(future, threadId);
}
//get(lockAsync(leaseTime, unit));
}
如上代码,就是加锁的全过程.先调用tryAcquire来获取锁,如果返回值ttl为空,则证明加锁成功,返回;如果不为空,则证明加锁失败.这时候,它会订阅这个锁的Channel,等待锁释放的消息,然后重新尝试获取锁.流程如下:
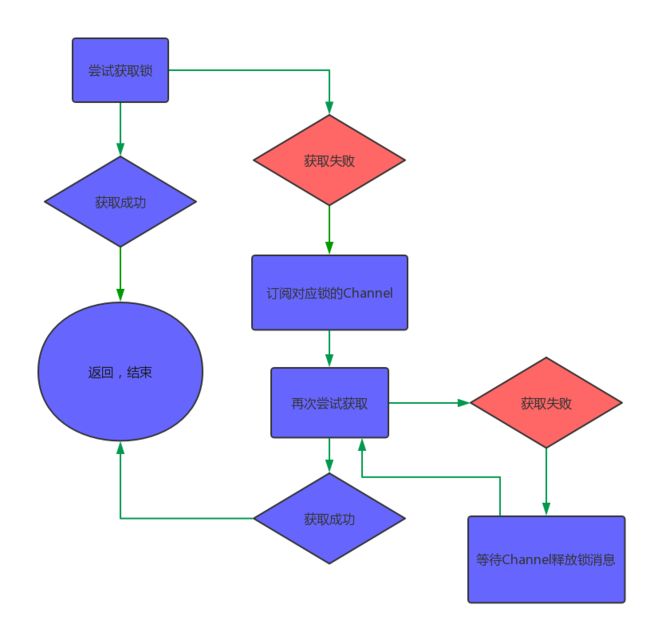
获取锁
获取锁的过程是怎样的呢?接下来就要看tryAcquire方法.在这里,它有两种处理方式,一种是带有过期时间的锁,一种是不带过期时间的锁.
private <T> RFuture<Long> tryAcquireAsync(long leaseTime, TimeUnit unit, final long threadId) {
//如果带有过期时间,则按照普通方式获取锁
if (leaseTime != -1) {
return tryLockInnerAsync(leaseTime, unit, threadId, RedisCommands.EVAL_LONG);
}
//先按照30秒的过期时间来执行获取锁的方法
RFuture<Long> ttlRemainingFuture = tryLockInnerAsync(
commandExecutor.getConnectionManager().getCfg().getLockWatchdogTimeout(),
TimeUnit.MILLISECONDS, threadId, RedisCommands.EVAL_LONG);
//如果还持有这个锁,则开启定时任务不断刷新该锁的过期时间
ttlRemainingFuture.addListener(new FutureListener<Long>() {
@Override
public void operationComplete(Future<Long> future) throws Exception {
if (!future.isSuccess()) {
return;
}
Long ttlRemaining = future.getNow();
// lock acquired
if (ttlRemaining == null) {
scheduleExpirationRenewal(threadId);
}
}
});
return ttlRemainingFuture;
}
接着往下看,tryLockInnerAsync方法是真正执行获取锁的逻辑,它是一段LUA脚本代码.在这里,它使用的是hash数据结构.
<T> RFuture<T> tryLockInnerAsync(long leaseTime, TimeUnit unit,
long threadId, RedisStrictCommand<T> command) {
//过期时间
internalLockLeaseTime = unit.toMillis(leaseTime);
return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, command,
//如果锁不存在,则通过hset设置它的值,并设置过期时间
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hset', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
//如果锁已存在,并且锁的是当前线程,则通过hincrby给数值递增1
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
//如果锁已存在,但并非本线程,则返回过期时间ttl
"return redis.call('pttl', KEYS[1]);",
Collections.<Object>singletonList(getName()),
internalLockLeaseTime, getLockName(threadId));
}
这段LUA代码看起来并不复杂,有三个判断:
- 通过exists判断,如果锁不存在,则设置值和过期时间,加锁成功
- 通过hexists判断,如果锁已存在,并且锁的是当前线程,则证明是重入锁,加锁成功
- 如果锁已存在,但锁的不是当前线程,则证明有其他线程持有锁.返回当前锁的过期时间,加锁失败
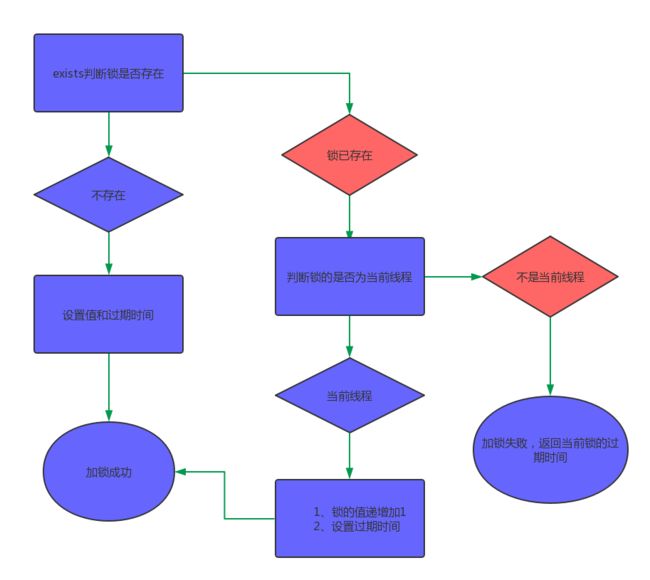
加锁成功后,在redis的内存数据中,就有一条hash结构的数据.Key为锁的名称;field为随机字符串+线程ID;值为1.如果同一线程多次调用lock方法,值递增1.
127.0.0.1:6379> hgetall lock1
1) "b5ae0be4-5623-45a5-8faa-ab7eb167ce87:1"
2) "1"
解锁
我们通过调用unlock方法来解锁.
public RFuture<Void> unlockAsync(final long threadId) {
final RPromise<Void> result = new RedissonPromise<Void>();
//解锁方法
RFuture<Boolean> future = unlockInnerAsync(threadId);
future.addListener(new FutureListener<Boolean>() {
@Override
public void operationComplete(Future<Boolean> future) throws Exception {
if (!future.isSuccess()) {
cancelExpirationRenewal(threadId);
result.tryFailure(future.cause());
return;
}
//获取返回值
Boolean opStatus = future.getNow();
//如果返回空,则证明解锁的线程和当前锁不是同一个线程,抛出异常
if (opStatus == null) {
IllegalMonitorStateException cause =
new IllegalMonitorStateException("
attempt to unlock lock, not locked by current thread by node id: "
+ id + " thread-id: " + threadId);
result.tryFailure(cause);
return;
}
//解锁成功,取消刷新过期时间的那个定时任务
if (opStatus) {
cancelExpirationRenewal(null);
}
result.trySuccess(null);
}
});
return result;
}
然后我们再看unlockInnerAsync方法.这里也是一段LUA脚本代码.
protected RFuture<Boolean> unlockInnerAsync(long threadId) {
return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, EVAL,
//如果锁已经不存在, 发布锁释放的消息
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('publish', KEYS[2], ARGV[1]); " +
"return 1; " +
"end;" +
//如果释放锁的线程和已存在锁的线程不是同一个线程,返回null
"if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then " +
"return nil;" +
"end; " +
//通过hincrby递减1的方式,释放一次锁
//若剩余次数大于0 ,则刷新过期时间
"local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1); " +
"if (counter > 0) then " +
"redis.call('pexpire', KEYS[1], ARGV[2]); " +
"return 0; " +
//否则证明锁已经释放,删除key并发布锁释放的消息
"else " +
"redis.call('del', KEYS[1]); " +
"redis.call('publish', KEYS[2], ARGV[1]); " +
"return 1; "+
"end; " +
"return nil;",
Arrays.<Object>asList(getName(), getChannelName()),
LockPubSub.unlockMessage, internalLockLeaseTime, getLockName(threadId));
}
如上代码,就是释放锁的逻辑.同样的,它也是有三个判断:
- 如果锁已经不存在,通过publish发布锁释放的消息,解锁成功
- 如果解锁的线程和当前锁的线程不是同一个,解锁失败,抛出异常
- 通过hincrby递减1,先释放一次锁.若剩余次数还大于0,则证明当前锁是重入锁,刷新过期时间;若剩余次数小于0,删除key并发布锁释放的消息,解锁成功
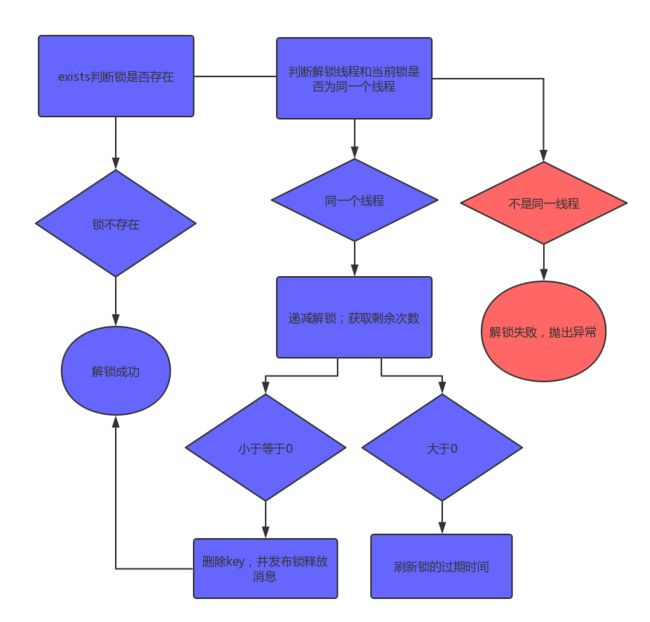
至此,Redisson中的可重入锁的逻辑,就分析完了.但值得注意的是,上面的两种实现方式都是针对单机Redis实例而进行的.如果我们有多个Redis实例,请参阅Redlock算法.该算法的具体内容,请参考http://redis.cn/topics/distlock.html
https://blog.csdn.net/weixin_43258908/article/details/89199088
https://blog.csdn.net/liubenlong007/article/details/53690312?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.compare&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.compare
https://blog.csdn.net/ai_goodStudent/article/details/86520018
- redis 服务器设置了一个 AOF 重写缓冲区.这个缓冲区在创建子进程后开始使用,当redis服务器执行一个客户端的写请求命令,之后将这个写命令也发送到 AOF 重写缓冲区.
- 当子进程完成 AOF 日志重写之后,给父进程发送信号,父进程接收此信号后,将 AOF 重写缓冲区的内容写到新的 AOF 文件中,保持数据的一致性.
[4] 牛客网总结




[5] 常用的分布式锁
https://www.jb51.net/article/184718.html
https://www.cnblogs.com/wlwl/p/11651409.html
https://www.cnblogs.com/owenma/p/12355262.html
一、基于数据库实现分布式锁
1. 悲观锁
利用select … where … for update 排他锁
注意: 其他附加功能与实现一基本一致,这里需要注意的是“where name=lock ”,name字段必须要走索引,否则会锁表.有些情况下,比如表不大,mysql优化器会不走这个索引,导致锁表问题.
2. 乐观锁
所谓乐观锁与前边最大区别在于基于CAS思想,是不具有互斥性,不会产生锁等待而消耗资源,操作过程中认为不存在并发冲突,只有update version失败后才能觉察到.我们的抢购、秒杀就是用了这种实现以防止超卖.
通过增加递增的版本号字段实现乐观锁
二、基于jdk的实现方式
思路:另启一个服务,利用jdk并发工具来控制唯一资源,如在服务中维护一个concurrentHashMap,其他服务对某个key请求锁时,通过该服务暴露的端口,以网络通信的方式发送消息,服务端解析这个消息,将concurrentHashMap中的key对应值设为true,分布式锁请求成功,可以采用基于netty通信调用,当然你想用java的bio、nio或者整合dubbo、spring cloud feign来实现通信也没问题
缺点:这种方式的分布式锁看似简单,但是要考虑可用性、可靠性、效率、扩展性的话,编码难度会比较高.
三、基于缓存(Redis等)实现分布式锁
1、官方叫做 RedLock 算法,是 redis 官方支持的分布式锁算法.
这个分布式锁有 3 个重要的考量点:
- 1.互斥(只能有一个客户端获取锁)
- 2.不能死锁
- 3.容错(只要大部分 redis 节点创建了这把锁就可以)
2、下面是redis分布式锁的各种实现方式和缺点,按照时间的发展排序
- 1、直接setnx
直接利用setnx,执行完业务逻辑后调用del释放锁,简单粗暴
缺点:如果setnx成功,还没来得及释放,服务挂了,那么这个key永远都不会被获取到 - 2、setnx设置一个过期时间
为了改正第一个方法的缺陷,我们用setnx获取锁,然后用expire对其设置一个过期时间,如果服务挂了,过期时间一到自动释放
缺点:setnx和expire是两个方法,不能保证原子性,如果在setnx之后,还没来得及expire,服务挂了,还是会出现锁不释放的问题 - 3、set nx px
redis官方为了解决第二种方式存在的缺点,在2.8版本为set指令添加了扩展参数nx和ex,保证了setnx+expire的原子性,使用方法:
set key value ex 5 nx
缺点:
①如果在过期时间内,事务还没有执行完,锁提前被自动释放,其他的线程还是可以拿到锁
②上面所说的那个缺点还会导致当前的线程释放其他线程占有的锁 - 4、加一个事务id
上面所说的第一个缺点,没有特别好的解决方法,只能把过期时间尽量设置的长一点,并且最好不要执行耗时任务
第二个缺点,可以理解为当前线程有可能会释放其他线程的锁,那么问题就转换为保证线程只能释放当前线程持有的锁,即setnx的时候将value设为任务的唯一id,释放的时候先get key比较一下value是否与当前的id相同,是则释放,否则抛异常回滚,其实也是变相地解决了第一个问题
缺点:get key和将value与id比较是两个步骤,不能保证原子性 - 5、set nx px + 事务id + lua
我们可以用lua来写一个getkey并比较的脚本,jedis/luttce/redisson对lua脚本都有很好的支持
缺点:集群环境下,对master节点申请了分布式锁,由于redis的主从同步是异步进行的,master在内存中写入了nx之后直接返回,客户端获取锁成功,此时master节点挂了,并且数据还没来得及同步,另一个节点被升级为master,这样其他的线程依然可以获取锁 - 6、redlock
为了解决上面提到的redis集群中的分布式锁问题,redis的作者antirez的提出了red lock的概念,假设集群中所有的n个master节点完全独立,并且没有主从同步,此时对所有的节点都去setnx,并且设置一个请求过期时间re和锁的过期时间le,同时re必须小于le(可以理解,不然请求3秒才拿到锁,而锁的过期时间只有1秒也太蠢了),此时如果有n / 2 + 1个节点成功拿到锁,此次分布式锁就算申请成功
缺点:可靠性还没有被广泛验证,并且严重依赖时间,好的分布式系统应该是异步的,并不能以时间为担保,程序暂停、系统延迟等都可能会导致时间错误(网上还有很多人都对这个方法提出了质疑,比如full gc发生的锁的正确性问题,但是antirez都一一作出了解答,感兴趣的同学可以参考一下这位同学的文章)
四、基于zookeeper实现的分布式锁
- 实现方式
ZooKeeper是一个为分布式应用提供一致性服务的开源组件,它内部是一个分层的文件系统目录树结构,规定同一个目录下只能有一个唯一文件名.基于ZooKeeper实现分布式锁的步骤如下:
(1)创建一个目录mylock;
(2)线程A想获取锁就在mylock目录下创建临时顺序节点;
(3)获取mylock目录下所有的子节点,然后获取比自己小的兄弟节点,如果不存在,则说明当前线程顺序号最小,获得锁;
(4)线程B获取所有节点,判断自己不是最小节点,设置监听比自己次小的节点;
(5)线程A处理完,删除自己的节点,线程B监听到变更事件,判断自己是不是最小的节点,如果是则获得锁.
这里推荐一个Apache的开源库Curator,它是一个ZooKeeper客户端,Curator提供的InterProcessMutex是分布式锁的实现,acquire方法用于获取锁,release方法用于释放锁.
优点:具备高可用、可重入、阻塞锁特性,可解决失效死锁问题.
缺点:因为需要频繁的创建和删除节点,性能上不如Redis方式.
- 两种利用特性实现原理:
- 1、利用临时节点特性
zookeeper的临时节点有两个特性,一是节点名称不能重复,二是会随着客户端退出而销毁,因此直接将key作为节点名称,能够成功创建的客户端则获取成功,失败的客户端监听成功的节点的删除事件
缺点:所有客户端监听同一个节点,但是同时只有一个节点的事件触发是有效的,造成资源的无效调度 - 2、利用顺序临时节点特性
zookeeper的顺序临时节点拥有临时节点的特性,同时,在一个父节点下创建创建的子临时顺序节点,会根据节点创建的先后顺序,用一个32位的数字作为后缀,我们可以用key创建一个根节点,然后每次申请锁的时候在其下创建顺序节点,接着获取根节点下所有的顺序节点并排序,获取顺序最小的节点,如果该节点的名称与当前添加的名称相同,则表示能够获取锁,否则监听根节点下面的处于当前节点之前的节点的删除事件,如果监听生效,则回到上一步重新判断顺序,直到获取锁.
[6] 分布式锁三种实现方式
\1. 基于数据库实现分布式锁;
\2. 基于缓存(Redis等)实现分布式锁;
\3. 基于Zookeeper实现分布式锁;
一, 基于数据库实现分布式锁
\1. 悲观锁
利用select … where … for update 排他锁
注意: 其他附加功能与实现一基本一致,这里需要注意的是“where name=lock ”,name字段必须要走索引,否则会锁表.有些情况下,比如表不大,mysql优化器会不走这个索引,导致锁表问题.
\2. 乐观锁
所谓乐观锁与前边最大区别在于基于CAS思想,是不具有互斥性,不会产生锁等待而消耗资源,操作过程中认为不存在并发冲突,只有update version失败后才能觉察到.我们的抢购、秒杀就是用了这种实现以防止超卖.
通过增加递增的版本号字段实现乐观锁
二, 基于缓存(Redis等)实现分布式锁
\1. 使用命令介绍:
(1)SETNX
SETNX key val:当且仅当key不存在时,set一个key为val的字符串,返回1;若key存在,则什么都不做,返回0.
(2)expire
expire key timeout:为key设置一个超时时间,单位为second,超过这个时间锁会自动释放,避免死锁.
(3)delete
delete key:删除key
在使用Redis实现分布式锁的时候,主要就会使用到这三个命令.
\2. 实现思想:
(1)获取锁的时候,使用setnx加锁,并使用expire命令为锁添加一个超时时间,超过该时间则自动释放锁,锁的value值为一个随机生成的UUID,通过此在释放锁的时候进行判断.
(2)获取锁的时候还设置一个获取的超时时间,若超过这个时间则放弃获取锁.
(3)释放锁的时候,通过UUID判断是不是该锁,若是该锁,则执行delete进行锁释放.
三, 基于Zookeeper实现分布式锁
ZooKeeper是一个为分布式应用提供一致性服务的开源组件,它内部是一个分层的文件系统目录树结构,规定同一个目录下只能有一个唯一文件名.基于ZooKeeper实现分布式锁的步骤如下:
(1)创建一个目录mylock;
(2)线程A想获取锁就在mylock目录下创建临时顺序节点;
(3)获取mylock目录下所有的子节点,然后获取比自己小的兄弟节点,如果不存在,则说明当前线程顺序号最小,获得锁;
(4)线程B获取所有节点,判断自己不是最小节点,设置监听比自己次小的节点;
(5)线程A处理完,删除自己的节点,线程B监听到变更事件,判断自己是不是最小的节点,如果是则获得锁.
这里推荐一个Apache的开源库Curator,它是一个ZooKeeper客户端,Curator提供的InterProcessMutex是分布式锁的实现,acquire方法用于获取锁,release方法用于释放锁.
优点:具备高可用、可重入、阻塞锁特性,可解决失效死锁问题.
缺点:因为需要频繁的创建和删除节点,性能上不如Redis方式.
四,对比
数据库分布式锁实现
缺点:
1.db操作性能较差,并且有锁表的风险
2.非阻塞操作失败后,需要轮询,占用cpu资源;
3.长时间不commit或者长时间轮询,可能会占用较多连接资源
Redis(缓存)分布式锁实现
缺点:
1.锁删除失败 过期时间不好控制
2.非阻塞,操作失败后,需要轮询,占用cpu资源;
ZK分布式锁实现
缺点:性能不如redis实现,主要原因是写操作(获取锁释放锁)都需要在Leader上执行,然后同步到follower.
总之:ZooKeeper有较好的性能和可靠性.
从理解的难易程度角度(从低到高)数据库 > 缓存 > Zookeeper
从实现的复杂性角度(从低到高)Zookeeper >= 缓存 > 数据库
从性能角度(从高到低)缓存 > Zookeeper >= 数据库
从可靠性角度(从高到低)Zookeeper > 缓存 > 数据库
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家.
总结
基于数据库分布式锁实现
优点:直接使用数据库,实现方式简单.
缺点:
- db操作性能较差,并且有锁表的风险
- 非阻塞操作失败后,需要轮询,占用cpu资源;
- 长时间不commit或者长时间轮询,可能会占用较多连接资源
基于jdk的并发工具自己实现的锁
优点:不需要引入中间件,架构简单
缺点:编写一个可靠、高可用、高效率的分布式锁服务,难度较大
基于redis缓存
\1. redis set px nx + 唯一id + lua脚本
优点:redis本身的读写性能很高,因此基于redis的分布式锁效率比较高
缺点:依赖中间件,分布式环境下可能会有节点数据同步问题,可靠性有一定的影响,如果发生则需要人工介入
\2. 基于redis的redlock
优点:可以解决redis集群的同步可用性问题
缺点:
- 依赖中间件,并没有被广泛验证,维护成本高,需要多个独立的master节点;需要同时对多个节点申请锁,降低了一些效率
- 锁删除失败 过期时间不好控制
- 非阻塞,操作失败后,需要轮询,占用cpu资源;
基于zookeeper的分布式锁
优点:不存在redis的超时、数据同步(zookeeper是同步完以后才返回)、主从切换(zookeeper主从切换的过程中服务是不可用的)的问题,可靠性很高
缺点:依赖中间件,保证了可靠性的同时牺牲了一部分效率(但是依然很高).性能不如redis.
jdk的方式不太推荐.
- 从理解的难易程度角度(从低到高)数据库 > 缓存 > Zookeeper
- 从实现的复杂性角度(从低到高)Zookeeper >= 缓存 > 数据库
- 从性能角度(从高到低)缓存 > Zookeeper >= 数据库
- 从可靠性角度(从高到低)Zookeeper > 缓存 > 数据库
没有绝对完美的实现方式,具体要选择哪一种分布式锁,需要结合每一种锁的优缺点和业务特点而定