pandas查看数据信息及数据类型转换,以及apply,map函数
apply()方法是针对某些行或列进行操作的(可以是全部列)
而applymap()方法则是针对所有元素进行操作的
map()只要是作用将函数作用于一个Series的每一个元素(map只对一个序列而言的)
注:
apply只是整个dataframe上任意一列或多列,或者一行或多行, 即可在任意轴操作。 在一列使用apply时,跟map效果一样。 多列时只能用apply。
函数map(func,iterable),有两个参数,前者是一个方法,后者是被处理的可迭代对象,返回的是map对象。当然这个map对象可以直接通过list(map)等被显示转化为列表等对象
applymap 在整个dataframe的每个元素使用一个函数。
Pandas所支持的数据类型:
1. float
2. int
3. bool
4. datetime64[ns]
5. datetime64[ns, tz]
6. timedelta[ns]
7. category
8. object
默认的数据类型是int64,float64.
查看数据类型
df.dtypes
series.dtype
get_dtype_counts()
如果一列中含有多个类型,则该列的类型会是object,同样字符串类型的列也会被当成object类型.
不同的数据类型也会被当成object,比如int32,float32
df.info() --查看数据集df的更多的详细信息.
主要有以下三种方法:
创建时指定类型,
df.astype强制类型转换,( 通过创建自定义的函数进行数据转化)
以及使用pd.to_numeric() 转换成适当数值类型(或to_datetime())。
创建时指定:
import numpy as np
import pandas as pd
df = pd.read_csv("sales_data_types.csv",dtype=np.object)
1,首先介绍最常用的astype()。
比如可以通过astype()将第一列的数据转化为整数int类型
df['Customer Number'].astype("int") ----- 这样的操作并没有改变原始的数据框,而只是返回的一个拷贝
cc1=df.astype('float')
# 想要真正的改变数据框,通常需要通过赋值来进行,比如
df["Customer Number"] = df["Customer Number"].astype("int")
注:
# 像带有特殊符号的object是不能直接通过astype("flaot)方法进行转化的,
# 这与python中的字符串转化为浮点数,都要求原始的字符都只能含有数字本身,不能含有其他的特殊字符
1,如果数据是纯净的数据,可以转化为数字
2,astype基本也就是两种用作,数字转化为单纯字符串,单纯数字的字符串转化为数字,含有其他的非数字的字符串是不能通过astype进行转化的。
二,解决含字符的类型转换,需要使用自定义函数。
1,例如: '$15,000.00 ’
方法一
def convert_currency(var):
"""
convert the string number to a float
_ 去除$
- 去除逗号,
- 转化为浮点数类型
"""
new_value = var.replace(",","").replace("$","")
return float(new_value)
# 通过replace函数将$以及逗号去掉,然后字符串转化为浮点数,让pandas选择pandas认为合适的特定类型,float或者int,该例子中将数据转化为了float64
# 通过pandas中的apply函数将2016列中的数据全部转化
df["2016"].apply(convert_currency) ---apply()---是让函数作用域于某些行或列上的元素。
df.applymap(convert_currency) ---applymap()--让函数作用于DataFrame中的每一个元素,
方法二,
# 通过lambda 函数将这个比较简单的函数一行带过
df["2016"].apply(lambda x: x.replace(",","").replace("$","")).astype("float64")
或
df.applymap(lambda x:x.replace(",","").replace("$","")).astype("float64")
对于" ‘8.0’ "这样的字符串数字。要这样做。
def convert_currency(var):
"""
convert the string number to a float
_ 去除$
- 去除逗号,
- 转化为浮点数类型
"""
new_value = var.replace("'","")
return float(new_value)
三,利用Pandas的一些辅助函数进行类型转换。
利用to_to_numeric,转换成适当数值类型。
pd.to_numeric(data['所属组'], errors='coerce').fillna(0)
这个函数所需的数据集,必须”arg must be a list, tuple, 1-d array, or Series“
这个函数只能作用于单列
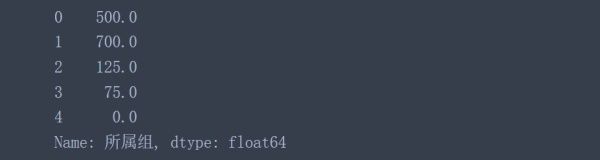
可以看到,非数值被替换成0.0了,当然这个填充值是可以选择的,具体文档见
pandas.to_numeric - pandas 0.22.0 documentation
当想作用于整个dateframe的时候,可以使用apply
1,设置遇到错误时忽略,不转换该列。
df=df.apply(pd.to_numeric,errors="ignore")
2,设置遇到错误时转换为nan。
df=df.apply(pd.to_numeric,errors="coerce")
3,设置遇到错误时报错。
df=df.apply(pd.to_numeric,errors="raise")
扩展:
1,pandas中的if语句。
# 为了转换状态列,可以使用Numpy中的where函数,把值为Y的映射成True,其他值全部映射成False。
df["Active"] = np.where(df["Active"] == "Y", True, False)
2,pandas的时间转换函数。
其中使用pd.to_datetime可以统一将time.strftime("%Y/%m/%d")生成的日期转换成日期格式的数 据。time.strftime("%Y/%m/%d")生成的日期为字符串格式。
Pandas中的to_datetime()函数可以把单独的year、month、day三列合并成一个单独的时间戳。
pd.to_datetime(data[['day', 'month', 'year']])
3,在读取数据时就对数据类型进行转换,一步到位
data2 = pd.read_csv("data.csv",
converters={
'客户编号': str,
'2016': convert_currency,
'2017': convert_currency,
'增长率': convert_percent,
'所属组': lambda x: pd.to_numeric(x, errors='coerce'),
'状态': lambda x: np.where(x == "Y", True, False)
},
encoding='gbk')
参考文章:https://www.cnblogs.com/onemorepoint/p/9404753.html
:https://www.jb51.net/article/139630.htm(重要)
:https://www.jianshu.com/p/26c48361ed24(关于时间转换)
:https://blog.csdn.net/S_o_l_o_n/article/details/80897376
:https://www.jianshu.com/p/c384ac86c4a6(关于apply,applymap,map函数)