深度学习论文精读(6):WRN
深度学习论文精读(6):WRN
论文地址:Wide Residual Networks
参考博文1:https://blog.csdn.net/app_12062011/article/details/64125729
参考博文2:https://zhuanlan.zhihu.com/p/47235521
作者源码地址:https://github.com/szagoruyko/wide-residual-networks
文章目录
- 深度学习论文精读(6):WRN
- 1 总体介绍
- 2 Wide residual networks
- 2.1 Type of convlutions in residual block
- 2.2 Number of convolutional layers per residual block
- 2.3 Width of residual blocks
- 2.4 Dropout in residual blocks
- 3 Experimental results
- 4 总结
- 单词整理:
1 总体介绍
- ResNet的提出,使得当时深度学习的发展方向:拓展深度,达到了一个巅峰。
- 但在ResNet的论文中也有提到,超过1000层后,ResNet的效果也达到了边际,甚至反而下降。同时需要的训练时间也过久。
- 本文作者尝试对ResNet Blocks的结构进行一个全面的实验,以探究ResNet的宽度与深度对整体网络效果的影响。(具体的探究包括卷积块结构,卷积层深度,卷积层宽度等。)
- 实验表明,对ResNet来说,增加宽度比增加深度给网络带来的提升要更有效。
- 在BN的论文中,作者提到,对有BN的网络添加Dropout通常性能反而会下降。然而作者在每一个bottleneck的两个conv层之间加上一个Dropout,却能得到稳定的提升。这一点的原因则是由于Dropout在网络测试时,神经元会产生variance shift导致的。在Understanding the Disharmony between Dropout and Batch Normalization by Variance Shift中,得到了充分的讨论。
2 Wide residual networks
-
将后激活CONV改成了预激活。( c o n v − B N − R e L U → B N − R e L U − c o n v \rm conv-BN-ReLU\rightarrow BN-ReLU-conv conv−BN−ReLU→BN−ReLU−conv)
-
文中各种不同的residual block的构造
- 因为实验是增加宽度,而bottleneck的目的是减小宽度以减小计算量,与目的不符,故舍弃。

本质上,提升residual boocks的representational(表达能力),有以下三种方式:
- 在每个block内部增加更多的CONV层。
- 增宽CONV层,即增加kernel的数量,拓展特征维度。
- 增大kernel size的大小。(因为3x3的kernel在许多研究中已被证明极其有效,因此不对该问题继续进行尝试。)
下图为标准的WRN结构:
- 降维操作 在conv3和conv4的第一层。使用的CONV结构为2.1节中的 B ( 3 , 3 ) B(3,3) B(3,3)。

2.1 Type of convlutions in residual block
以 B ( M ) B(M) B(M)来表示Residual block,其中M表示block里所含conv层的kernel size list;比如 B ( 3 , 1 ) B(3,1) B(3,1)表示Block里先后包含两个分别为3x3与1x1大小的Conv层。作者不考虑bottleneck模块的使用,因此block里面所有的conv层有着相同的OC(output channels)输出。以下为实验中所考虑的几种block结构。
- B ( 3 ; 3 ) B(3;3) B(3;3) - original «basic» block
- $B(3;1;3) $- with one extra 1×1 layer
- B ( 1 ; 3 ; 1 ) B(1;3;1) B(1;3;1) - with the same dimensionality of all convolutions, «straightened» bottleneck
- B ( 1 ; 3 ) B(1;3) B(1;3) - the network has alternating 1×1 - 3×3 convolutions everywhere
- B ( 3 ; 1 ) B(3;1) B(3;1) - similar idea to the previous block
- B ( 3 ; 1 ; 1 ) B(3;1;1) B(3;1;1) - Network-in-Network style block
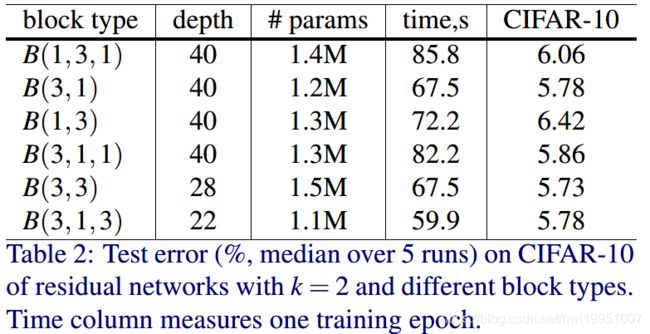
下图为以上各个结构最终能够获得的分类结果比较(注意在实验时作者为保证训练所用参数相同,因此不同类型block构成的网络的深度会有不同)。可见 B ( 3 , 3 ) B(3,3) B(3,3)能取得最好的结果,这也证明了常用Residual block的有效性。 B ( 3 , 1 , 3 ) B(3,1,3) B(3,1,3)与 B ( 3 , 1 ) B(3,1) B(3,1)性能略差,但速度却更快。接下来的实验中,作者保持了使用 B ( 3 , 3 ) B(3,3) B(3,3)这种Residual block结构。
2.2 Number of convolutional layers per residual block
以 l l l 表示单个Residual block里面conv层的数目,以 d d d 表示整体网络所具有的residual blocks的数目。通过保持整体训练所用参数不变,作者研究、分析了residual block内conv层数目不同所带来的性能结果差异。结果可见下图,从中我们能够看出residual block里面包含2个conv层可带来最优的分类结果性能。

2.3 Width of residual blocks
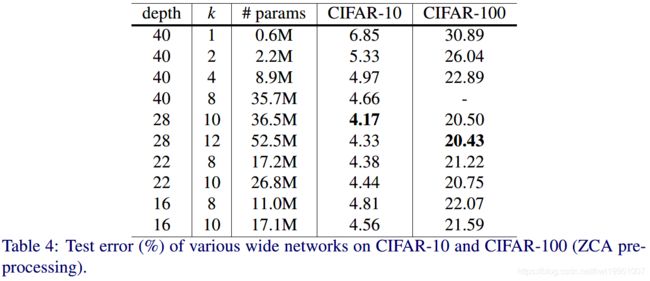
以 k k k来表示Residual block的宽度因子,并以 k = 1 k=1 k=1作为原始resnet网络中的宽度。通过增加 k k k来加宽residual blocks,并保持整体可训练参数数目不变,作者进行了广泛的实验。结果表明加大Resnet的宽度可带来比加大其深度更大的边际性能提升。具体结果可见下图。
其中,由于加宽residual blocks相比与增长ResNet深度增加的参数和计算量是二次的。因此,为了把握计算量与准确率之间的平衡,需要找到一个最优的 k k k与 d d d之间的比例。其中 d = 28 , k = 10 d=28, k=10 d=28,k=10是最理想的比例。
2.4 Dropout in residual blocks
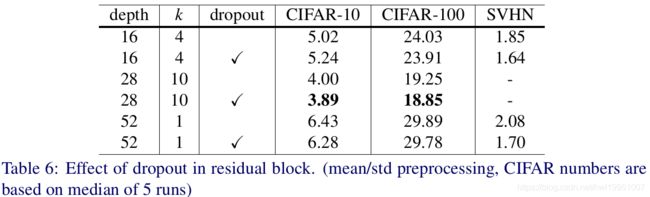
一味加宽Residual block势必会带来训练参数的激增,为了避免模型陷入过拟合的陷阱,作者试着在Residual block中引入了dropout。另外作者实验表明将Dropout加入在conv层之后比加入在identity mapping连接上可带来更好的效果。因此这里引入的Dropout被放在了Conv出来后的ReLu之后。下图中的结果反映出了Dropout带来的性能提升。
3 Experimental results
下图反映了与传统的细高Resnet相比,矮胖WRN可具有更好的精度,并且在训练的全程中保持着对Resnet的碾压态势。

下图则反映了WRN中所使用的大Tensor计算更有益于GPU计算能力的发挥。

4 总结
- 证明了在ResNet中,扩展宽度相比拓展深度拥有着更优秀的提升效果,也更适合于GPU内计算。
- 证明了ResNet出色的表现能力更主要在于Residual block,而不是深度。
单词整理:
- diminish 减少
- conduct 进行
- detail 详细,细节
- utilize 利用
- substitute 替代
- quadratic 二次
- parallel 平行
- remaining 其余
- optimal 最佳
- complementary 补充
- intriguing 奇妙