Python实现网络爬虫,爬关键词“武汉”的百度新闻
文章目录
- 1. 选取目标网页
- 2. 分析目标网页
- 3. Spider实现
- 4. items实现
- 5. pipelines实现
- 6. 结果展示
- 7.总结
Python实现爬虫的方式有很多种,如:直接用URLLib,使用Scrapy框架等。本次使用的是Scrapy框架实现的。
1. 选取目标网页
选取目标网页是百度新闻的首页,界面截图入如下:
2. 分析目标网页
分析目标网页主要工作有分析目标页面获取后台数据的方式,如:ajax还是后台直接返回,如果是后台直接返回数据,就开始分析返回response的DOM结构,设计Xpath表达式获取数据。
通过分析,百度新闻是属于后台直接返回的形式,不是Ajax。获取新闻路径是:
url = "https://www.baidu.com/s?rtt=1&bsst=1&cl=2&tn=news&rsv_dl=ns_pc&word=武汉&x_bfe_rqs=03E80&x_bfe_tjscore=0.508746&tngroupname=organic_news&newVideo=12&pn="
其中:
word=武汉,意思是我要看武汉相关的新闻;
pn=1,是页码的意思,这块要加一个变量,用于翻页;
其他参数先不用管。
3. Spider实现
实现代码:
# -*- coding: utf-8 -*-
import scrapy
from WHNews.items import WhnewsItem
class WhnewsSpider(scrapy.Spider):
name = 'whnews'
allowed_domains = ['www.baidu.com']
url = "https://www.baidu.com/s?rtt=1&bsst=1&cl=2&tn=news&rsv_dl=ns_pc&word=武汉&x_bfe_rqs=03E80&x_bfe_tjscore=0.508746&tngroupname=organic_news&newVideo=12&pn="
offset = 0
start_urls = [url+str(offset)]
headers = {
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
"Accept-Language": "zh-CN,zh;q=0.9,en-US;q=0.5,en;q=0.3",
"Accept-Encoding": "gzip, deflate",
'Content-Length': '0',
"Connection": "keep-alive"
}
def parse(self, response):
OkeyWord = ',武汉,'
NkeyWord = '武汉'
print("*" * 100)
newsList = response.xpath('//div[@class="result"]')
for news in newsList:
news_title_url = news.xpath('./h3/a/@href').extract()[0]
news_title = news.xpath('./h3/a//text()').extract()
news_title = ",".join(news_title).rstrip().strip().replace(OkeyWord, NkeyWord)
item = WhnewsItem()
item['title'] = news_title
item['url'] = news_title_url
publisherAndReleaseTime = ",".join(news.xpath('.//p[@class="c-author"]//text()').extract())
publisherAndReleaseTimeList = publisherAndReleaseTime.split("\xa0\xa0")
publisher = publisherAndReleaseTimeList[0]
item['publisher'] = str(publisher).replace(",", "").strip()
releaseTime = publisherAndReleaseTimeList[1]
item['releaseTime'] = str(releaseTime).replace("\t", "").strip()
item['pageIndex'] = self.offset
print("+"*100)
yield item
if self.offset <= 600:
self.offset = self.offset + 10
#print("response text: %s" % response.text)
#print("response headers: %s" % response.headers)
#print("response meta: %s" % response.meta)
#print("request headers: %s" % response.request.headers)
#print("request cookies: %s" % response.request.cookies)
#print("request meta: %s" % response.request.meta)
print("*" * 100)
yield scrapy.Request(self.url + str(self.offset), headers=self.headers ,callback=self.parse)
4. items实现
实现代码
# -*- coding: utf-8 -*-
import scrapy
class WhnewsItem(scrapy.Item):
#标题
title = scrapy.Field()
#发布时间
releaseTime = scrapy.Field()
#发布者
publisher = scrapy.Field()
#链接
url = scrapy.Field()
#页码
pageIndex = scrapy.Field()
5. pipelines实现
实现代码
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import MySQLdb
class WHNewsPipeline(object):
#功能:保存item数据
def __init__(self):
print("Pipeline Initialization complete")
def process_item(self, item, spider):
db = MySQLdb.connect("localhost","root","sa","spider")
cursor = db.cursor()
db.set_character_set('utf8')
cursor.execute('SET NAMES utf8;')
cursor.execute('SET CHARACTER SET utf8;')
cursor.execute('SET character_set_connection=utf8;')
query_sql = "select count(*) from `whnews` t where t.title = '%s'" %(item['title'])
cursor.execute(query_sql)
count = cursor.fetchone()
print(count[0])
if count[0] == 0:
insert_sql = "INSERT INTO `whnews` ( \
`title`, \
`releaseTime`, \
`publisher`, \
`url`, \
`pageIndex` \
)\
VALUES\
(\
'%s',\
'%s',\
'%s',\
'%s',\
'%s'\
)"%(item['title'],
item['releaseTime'],
item['publisher'],
item['url'],
item['pageIndex']
)
try:
#print(sql)
cursor.execute(insert_sql)
db.commit()
except MySQLdb.Error:
print("some error occured")
db.close()
else:
print(item['title']+" is repeat!")
return item
def close_spider(self, spider):
print("close spider")
6. 结果展示
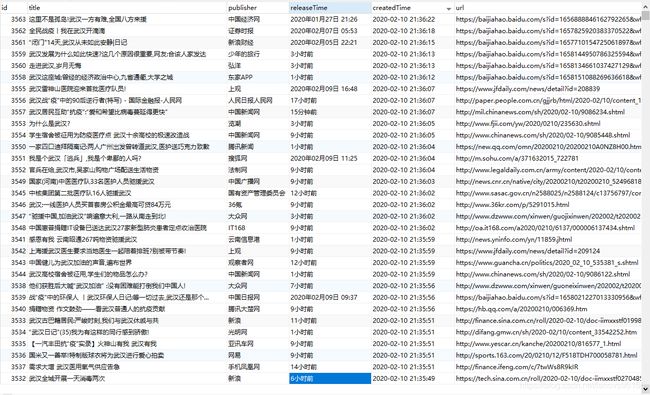
这次是将爬取的新闻信息保存到mysql数据库中,新闻的详细信息保存URL。下一步计划开始数据分析,引用场景如:舆情分析,负面舆论追溯等
截图:
7.总结
总体比较顺利,中间需要注意的点如下:
1.设计Xpath表达式获取结果
获取后台Response后,设计xpath表达式是难点,需要非常熟悉xpath表达式的语法。
2. 后台URL分析
浏览器抓包后,在无数的资源路径中准确的获取后台的URL。
3. robots设置
百度新闻的robots设置是禁爬的,所有需要对爬虫进行设置才可以。因为我们对爬取结果完全是个人使用,这里就无所谓了。但是爬虫的运行频率,间隔还是要设置恰当,避免太快。
4. 失望的结果
抛开技术层面,从新闻层面看我们获取的结果,个人觉得内容质量很差。