EM-Fusion: Dynamic Object-Level SLAM
主要内容
面向动态环境的物体级别RGB-D SLAM系统,Fusion++(robot L:【论文阅读2】Fusion++: Volumetric Object-Level SLAM)的动态场景扩展版本,具体改进如下:
- 使用期望最大法(EM)的框架解决SLAM问题。
- E步:作者结合Mask R-CNN的实例分割和几何信息(像素的SDF值),计算每个像素属于每个物体的概率,见公式(7)。归一化后,进一步得到每个像素属于每个物体的归一化概率,即关联似然,见公式(5)。
- M步:使用深度图片和SDF物体地图的直接对齐[4],独立地计算相机相对每个物体和背景的位姿。创新点在于,使用E步的关联似然作为对齐残差的权重,权重越大,说明该像素属于该物体/背景的概率越大,从而完成概率数据关联。
不足
- 没有区分静态/动态物体。导致背景像素较少,可能会影响相机位姿跟踪的质量。还会导致冗余的静态物体跟踪,消耗更多的资源。
M. Strecke, J. Stuckler. EM-Fusion: Dynamic Object-Level SLAM With Probabilistic Data Association. IEEE/CVF International Conference on Computer Vision, 5864-5873, 2019.
摘要
本文提出了一种物体级别的稠密动态SLAM。使用体素标号距离函数(Signed Distance Function,SDF)地图表示每个物体,并直接对齐RGB-D图片和SDF地图来跟踪多个物体。主要创新点是概率方法处理数据关联和遮挡问题。通过实验与SOTA方法比较,在鲁棒性和准确性上有所提高。
1 介绍
RGB-D相机在稠密3D场景获取中很受欢迎。但是大多数RGB-D SLAM方法假设环境是静态的,或者将动态物体当做外点滤除。能跟踪多个运动物体的SLAM方法还没有较多地被关注。
本文提出一种新的动态SLAM方法,能够跟踪场景中的多个物体。我们检测物体通过图片实例分割,并分别跟踪静态背景和物体。在之前的方法中,如Co-Fusion[15],MaskFusion[16],MID-Fusion[27],测量和物体的数据关联被解决通过基于图片实例分割或者通过地图中的光线投影。而我们使用概率期望最大法(EM[3])来确定像素到物体的未知关联。这种概率关联提供了额外的几何信息并隐式处理物体分割,跟踪和建图的遮挡问题(见图1)。总的来说,我们做出了如下贡献:
- 我们提出了一种概率EM构架用于动态物体级别SLAM,能够自然地处理数据关联和遮挡。
- 基于EM构架,我们通过RGB-D图片和SDF物体的直接对齐解决了多物体跟踪问题。
- 我们的方法达到了SOTA表现在用于动态物体级别SLAM的多个数据集上。

图1. 具有概率数据关联的动态物体级别SLAM。我们推理像素和物体的关联在EM框架下。E步骤基于当前图片的数据似然估计关联似然。M步骤中根据关联似然和测量更新位姿和地图。关联似然可视化结果如中间图所示。背景(上),火车(中),飞机(下)。
2 相关工作
静态SLAM:KinectFusion[13]增量跟踪相机运动并以体素SDF栅格为环境建图。一些其他RGB-D SLAM方法提出不同于ICP的跟踪方法,如直接图片对齐[10],或者SDF对齐[4],以及不同于SDF栅格的地图表示方法,如面元[9]或者关键帧[10]。大量方法向大规模环境[25][14],闭环[10][26]或者物体级别地图[12][17]方向进行探索。
动态SLAM:最近,一些RGB-D SLAM方法被提出来跟踪运动刚体。Co-Fusion[15]扩展基于面元的表示到运动物体。它组合了几何和运动分割来检测运动物体。跟踪相机和物体相对静态背景的运动基于ICP对齐使用几何和颜色信息。MaskFusion[16]没有使用运动分割,但是融合了几何信息和实例分割。MID-Fusion[27]使用类似的方法,但是使用体素SDF和octree表示3D地图。我们也是用SDF但是将跟踪构建为直接的SDF对齐[4]。此外,我们的创新策略是遮挡处理。
3 提出方法
3.1 概率动态跟踪和建图
地图由 个独立的TSDF体素 组成,其中背景是 ,其余是 个物体。在 时刻,已知视觉观测 (深度图片),需要跟踪相机相对物体和背景的位姿 。SLAM被构建为一个最大似然问题
(1)
我们首先优化相机位姿的后验,然后优化地图的后验。每个像素可以分配给一个物体或者背景,从而我们需要找到数据关联 。
3.2 期望最大框架
EM是一种解决隐式数据关联问题的自然框架,在已知地图和相机位姿估计的前提下。在EM中,我们将地图和相机位姿作为待优化的参数 。在E步骤,我们恢复关联似然的变分近似假设在之前的EM轮中已知了当前的参数估计,
(2)
其中 时,上式取最大值。在M步,我们最大化期望对数后验
(3)
注意 。
在我们的例子中,E步可以被执行通过评估
(4)
由于我们假设像素间的关联似然统计独立,关联似然可以独立地对每个像素确定。假设均匀先验概率,我们得到
(5)
M步骤对每个物体单独地被解决通过考虑像素到物体的关联似然。我们在之前的地图中优化相机位姿,然后使用新位姿估计将测量整合到地图中。
下面,我们将详细叙述EM算法的实现。
3.3 图片预处理和投影
我们在原始图片中使用双边滤波器来平滑深度虚假测量。从滤波后的深度地图 中,我们计算3D点坐标 对每个像素 。
3.4 地图表示
我们表示背景和物体通过体素SDFs。SDF 是点 到最近表面的符号距离。物体表面被决定通过SDF的零水平集 。我们实现体素SDF通过3D体素栅格中的离散化。栅格内点的SDF值通过三线性插值得到。背景维护一个分辨率为 的体素,每个检测物体维护一个初始分辨率为 的体素。
3.5 实例检测和分割
对于实例检测和分割,我们基本遵循Fusion++[12]中的做法。首先使用Mask R-CNN[7]检测和分割实例。但是Mask R-CNN的处理频率较低(每30帧处理一次),因此只有一部分帧能够被执行实例检测。如果检测结果可用,我们匹配检测和当前地图中的物体,并创建新物体如果没有匹配的检测。
类似Fusion++[12],我们迭代地估计点 的前景概率 通过在对应的体素中计数。每个体素 的前景计数 和背景计数 被更新通过关联的分割,
(6)
体素被投影到图片中以确定来自Mask R-CNN在关联的分割中的分割似然 。在用于可视化和模型掩膜生成的光线投影中,一个来自物体 的点 被呈现仅当 ,并且没有其他模型在这条光线上具有更短的距离。为了补偿可能的遮挡,我们只执行(6)中的更新在非遮挡区域。
为了匹配检测和物体,我们发现在地图中的物体在当前图片中的重投影分割通过光线投影。我们确定重投影分割和检测分割的重叠通过IoU测量。分割被关联如果IoU最大并且高于某个阈值(0.2在本实验中)。类似Fusion++[12],未匹配的分割被用于创建新物体。具体细节见Fusion++[12]。
因为Mask R-CNN可能误检,我们遵循Fusion++[12],并维护一个存在性概率 。我们删除物体如果 。
3.6 数据关联
我们关联当前帧中的像素 根据等式5。我们建模像素落在物体 的地图体素中的数据似然为一个混合分布,
(7)
其中 是物体 的SDF。混合分布由一个反映测量在物体内的拉普拉斯分布和一个建模外点测量的均匀分布组成。如果像素不在物体 的地图体素中,我们设置像素相对该物体的数据似然为零。
3.7 跟踪
大多数现存解决动态多物体SLAM的方法是使用ICP算法的变体(ICP[2])来跟踪相机位姿。而我们遵循[4],关联深度测量和表面上的最近点。这被达到通过最小化测量点到表面的符号距离,这通过该点的SDF函数给出。该策略的主要优势是像素被关联到隐式表面仅需要查询每个像素的三线性插值。在ICP中,投影关联仅被执行一次,并且需要多次查询直到表面被找到。
对于等式(3)中的M步,我们估计相机相对SDF体素的位姿通过最小化
(8)
其中 ,并且 是像素 对于背景或者物体的关联似然。我们使用Huber模来达到对外点的鲁棒性。
我们比较了仅使用前景概率没有几何信息的方法,通过使用 替代 。虽然前景概率也提供了一种分割信息,但是它用于跟踪不够鲁棒,因为Mask R-CNN的不准确实例分割。
3.8 建图
相机位姿 被估计后,我们将深度图片整合到背景和物体体素地图中。遵循[5],我们使用迭代积分
(10)
其中 是体素和积分深度图片间的深度差。注意到权重的计算中使用了关联似然 。 防止对SDf估计过度自信。非运动物体一开始也被整合到背景地图中。
4 实验
我们使用Co-Fusion发布的仿真数据集[15]和一个RGBD基准数据集[22]中的动态场景数据定性和定量地评估我们方法的表现。
4.1 定量实验
动态物体跟踪。我们使用Co-Fusion发布的仿真数据集[15]定量比较了我们和SOTA方法对动态物体的跟踪结果。SOTA方法包括Kintinuous (KT) [25],ElasticFusion (EF) [26],Co-Fusion (CF) [15]和MaskFusion (MF) [16]。前两者是静态SLAM系统,只估计相机位姿;后两者为背景和多物体跟踪系统,同时估计相机位姿和多个物体的运动轨迹。评估结果如表1所示。
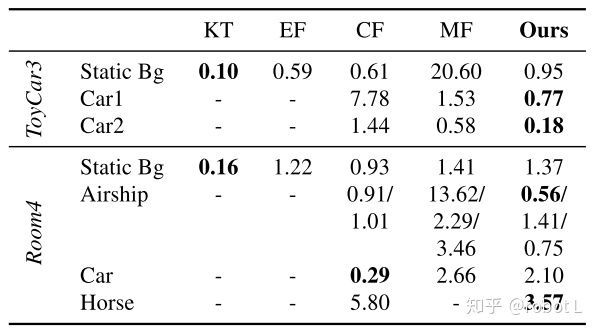
表1. 估计的轨迹误差,度量指标为AT-RMSEs (in cm)。
鲁棒的相机跟踪。注意,类似MaskFusion[16]和MID-Fusin [27],我们将Mask R-CNN检测的人标号不作为背景/物体进行重建和跟踪。在RGBD基准数据集[22]中与SOTA方法进行了比较,包括联合视觉里程计和光流(VO-SF)[8],StaticFusion (SF) [19],CF [15], MF [16], MID-Fusion (MID-F) [27]。和其它方法一样,我们的方法会失败如果未检测到的物体占据图片的大部分时。

表2. 鲁棒相机跟踪的比较。度量指标包括AT-RMSE (cm)和RP-RMSE (cm/s)。
表3展示了消融实验以证明我们方法各部分的贡献。实验分别验证了两个部分:不使用关联似然和在跟踪中不使用置信度权重。
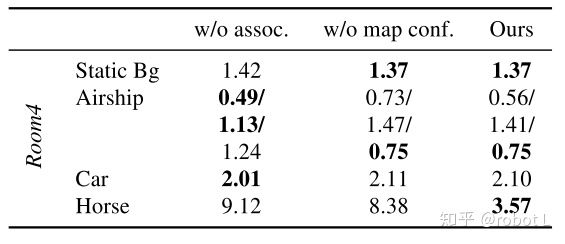
表3. 在Co-Fusion发布的仿真数据集的Room4序列中的消融实验。
计算表现。平均每帧的运行时间为106ms-257ms。
4.2 定性实验
图4展示了Co-Fusion发布的一个仿真序列[15]中的定量评估结果。

图4. 定性评估。
部分参考文献
[4] E. Bylow, J. Sturm, C. Kerl, F. Kahl, D. Cremers. Real-Time Camera Tracking and 3D Reconstruction Using Signed Distance Functions. Robotics: Science and Systems, 2013.
[12] J. McCormac, R. Clark, M. Bloesch, A. J. Davision, S. Leutenegger. Fusion++: Volumetric Object-Level SLAM. International Conference on 3D Vision, 32-41, 2018.