运用maskrcnn benchmark训练自己的数据集
最近一个项目需要做目标的检测识别,采用了目前最棒的mask rcnn,下面介绍一下流程:
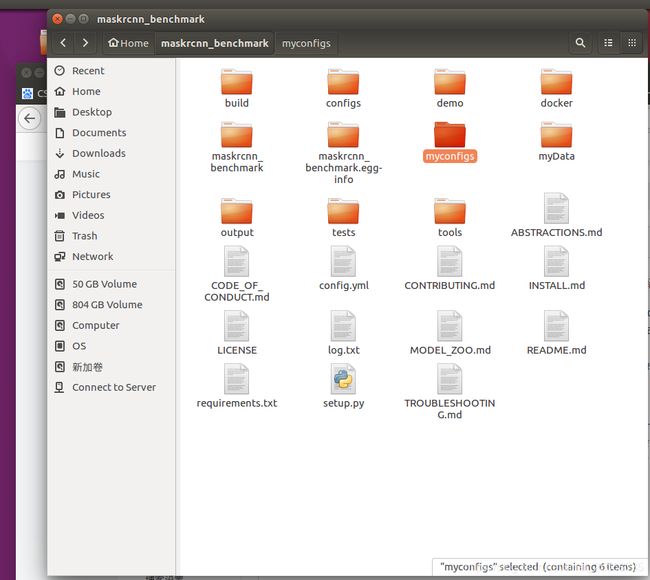
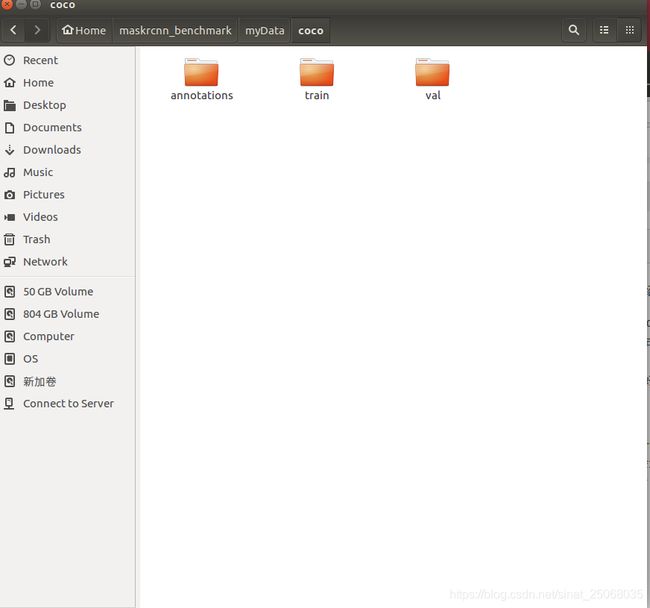
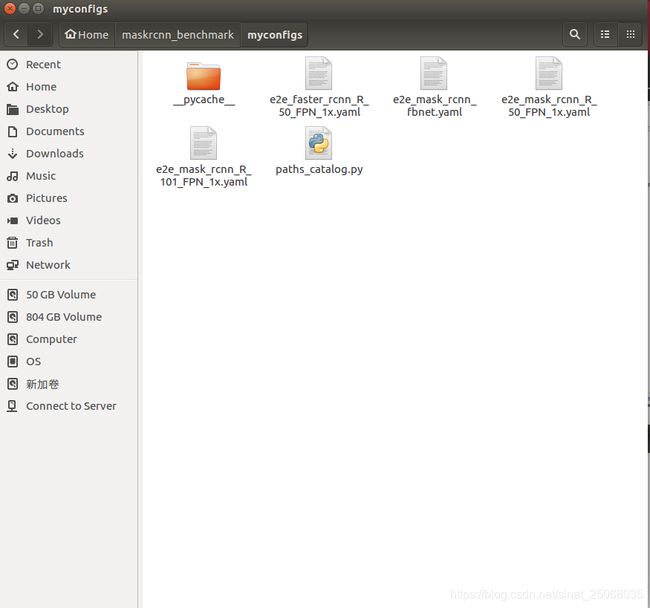
1.首先在maskrcnn的文件夹中建一个myData和myconfigs,然后myData下mkdir一个coco,coco里面分别是train,val,annotations,前面是用来放训练集和测试集,后面的保存coco格式的.json文件。myconfigs里面保存这样几个文件,一个是configs里面选择的网络格式(.yaml)文件,选取一个后复制到myconfigs,另外就是把maskrcnn benchmark/config打开,复制__pycache__和paths_catalogs.py到myconfigs,这样以来,文件都处理好了!
2.接下俩运用labelme标注,用labelme标注的时候格式一定要写成父类+子类+num,因为这个和你之后转换成coco格式训练集合的代码是匹配的,我这里给出的代码需要的是这种格式,标注好每一张图片就会生成相应名称的.json文件,将我下面贴下来的代码复制后分别放在和你的训练集,测试集同目录下的py文件中,运行就会生成new.json,重命名后(train.json, val.json)放入annotations文件夹。
这里不发截图了,比较简单,转换成coco的代码如下:
import argparse
import json
import matplotlib.pyplot as plt
import skimage.io as io
import cv2
from labelme import utils
import numpy as np
import glob
import PIL.Image
class labelme2coco(object):
def __init__(self,labelme_json=[],save_json_path='./new.json'):
'''
:param labelme_json: 所有labelme的json文件路径组成的列表
:param save_json_path: json保存位置
'''
self.labelme_json=labelme_json
self.save_json_path=save_json_path
self.images=[]
self.categories=[]
self.annotations=[]
# self.data_coco = {}
self.label=[]
self.annID=1
self.height=0
self.width=0
self.save_json()
def data_transfer(self):
for num,json_file in enumerate(self.labelme_json):
with open(json_file,'r') as fp:
data = json.load(fp) # 加载json文件
self.images.append(self.image(data,num))
for shapes in data['shapes']:
label=shapes['label'].split('_')
if label[1] not in self.label:
self.categories.append(self.categorie(label))
self.label.append(label[1])
points=shapes['points']
self.annotations.append(self.annotation(points,label,num))
self.annID+=1
def image(self,data,num):
image={}
img = utils.img_b64_to_arr(data['imageData']) # 解析原图片数据
# img=io.imread(data['imagePath']) # 通过图片路径打开图片
# img = cv2.imread(data['imagePath'], 0)
height, width = img.shape[:2]
img = None
image['height']=height
image['width'] = width
image['id']=num+1
image['file_name'] = data['imagePath'].split('/')[-1]
self.height=height
self.width=width
return image
def categorie(self,label):
categorie={}
categorie['supercategory'] = label[0]
categorie['id']=len(self.label)+1 # 0 默认为背景
categorie['name'] = label[1]
return categorie
def annotation(self,points,label,num):
annotation={}
annotation['segmentation']=[list(np.asarray(points).flatten())]
annotation['iscrowd'] = 0
annotation['image_id'] = num+1
# annotation['bbox'] = str(self.getbbox(points)) # 使用list保存json文件时报错(不知道为什么)
# list(map(int,a[1:-1].split(','))) a=annotation['bbox'] 使用该方式转成list
annotation['bbox'] = list(map(float,self.getbbox(points)))
annotation['category_id'] = self.getcatid(label)
annotation['id'] = self.annID
return annotation
def getcatid(self,label):
for categorie in self.categories:
if label[1]==categorie['name']:
return categorie['id']
return -1
def getbbox(self,points):
# img = np.zeros([self.height,self.width],np.uint8)
# cv2.polylines(img, [np.asarray(points)], True, 1, lineType=cv2.LINE_AA) # 画边界线
# cv2.fillPoly(img, [np.asarray(points)], 1) # 画多边形 内部像素值为1
polygons = points
mask = self.polygons_to_mask([self.height,self.width], polygons)
return self.mask2box(mask)
def mask2box(self, mask):
'''从mask反算出其边框
mask:[h,w] 0、1组成的图片
1对应对象,只需计算1对应的行列号(左上角行列号,右下角行列号,就可以算出其边框)
'''
# np.where(mask==1)
index = np.argwhere(mask == 1)
rows = index[:, 0]
clos = index[:, 1]
# 解析左上角行列号
left_top_r = np.min(rows) # y
left_top_c = np.min(clos) # x
# 解析右下角行列号
right_bottom_r = np.max(rows)
right_bottom_c = np.max(clos)
# return [(left_top_r,left_top_c),(right_bottom_r,right_bottom_c)]
# return [(left_top_c, left_top_r), (right_bottom_c, right_bottom_r)]
# return [left_top_c, left_top_r, right_bottom_c, right_bottom_r] # [x1,y1,x2,y2]
return [left_top_c, left_top_r, right_bottom_c-left_top_c, right_bottom_r-left_top_r] # [x1,y1,w,h] 对应COCO的bbox格式
def polygons_to_mask(self,img_shape, polygons):
mask = np.zeros(img_shape, dtype=np.uint8)
mask = PIL.Image.fromarray(mask)
xy = list(map(tuple, polygons))
PIL.ImageDraw.Draw(mask).polygon(xy=xy, outline=1, fill=1)
mask = np.array(mask, dtype=bool)
return mask
def data2coco(self):
data_coco={}
data_coco['images']=self.images
data_coco['categories']=self.categories
data_coco['annotations']=self.annotations
return data_coco
def save_json(self):
self.data_transfer()
self.data_coco = self.data2coco()
# 保存json文件
json.dump(self.data_coco, open(self.save_json_path, 'w'), indent=4) # indent=4 更加美观显示
labelme_json=glob.glob('./*.json')
# labelme_json=['./1.json']
labelme2coco(labelme_json,'./new.json')
3.开始改训练集,测试集的路径,已经一些参数,这里有一个点要注意,就是修改maskrcnn benchmark/utils下的checkpoint,需要注释这两行(65, 68),不然你修改的参数不能覆盖原参数。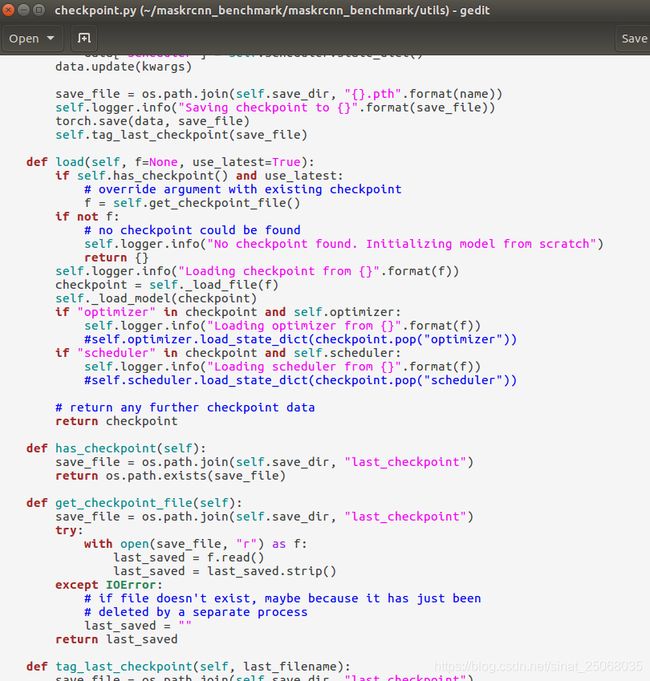
self.optimizer.load_state..
self.scheduler.load_...这两句,这样你就可以修改参数了。
首先修改路径,在myconfigs下:

首先DATA_DIR改为"myData", 然后coco_2014_train,coco_2014_val那里分别写上你的train.json的路径以及annotations的路径,val也类似
改完了路径就开始改参数吧:
选好了网络之后(.yaml)文件,例如我选择的是
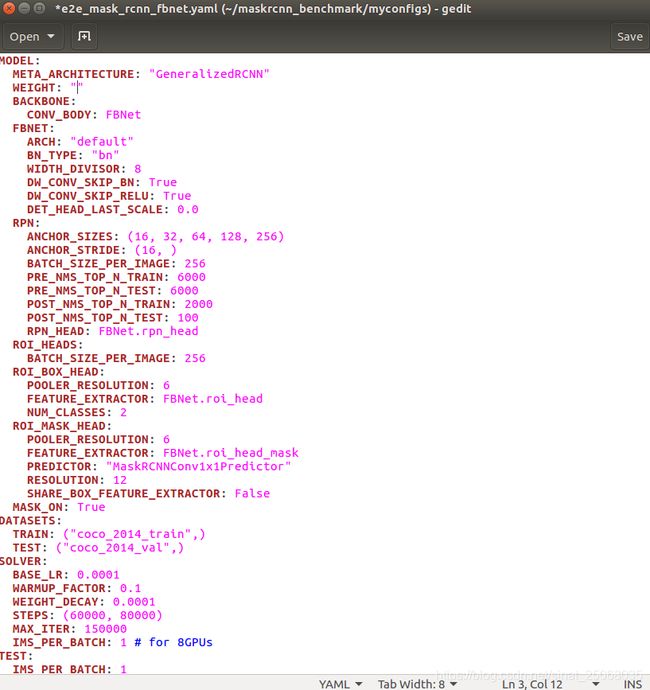
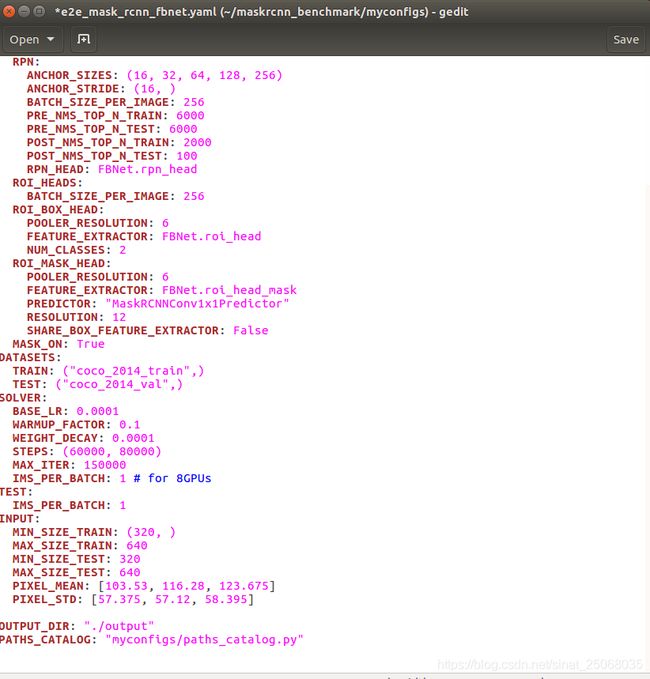
对比较关键的参数说明一下,weight的话如果训练自己的一般就”“, 表示从头训练,NUM_CLASSES这个改成你自己的分类数目+1(背景),DATASET携程跟我一样就好,因为之前改路径的时候字典的名就是这个,lr一般小一点,0.0001就可以,然后IMS_PER_BATCH改为1,(我只有一张2080ti,显存12g,原文中是8个k80总共192g显存写的16,根据比例关系可以计算一下。然后TEST的IMS_PER_BATCH我也写的1,这个可以写大一点。OUTPUT那里写你要保存参数的位置,我这用的output,之后会在你的maskrcnn文件下新建一个output,看我放的第一张图就可以看到,最后PATH_CATALOG:也按照我的写吧,如果你之前的步骤跟我一样,哈哈哈,接下来就可以训练了.....
训练:
如果你按照官方的方法建造了虚拟的annaconda的环境,在maskrcnn下打开terminal,然后输入以下即可:
conda activate maskrcnn_benchmark
python tools/train_net.py --config-file "m2e_mask_rcnn_fbnet.yaml"
configs-file后面的根据你的情况写,我这里用的fbnet.yaml,然后就是训练啦。
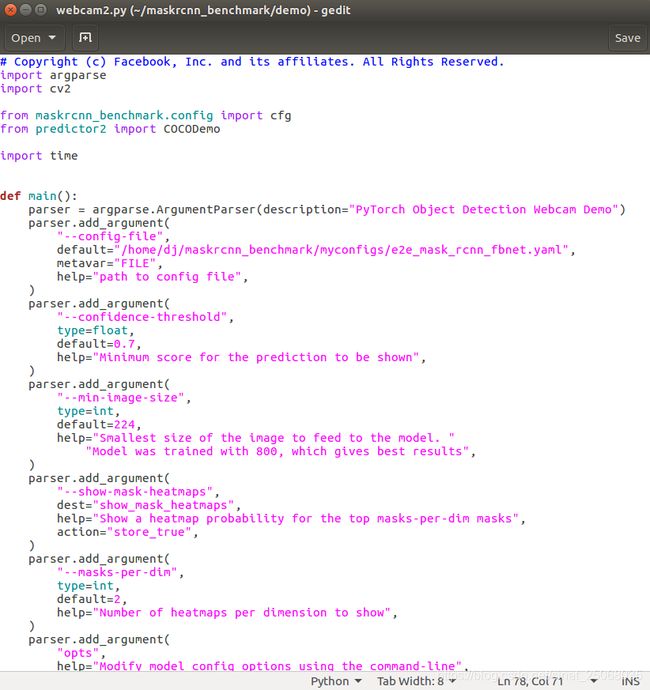
训练完成后,在你的yaml文件的WEIGHT加上你的output中生成的model_final.pth文件的路径,然后打开maskrcnn下的demo文件,首先吧predictor.py中的类改为你的类,比如我这里是box,然后在webcam.py中改路径,default该为你的myconfigs下的.yaml文件的路径,接下来就可以demo了,我也附上我修改后检测图片的代码,希望大家能够实验顺利!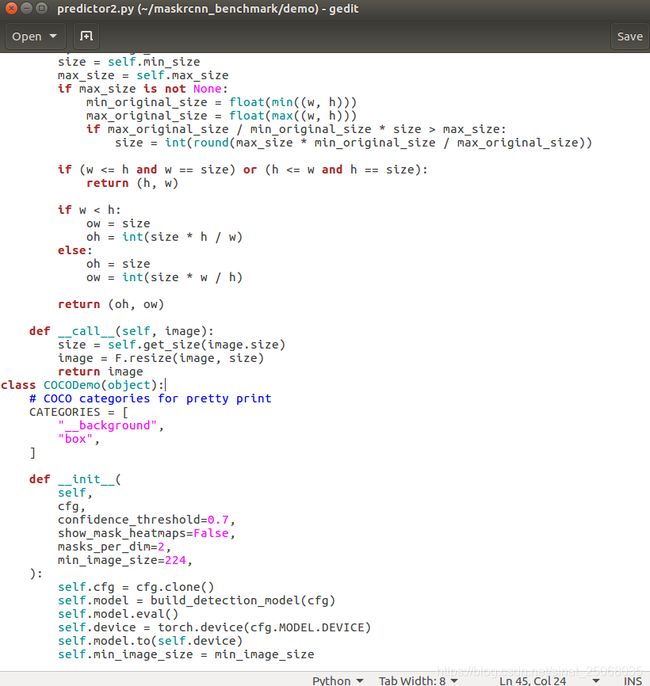

如果有问题请大家指出,非常感谢