简单二分查找、复杂二分查找与跳表
1.查找的分类
1.1 查找表
用于查找的数据集合称之为查找表,它由同一类型的数据元素(或记录)组成,可以是一个数组或者链表等数据结构。对查找表经常进行的操作一般有四种:
1.查询某个特定的数据是否在查找表中。
2.检索满足条件的某个特定的数据元素的各种属性。
3.在查找表中插入一个数据元素。
4.从查找表中删除某个数据元素。
1.2 静态查找表与动态查找表
如果一个查找表的操作只涉及到1和2的操作,则无需动态地修改查找表,此类查找表称之为静态查找表,反之称之为动态查找表。
适合静态查找表的查找方法有:顺序查找、折半查找、散列查找等。
适合动态查找表的查找方法有:二叉排序树查找、散列查找等。
1.3 平均查找长度
在所有查找过程中进行关键字的比较次数的平均值。其数学定义为:
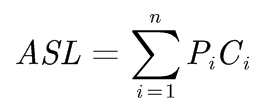
n是查找表的长度,Pi是查找第i个数据元素的概率,一般认为每个数据元素的查找概率相等,即1/n,Ci是找到第i个数据元素所需要的比较次数。平均查找长度是衡量查找算法效率的最主要指标。
2.简单二分查找
我们用一张图简单说明一下二分查找:

2.1 O(logn)惊人的查找速度
二分查找是一种非常高效的查找算法,高效到什么程度呢?我们来分析一下它的时间复杂度。
我们假设数据大小是 n,每次查找后数据都会缩小为原来的一半,也就是会除以 2。最坏情况下,直到查找区间被缩小为空,才停止。

可以看出来,这是一个等比数列。其中 n/2^(k)=1 时,k 的值就是总共缩小的次数。而每一次缩小操作只涉及两个数据的大小比较,所以,经过了 k 次区间缩小操作,时间复杂度就是 O(k)。通过 n/2^(k)=1,我们可以求得 k=log2n,所以时间复杂度就是 O(logn)。
二分查找是我们目前为止遇到的第一个时间复杂度为 O(logn) 的算法。后面章节我们还会讲堆、二叉树的操作等等,它们的时间复杂度也是 O(logn)。我这里就再深入地讲讲 O(logn) 这种对数时间复杂度。这是一种极其高效的时间复杂度,有的时候甚至比时间复杂度是常量级 O(1) 的算法还要高效。为什么这么说呢?
因为 logn 是一个非常“恐怖”的数量级,即便 n 非常非常大,对应的 logn 也很小。比如 n 等于 2 的 32 次方,这个数很大了吧?大约是 42 亿。也就是说,如果我们在 42 亿个数据中用二分查找一个数据,最多需要比较 32 次。
我们前面讲过,用大 O 标记法表示时间复杂度的时候,会省略掉常数、系数和低阶。对于常量级时间复杂度的算法来说,O(1) 有可能表示的是一个非常大的常量值,比如 O(1000)、O(10000)。所以,常量级时间复杂度的算法有时候可能还没有 O(logn) 的算法执行效率高。
2.2 二分查找的非递归实现与递归实现
public class binarySearchTest {
public static int binarySearch(int[] a,int n,int value){
//非递归实现
int low=0;
int high=n-1;
while(low<=high){
int mid=(low+high)/2;
if(a[mid]==value){
return mid;
}else if(a[mid]<value){
low=mid+1;
}else{
high=mid-1;
}
}
return -1;
}
public static int binarySearch1(int[] a,int n,int value){
return binarySearchInternally(a,0,n-1,value);
}
public static int binarySearchInternally(int[] a,int low,int high,int value){
//递归实现
if(low>high){
return -1;
}
int mid=(low+high)/2;
if(a[mid]==value){
return mid;
}else if(a[mid]<value){
return binarySearchInternally(a,mid+1,high,value);
}else{
return binarySearchInternally(a,low,mid-1,value);
}
}
public static void main(String[] args){
int[] a={
1,3,6,18,22,56,89,100};
int k=binarySearch1(a,8,22);
System.out.println(k);
}
}
2.3 二分查找应用场景的局限性
1.二分查找依赖的是顺序表结构,简单点说就是数组。
那二分查找能否依赖其他数据结构呢?比如链表。答案是不可以的,主要原因是二分查找算法需要按照下标随机访问元素。我们在数组和链表那两节讲过,数组按照下标随机访问数据的时间复杂度是 O(1),而链表随机访问的时间复杂度是 O(n)。所以,如果数据使用链表存储,二分查找的时间复杂就会变得很高。
2.其次,二分查找针对的是有序数据。
二分查找对这一点的要求比较苛刻,数据必须是有序的。如果数据没有序,我们需要先排序。前面章节里我们讲到,排序的时间复杂度最低是 O(nlogn)。
所以,如果我们针对的是一组静态的数据,没有频繁地插入、删除,我们可以进行一次排序,多次二分查找。这样排序的成本可被均摊,二分查找的边际成本就会比较低。
但是,如果我们的数据集合有频繁的插入和删除操作,要想用二分查找,要么每次插入、删除操作之后保证数据仍然有序,要么在每次二分查找之前都先进行排序。针对这种动态数据集合,无论哪种方法,维护有序的成本都是很高的。所以,二分查找只能用在插入、删除操作不频繁,一次排序多次查找的场景中。针对动态变化的数据集合,二分查找将不再适用。那针对动态数据集合,如何在其中快速查找某个数据呢?别急,等到二叉树那一节我会详细讲。
3.再次,数据量太小不适合二分查找。
如果要处理的数据量很小,完全没有必要用二分查找,顺序遍历就足够了。比如我们在一个大小为 10 的数组中查找一个元素,不管用二分查找还是顺序遍历,查找速度都差不多。只有数据量比较大的时候,二分查找的优势才会比较明显。不过,这里有一个例外。如果数据之间的比较操作非常耗时,不管数据量大小,我都推荐使用二分查找。比如,数组中存储的都是长度超过 300 的字符串,如此长的两个字符串之间比对大小,就会非常耗时。我们需要尽可能地减少比较次数,而比较次数的减少会大大提高性能,这个时候二分查找就比顺序遍历更有优势。
4.最后,数据量太大也不适合二分查找
二分查找的底层需要依赖数组这种数据结构,而数组为了支持随机访问的特性,要求内存空间连续,对内存的要求比较苛刻。比如,我们有 1GB 大小的数据,如果希望用数组来存储,那就需要 1GB 的连续内存空间。注意这里的“连续”二字,也就是说,即便有 2GB 的内存空间剩余,但是如果这剩余的 2GB 内存空间都是零散的,没有连续的 1GB 大小的内存空间,那照样无法申请一个 1GB 大小的数组。而我们的二分查找是作用在数组这种数据结构之上的,所以太大的数据用数组存储就比较吃力了,也就不能用二分查找了。
3.复杂二分查找
简单二分查找只涉及到了二分查找最简单的情况:即没有重复元素的二分查找。我们来看一下集中常见的二分查找变形问题。
3.1 查找第一个值等于给定值的元素
上一节中的二分查找是最简单的一种,即有序数据集合中不存在重复的数据,我们在其中查找值等于某个给定值的数据。如果我们将这个问题稍微修改下,有序数据集合中存在重复的数据,我们希望找到第一个值等于给定值的数据,这样之前的二分查找代码还能继续工作吗?
public int binarySearch2(int[] a,int n,int value){
//查找第一个值等于给定值的元素
int low=0;
int high=n-1;
while(low<=high){
int mid=(low+high)/2;
if(a[mid]>value){
high=mid-1;
}else if(a[mid]<value){
low=mid+1;
}else{
if((mid==0)||(a[mid-1]!=value)){
return mid;
}
else{
//即a[mid-1]==value的情况
high=mid-1;
}
}
}
return -1;
}
我来稍微解释一下这段代码。a[mid]跟要查找的 value 的大小关系有三种情况:大于、小于、等于。对于 a[mid]>value 的情况,我们需要更新 high= mid-1;对于 a[mid] 3.2 查找最后一个值等于给定值的元素 有了上一节的铺垫,这一节的代码就非常好理解了: 3.3 查找第一个大于等于给定值的元素 现在我们再来看另外一类变形问题。在有序数组中,查找第一个大于等于给定值的元素。比如,数组中存储的这样一个序列:3,4,6,7,10。如果查找第一个大于等于 5 的元素,那就是 6。 3.4 查找最后一个小于等于给定值的元素 上一节我说过,凡是用二分查找能解决的,绝大部分我们更倾向于用散列表或者二叉查找树。即便是二分查找在内存使用上更节省,但是毕竟内存如此紧缺的情况并不多。那二分查找真的没什么用处了吗? 因为二分查找底层以来的是数组随机访问的特性,所以只能用数组来实现。如果存储在链表中,就真的没法用二分查找算法了吗? 5.1 跳表:链表加多重索引 对于一个单链表来讲,即便链表中存储的数据是有序的,如果我们要想在其中查找某个数据,也只能从头到尾遍历链表。这样查找效率就会很低,时间复杂度会很高,是 O(n)。 5.2 跳表的时间复杂度 前面我讲过,算法的执行效率可以通过时间复杂度来度量,这里依旧可以用。我们知道,在一个单链表中查询某个数据的时间复杂度是 O(n)。那在一个具有多级索引的跳表中,查询某个数据的时间复杂度是多少呢? 5.3 跳表的空间复杂度 比起单纯的单链表,跳表需要存储多级索引,肯定要消耗更多的存储空间。那到底需要消耗多少额外的存储空间呢?我们来分析一下跳表的空间复杂度。 5.4 高效的动态插入和删除 跳表长什么样子我想你应该已经很清楚了,它的查找操作我们刚才也讲过了。实际上,跳表这个动态数据结构,不仅支持查找操作,还支持动态的插入、删除操作,而且插入、删除操作的时间复杂度也是 O(logn)。 5.5 跳表索引动态更新 当我们不停地往跳表中插入数据时,如果我们不更新索引,就有可能出现某 2 个索引结点之间数据非常多的情况。极端情况下,跳表还会退化成单链表。 public int binarySearch3(int[] a,int n,int value){
//查找最后一个值等于给定值的元素
int low=0;
int high=n-1;
while(low<=high){
int mid=(low+high)/2;
if(a[mid]>value){
high=mid-1;
}else if(a[mid]<value){
low=mid+1;
}else{
if((mid==n-1)||(a[mid+1]!=value)){
return mid;
}else{
low=mid+1;
}
}
}
return -1;
}
public int binarySearch4(int[] a,int n,int value){
//查找第一个大于等于给定值的元素
int low=0;
int high=n-1;
while(low<=high){
int mid=(low+high)/2;
if(a[mid]>=value){
if((mid==0)||(a[mid-1]<value)){
return mid;
}else{
high=mid-1;
}
}else{
low=mid+1;
}
}
return -1;
}
public int binarySearch5(int[] a,int n,int value){
//查找最后一个小于等于给定值的元素
int low=0;
int high=n-1;
while(low<=high){
int mid=(low+high)/2;
if(a[mid]>value){
high=mid-1;
}else{
if((mid==n-1)||(a[mid+1]>value)){
return mid;
}else{
low=mid+1;
}
}
}
return -1;
}
4.二分查找总结
实际上,上一节讲的求“值等于给定值”的二分查找确实不怎么会被用到,二分查找更适合用在“近似”查找问题,在这类问题上,二分查找的优势更加明显。比如今天讲的这几种变体问题,用其他数据结构,比如散列表、二叉树,就比较难实现了。5.跳表
实际上,我们只需要对链表稍加改造,就可以支持类似“二分”的查找算法。我们把改造之后的数据结构称之为跳表。
Redis中的有序集合(Sorted Set)就是用跳表来实现的。

那怎么来提高查找效率呢?
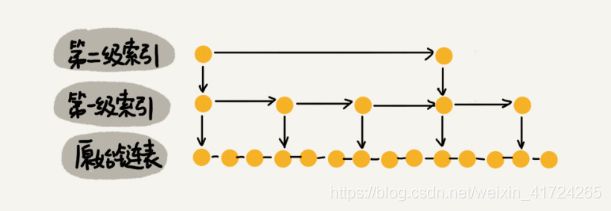
那怎么来提高查找效率呢?如果像图中那样,对链表建立一级“索引”,查找起来是不是就会更快一些呢?每两个结点提取一个结点到上一级,我们把抽出来的那一级叫作索引或索引层。你可以看我画的图。图中的 down 表示 down 指针,指向下一级结点。
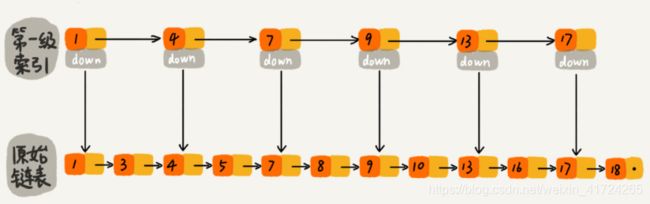
如果我们现在要查找某个结点,比如 16。我们可以先在索引层遍历,当遍历到索引层中值为 13 的结点时,我们发现下一个结点是 17,那要查找的结点 16 肯定就在这两个结点之间。然后我们通过索引层结点的 down 指针,下降到原始链表这一层,继续遍历。这个时候,我们只需要再遍历 2 个结点,就可以找到值等于 16 的这个结点了。这样,原来如果要查找 16,需要遍历 10 个结点,现在只需要遍历 7 个结点。
从这个例子中,我们可以看出,加入一层索引之后,查找一个节点所需要遍历的节点个数减少了,也就是说查找效率提高了。那么我们再加一层索引呢?是不是效率会再提高?
跟前面建立第一级索引的方式相似,我们在第一级索引的基础之上,每两个结点就抽出一个结点到第二级索引。现在我们再来查找 16,只需要遍历 6 个结点了,需要遍历的结点数量又减少了。
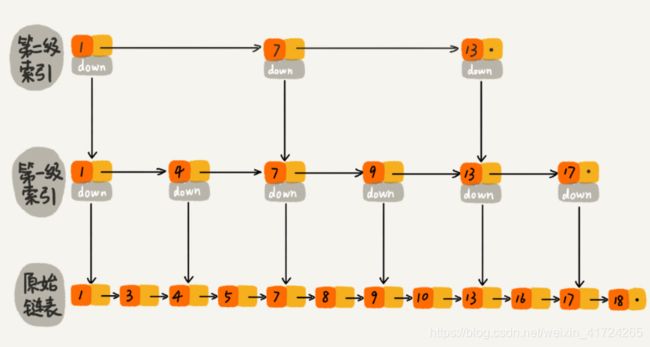
我举的例子数据量不大,所以即便加了两级索引,查找效率的提升也并不明显。为了让你能真切地感受索引提升查询效率。我画了一个包含 64 个结点的链表,按照前面讲的这种思路,建立了五级索引。
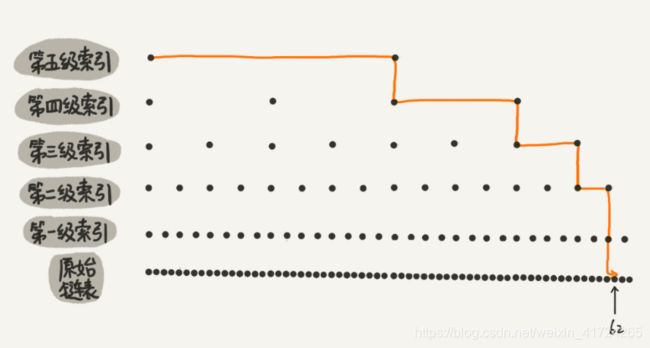
从图中我们可以看出,原来没有索引的时候,查找 62 需要遍历 62 个结点,现在只需要遍历 11 个结点,速度是不是提高了很多?所以,当链表的长度 n 比较大时,比如 1000、10000 的时候,在构建索引之后,查找效率的提升就会非常明显。
前面讲的这种链表加多级索引的结构,就是跳表。我通过例子给你展示了跳表是如何减少查询次数的,现在你应该比较清晰地知道,跳表确实是可以提高查询效率的。接下来,我会定量地分析一下,用跳表查询到底有多快。
这个时间复杂度的分析方法比较难想到。我把问题分解一下,先来看这样一个问题,如果链表里有 n 个结点,会有多少级索引呢?
按照我们刚才讲的,每两个结点会抽出一个结点作为上一级索引的结点,那第一级索引的结点个数大约就是 n/2,第二级索引的结点个数大约就是 n/4,第三级索引的结点个数大约就是 n/8,依次类推,也就是说,第 k 级索引的结点个数是第 k-1 级索引的结点个数的 1/2,那第 k级索引结点的个数就是 n/(2k)。
假设索引有 h 级,最高级的索引有 2 个结点。通过上面的公式,我们可以得到 n/(2^h)=2,从而求得 h=log2n-1。如果包含原始链表这一层,整个跳表的高度就是 log2n。我们在跳表中查询某个数据的时候,如果每一层都要遍历 m 个结点,那在跳表中查询一个数据的时间复杂度就是 O(m*logn)。
那这个 m 的值是多少呢?按照前面这种索引结构,我们每一级索引都最多只需要遍历 3 个结点,也就是说 m=3,为什么是 3 呢?我来解释一下。
假设我们要查找的数据是 x,在第 k 级索引中,我们遍历到 y 结点之后,发现 x 大于 y,小于后面的结点 z,所以我们通过 y 的 down 指针,从第 k 级索引下降到第 k-1 级索引。在第 k-1 级索引中,y 和 z 之间只有 3 个结点(包含 y 和 z),所以,我们在 K-1 级索引中最多只需要遍历 3 个结点,依次类推,每一级索引都最多只需要遍历 3 个结点。
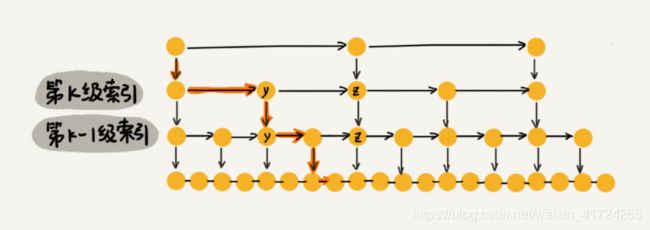
通过上面的分析,我们得到 m=3,所以在跳表中查询任意数据的时间复杂度就是 O(logn)。这个查找的时间复杂度跟二分查找是一样的。换句话说,我们其实是基于单链表实现了二分查找,是不是很神奇?不过,天下没有免费的午餐,这种查询效率的提升,前提是建立了很多级索引,也就是我们在第 6 节讲过的空间换时间的设计思路。跳表是不是很浪费内存?
跳表的空间复杂度分析并不难,我在前面说了,假设原始链表大小为 n,那第一级索引大约有 n/2 个结点,第二级索引大约有 n/4 个结点,以此类推,每上升一级就减少一半,直到剩下 2 个结点。如果我们把每层索引的结点数写出来,就是一个等比数列。

这几级索引的结点总和就是 n/2+n/4+n/8…+8+4+2=n-2。所以,跳表的空间复杂度是 O(n)。也就是说,如果将包含 n 个结点的单链表构造成跳表,我们需要额外再用接近 n 个结点的存储空间。那我们有没有办法降低索引占用的内存空间呢?
我们前面都是每两个结点抽一个结点到上级索引,如果我们每三个结点或五个结点,抽一个结点到上级索引,是不是就不用那么多索引结点了呢?我画了一个每三个结点抽一个的示意图,你可以看下。
从图中可以看出,第一级索引需要大约 n/3 个结点,第二级索引需要大约 n/9 个结点。每往上一级,索引结点个数都除以 3。为了方便计算,我们假设最高一级的索引结点个数是 1。我们把每级索引的结点个数都写下来,也是一个等比数列。

通过等比数列求和公式,总的索引结点大约就是 n/3+n/9+n/27+…+9+3+1=(n-1)/2。尽管空间复杂度还是 O(n),但比上面的每两个结点抽一个结点的索引构建方法,要减少了一半的索引结点存储空间。
实际上,在软件开发中,我们不必太在意索引占用的额外空间。在讲数据结构和算法时,我们习惯性地把要处理的数据看成整数,但是在实际的软件开发中,原始链表中存储的有可能是很大的对象,而索引结点只需要存储关键值和几个指针,并不需要存储对象,所以当对象比索引结点大很多时,那索引占用的额外空间就可以忽略了。
我们现在来看下, 如何在跳表中插入一个数据,以及它是如何做到 O(logn) 的时间复杂度的?
我们知道,在单链表中,一旦定位好要插入的位置,插入结点的时间复杂度是很低的,就是 O(1)。但是,这里为了保证原始链表中数据的有序性,我们需要先找到要插入的位置,这个查找操作就会比较耗时。
对于纯粹的单链表,需要遍历每个结点,来找到插入的位置。但是,对于跳表来说,我们讲过查找某个结点的的时间复杂度是 O(logn),所以这里查找某个数据应该插入的位置,方法也是类似的,时间复杂度也是 O(logn)。我画了一张图,你可以很清晰地看到插入的过程。
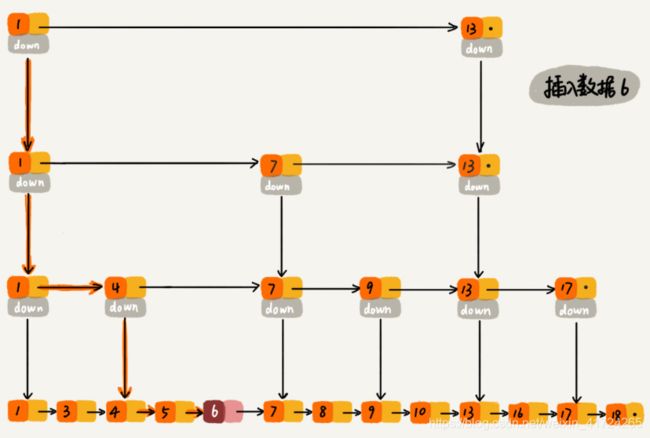
好了,我们再来看删除操作。
如果这个结点在索引中也有出现,我们除了要删除原始链表中的结点,还要删除索引中的。因为单链表中的删除操作需要拿到要删除结点的前驱结点,然后通过指针操作完成删除。所以在查找要删除的结点的时候,一定要获取前驱结点。当然,如果我们用的是双向链表,就不需要考虑这个问题了。
作为一种动态数据结构,我们需要某种手段来维护索引与原始链表大小之间的平衡,也就是说,如果链表中结点多了,索引结点就相应地增加一些,避免复杂度退化,以及查找、插入、删除操作性能下降。
跳表是通过随机函数来维护前面提到的“平衡性”。
当我们往跳表中插入数据的时候,我们可以选择同时将这个数据插入到部分索引层中。如何选择加入哪些索引层呢?我们通过一个随机函数,来决定将这个结点插入到哪几级索引中,比如随机函数生成了值 K,那我们就将这个结点添加到第一级到第 K 级这 K 级索引中。
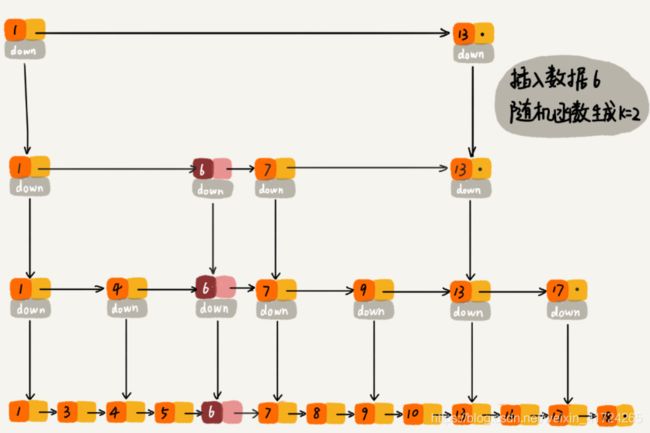
随机函数的选择很有讲究,从概率上来讲,能够保证跳表的索引大小和数据大小平衡性,不至于性能过度退化。至于随机函数的选择,我就不展开讲解了。(即不需要掌握)