ubuntu+yolov4训练自己的数据集
论文题目:YOLOv4: Optimal Speed and Accuracy of Object Detection
文献地址:https://arxiv.org/pdf/2004.10934.pdf
源码地址:https://github.com/AlexeyAB/darknet
今天,使用YOLOv4对进行目标检测,将自己的训练过程记录下来,总的来说,和之前Darknet的YOLOv3版本的操作完全相同。
环境
Ubuntu 16.04
Python: 3.6.2
OPENCV:2.4.9.1
CUDA: 9.0
GPU: GTX1050Ti
首先下载代码:
git clone https://github.com/AlexeyAB/darknet.git由于都是AlexeyAB大神的杰作,在使用上与YOLOv3使用过程几乎相同。
1. 编译make
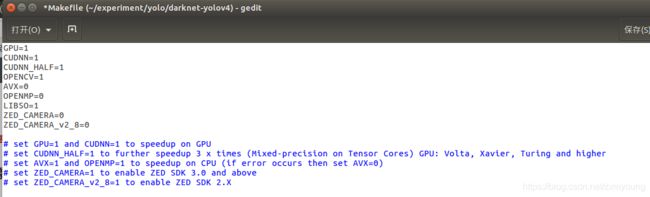
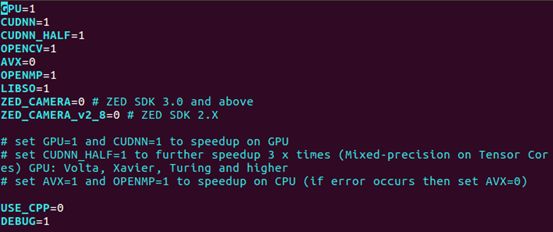
如果硬件设备包含GPU加速,需要对makefile文件进行修改,修改后如下图所示。
训练肯定需要使用GPU加速,那么得打开项目里面的makefile文件修改一些参数的值,
1-4、7行中的0改为1
makefile前面几行:打开GPU 加速,打开opencv,打开libdarknet.so生成开关
或
然后在终端进行编译:
# cd到darknet文件夹下:
make # 或make -j8
2. 下载开源权重,并测试:
yolov4.weights: https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov4.weights
yolov4.conv.137: https://drive.google.com/open?id=1JKF-bdIklxOOVy-2Cr5qdvjgGpmGfcbp
下载后放在主目录下
使用与训练的权重进行测试:
./darknet detect cfg/yolov4.cfg yolov4.weights data/dog.jpg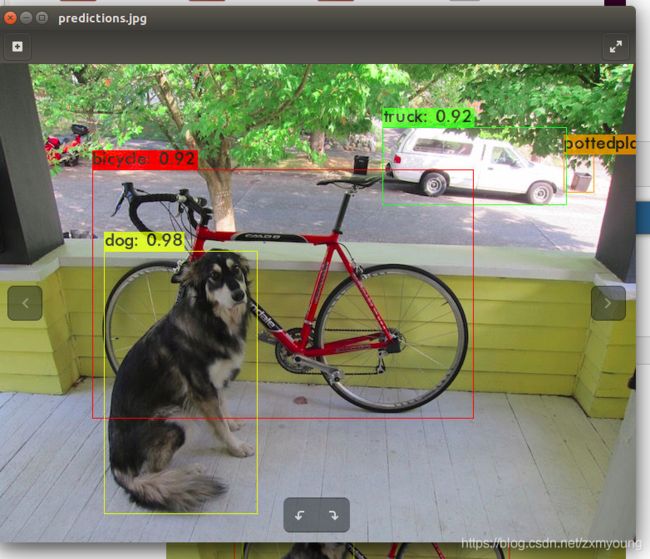
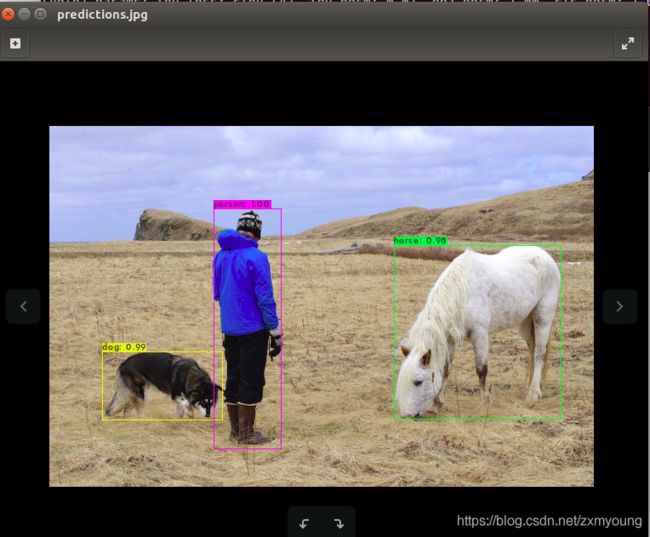
成功则在主目录下出现predictions.jpg 图片为预测后的图片,打开 OPENCV=1的可以直接显示出图片。说明我们的环境配置好了,否则先去配置环境。
3. 训练自己的数据集
3.1 数据集制作
构建与YOLOv3相同的数据文件夹(此处仍以YOLOv3的方式构建):
在根文件夹下按如下目录创建VOCdevkit 文件夹,放自己的训练数据。
VOCdevkit --VOC2007 ----Annotations #(放XML标签文件) ----ImageSets ------Main ----JPEGImages # (放原始图片)
中:
- Anontations用于存放标签xml文件
- JPEGImage用于存放图像
- ImageSets内的Main文件夹用于存放生成的图片名字,例如:
3.2. 准备YOLOv4需要的label和txt
首先,从路径为"./scripts"文件夹下有voc_label.py,复制到VOCdevkit 文件夹同等级下,打开后修改自己的类别信息,,并对其内容进行修改。
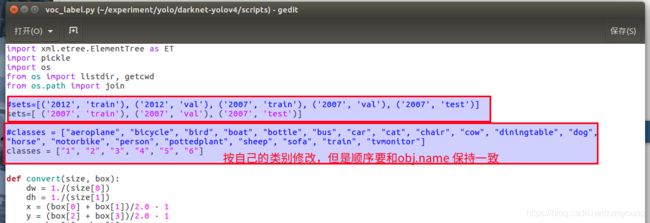
其中,#后为注释掉的为原先的,未被注释掉的是修改后的,sets中为年份(VOC后的数字,例如VOC2007中的2007)和包含的数据集(Main文件夹中划分数据集的txt的种类),classes中填写标注文件中包含的待识别物体的类别标签。
然后将所有出现的 VOCdevkit修改为 相应的路径 ,因为我的目录是voc_label.py在VOCdevkit 文件夹同等级下 ,所以不需要对相关文件的路径进行修改,其他修改内容如下(这里根据你们的数据集更改 要求找到对应的目录就可以了)
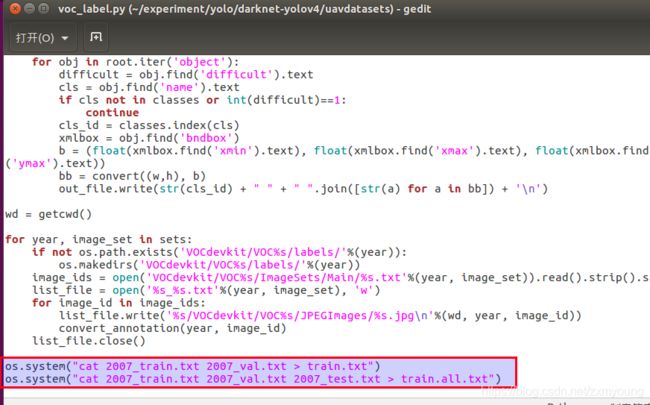
执行voc_label.py,在同等级目录下将会生成训练需要的文件,即各个训练集中包含图像的路径。
![]()
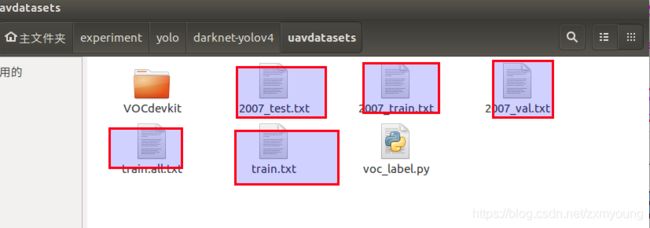
3.3 在主目录下创建yolo-obj.cfg 配置文件。将 yolov4-custom.cfg 中的内容复制到 yolo-obj.cfg里面,并做以下修改。
yolov4-custom.cfg 参数说明及调参经验:https://zhuanlan.zhihu.com/p/91587361
https://zhuanlan.zhihu.com/p/114530609
--3.3.1修改batch=64,修改subdivisions=32(如果显卡是1050TI的,可以把batch设置为96,如果报内存不足,将batch改回64将,或者subdivisions设置为32)
--3.3.2修改max_batches=classes*2000 例如有2个类别人和车 ,那么就设置为4000,N个类就设置为N乘以2000,
--3.3.3修改steps为80% 到 90% 的max_batches值 比如max_batches=4000,则steps=3200,3600
--3.3.4修改classes,先用ctrl+F搜索 [yolo] 可以搜到3次,每次搜到的内容中 修改classes=你自己的类别 比如classes=2
--3.3.5修改filters,一样先搜索 [yolo] ,每次搜的yolo上一个[convolutional] 中 filters=(classes + 5)x3 比如filters=21
--3.3.6(可以跳过)如果要用[Gaussian_yolo] ,则搜索[Gaussian_yolo] 将[filters=57] 的filter 修改为 filters=(classes + 9)x3 (这里我没用到,但是还是修改了)
3.4制作obj.names
在build\darknet\x64\data\ 文件夹下创建obj.names文件。内容为你的类别 比如人和车 那么obj.names 为如下
person car
3.5制作obj.data
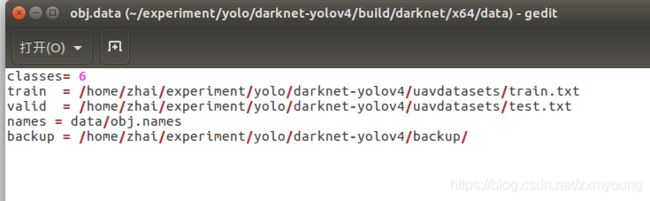
在build\darknet\x64\data\文件夹下创建obj.data文件。内容如下
classes= 2 train = data/train.txt valid = data/test.txt #做测试用的测试txt,(voc_label.py生成的) names = data/obj.names #类别标签名称,找不到的话,修改为自己的绝对路径 backup = backup/ #权重存放位置
我在这读取不到相对路径下文件 所以改为绝对路径 就可以了 这是我的obj.data文件
3.6 开始训练
./darknet detector train build/darknet/x64/data/obj.data yolo-obj.cfg yolov4.conv.137 -map如果要使用gpu的话输入以下
./darknet detector train build/darknet/x64/data/obj.data yolo-obj.cfg yolov4.conv.137 -gpus 0 -map#若训练2000此后在之前训练的基础上继续训练(适合中途停止后继续训练)
./darknet detector train build/darknet/x64/data/obj.data yolo-obj.cfg backup/yolo-obj_2000.weights -gpus 0 -map在训练过程中,与之前yolov3不同的是yolov4在训练过程中会弹出训练过程中的loss的实时图像,如下图所示,会动态的显示每一代的损失,当前代数和预计剩余时间。
出现问题:
报错 CUDA status Error: file: ./src/dark_cuda.c : () : line: 373 CUDA Error: out of memory CUDA Error: out of memory:
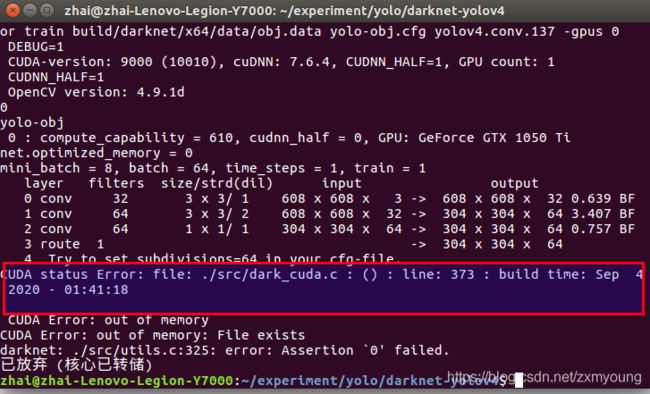
解决方法:参考:https://edu.csdn.net/course/play/28745 的问题中的回复
降低batch和subdivisions都设为16;然后把cfg文件中的width和height减小(但要是32的倍数,我的是416,416)直到能训练。
如下
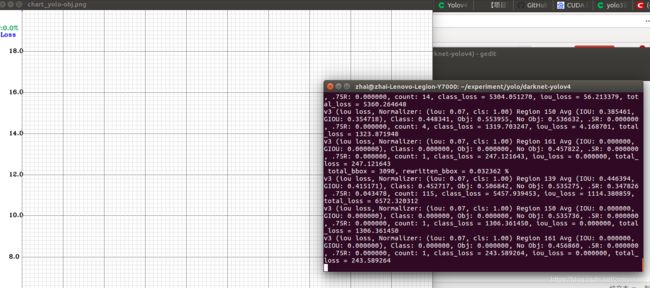
对于下图,值得一提的是起初loss在图像上看到的是平的,并不是意味着损失不下降,只是loss相对与18.0而言都太大了,在固定坐标的图像上难以显示,因此可视化的是平的。

3.7. 预测
预测指令:
./darknet detector test build/darknet/x64/data/obj.data yolo-obj.cfg backup/yolo-obj_xxxx.weights 然后在提示的Enter Path中输入待测图像的路径。如下图所示。
参考map图
./darknet detector map obj.data yolo-obj.cfg backup/yolo-obj_final.weights
参考:
https://www.cnblogs.com/monologuesmw/p/13035442.html
https://my.oschina.net/u/4321806/blog/4470154
https://www.cnblogs.com/bob-jianfeng/p/12888111.html