Spark源码解析(一):运行架构
目录
- 1 总体介绍
- 2 脚本提交流程
- 3 重要类介绍
- 4 yarn-client模式源码分析
-
- 4.1 整体流程
- 4.2 源码分析
-
- 第一阶段:org.apache.spark.deploy.yarn.Client的创建
- 第二阶段:ApplicationMaster的创建到Executor的启动
- 第三阶段:Executor的注册与任务执行
- 5 yarn-cluster模式源码解析
-
- 5.1 整体流程
- 5.2 源码分析
- 6 yarn-client与yarn-cluster的比较
1 总体介绍
本文基于spark2.1.0版本的源码讲解
Spark的运行模式多种多样,灵活多变,部署在单机上时,既可以用本地模式运行,也可以用伪分布模式运行,而当以分布式集群的方式部署时,也有众多的运行模式可供选择,这取决于集群的实际情况,底层的资源调度即可以依赖外部资源调度框架,也可以使用Spark内建的Standalone 模式。对于外部资源调度框架的支持,主要以Yarn进行讲解。
- 单机:local模式、local-cluster(伪分布式)
- 集群:根据是否依赖外部调度框架又分为两大类
- Spark内建:Standalone模式,又分为client和cluster两种部署模式
- 外部调度框架:Mesos模式,yarn模式等,其中yarn又分为client模式和cluster模式
Spark内核架构中重要的组件包括:Application,SparkSubmit,Driver,Master,Worker,SparkContext,Executor,Job,Task,DAG等。
spark程序中各个角色的作用:
- ApplicationMaster:向集群管理器ResourceManager(yarn模式下)注册并且申请资源
- SparkContext:是整个spark应用的上下文,也整个spark应用的生命周期
1、加载配置文件SparkConf,创建SparkEnv,创建TaskScheduler、DAGScheduler
2、用于创建RDD、累加器、广播变量,获取应用的当前状态等 - Driver:spark应用的驱动程序,执行用户main方法,创建sparkConext
- Executor:执行具体任务的进程

注意:在standalone模式下,Spark有显示创建Driver(DriverInfo),Master,Work
类,事实上在基于Yarn模式下,并没有Master,在client模式下是ExecutorLauncher,cluster模式下是ApplicationMaster来充当Master实现资源调度。也没有Worker,而是CoarseGrainedExecutorBackend进程,在这个进程中会注册Executor,只是习惯称Executor运行的节点是Worker。同样,我们称SparkContext的初始化地方叫做Driver。
2 脚本提交流程
当我运行下图这样一个脚本时,通过spark-submit提交应用,它是怎么执行到我们写的代码的呢?

spark-submit脚本位于[SPARK_HOME]/bin目录下,内容如下(注意org.apache.spark.deploy.SparkSubmit这个参数,其实它才是任务提交的真正入口):

实际它执行了spark-class脚本,里面有这样一段代码:

其实是启动了org.apache.spark.launcher.Main这个主类。
在这个类的main方法中会去初始化SparkSubmitCommandBuilder,然后调用buildSparkSubmitCommand()方法生成cmd命令,其实就是生成了一个java脚本。
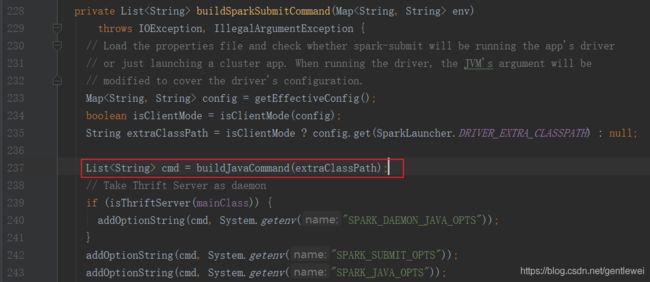
这些命令传回spark-class脚本,通过exec命令执行:
![]()
其实就是又启动了一个java进程,主类就是前面传入的参数org.apache.spark.deploy.SparkSubmit
SparkSubmit类的作用:它是启动Spark应用程序的主网关,该程序处理Spark依赖项的类路径的设置,并在Spark支持的不同集群管理器和部署模式上提供一个统一控制层。
接下来开始执行SparkSubmit的main方法,它会初始化一个SparkSubmitArguments类,对提交的参数进行解析、封装、校验,然后调用submit方法开始提交应用

重点看prepareSubmitEnvironment()方法

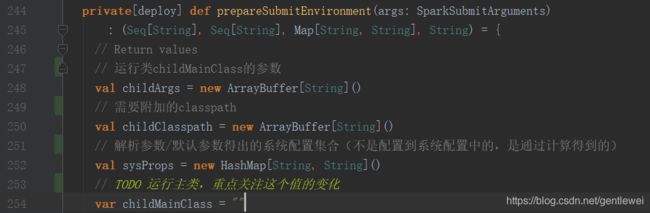

这里尤其要注意的是mainClass的变化,这决定着不同的模式有不同的初始化方式



prepareSubmitEnvironment()执行完后,调用runMain()方法提交
![]()

![]()
最终通过反射启动主类

至此,应用提交的第一阶段完成,接下来会根据不同的部署模式,走不同的主类去初始化SparkContext、AM、启动Executor等。

- 如果是client模式(yarn或者standalone),会通过反射直接执行用户程序的main方法,然后初始化sparkContext,接着创建ApplicationMaster。
- 如果是yarn-cluster模式,会走org.apache.spark.deploy.yarn.Client的run()方法,然后走createContainerLaunchContext()方法,接下来启动org.apache.spark.deploy.yarn.ApplicationMaster这个类的主方法,然后走ApplicationMaster.startUserApplication()方法,最终也是通过反射执行用户代码中的main方法,然后开始sparkContext的初始化工作
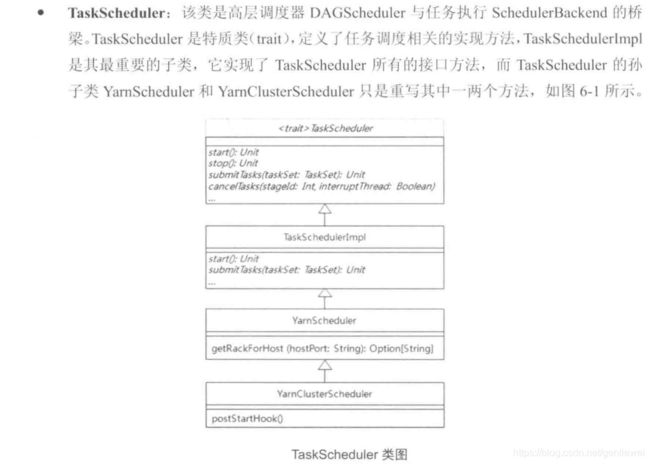
3 重要类介绍



4 yarn-client模式源码分析
4.1 整体流程
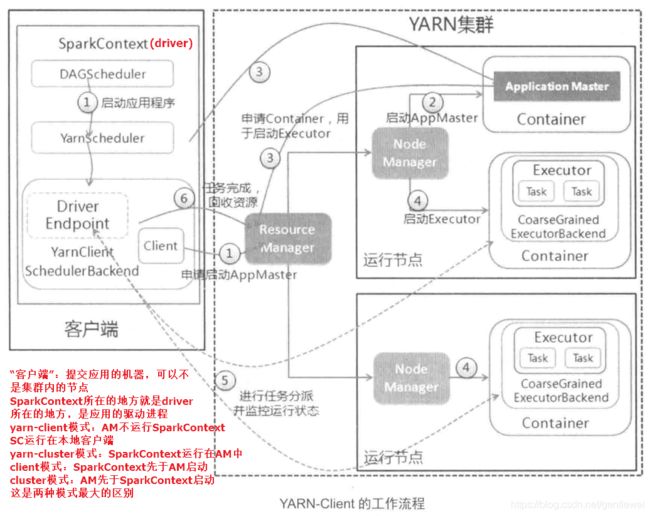

注意:yarn-cluster模式下,driver运行在AM(Application Master)中,它负责向YARN申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉Client,作业会继续在YARN上运行。然而yarn-cluster模式不适合运行交互类型的作业。而yarn-client模式下,driver运行在本地,Application Master仅仅向YARN请求executor,client会和请求的container(executor)通信来调度他们工作,也就是说Client不能离开。本地client端能够显示应用打印的结果。
4.2 源码分析
这里主要看sparkContext是如何启动ApplicationMaster的,然后AM是如何启动executord的 。至于sparkContext的源码,后面单独写一篇文章解析。
先看一张图,整体了解下各个类是如何相互调用的:

第一阶段:org.apache.spark.deploy.yarn.Client的创建
以org.apache.spark.deploy.yarn.Client的创建为分界点(我自己这样划分的),这个阶段的工作主要是任务调度器的创建,driverEndpoit的创建,以及yarn客户端的创建,建立与yarn集群的连接。
首先启动SparkContext,在createTaskScheduler方法中,当匹配为yarn-client模式时,返回YarnScheduler,YarnClientSchedulerBackend两个对象。其中YarnScheduler是TaskSchedulerImpl的子类,YarnClientSchedulerBackend是CoarseGrainedSchedulerBackend的孙子类。TaskSchedulerImpl会持有YarnClientSchedulerBackend的引用。当执行_taskScheduler.start()时,会调用CoarseGrainedSchedulerBackend.start()方法启动driverEndpoint(用于提交task到executor并接收返回结果)。
首先进入 SparkContext.createTaskScheduler()方法内部:
getClusterManager()方法的实现,是先调用ServiceLoader.load()方法创建所有org.apache.spark.scheduler.ExternalClusterManager的子类实例(通过反射创建),然后过滤出“yarn”模式对应的实例。
![]()
ServiceLoader内部实现:

YarnClusterManager中canCreate方法的实现
YarnClusterManager中两个create方法的实现

SparkContext中执行cm.initialize(scheduler, backend)时,其实调用的是TaskSchedulerImpl.initialize()方法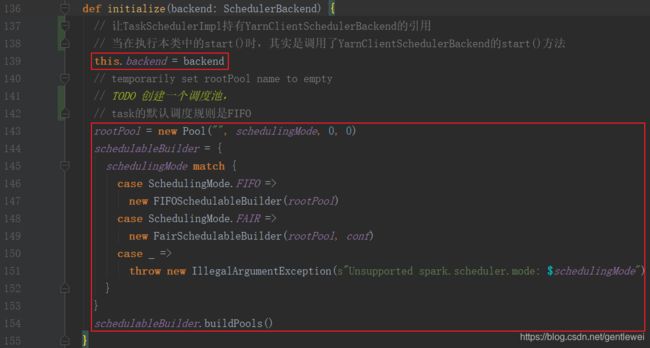
关于调度规则的源码分析,请看这里:Spark调度模式-FIFO和FAIR
接下来在SparkContext中执行_taskScheduler.start(),其实是执行了TaskSchedulerImpl.start()方法,然后调用了YarnClientSchedulerBackend.start()方法,创建了org.apache.spark.deploy.yarn.Client对象,并且调用CoarseGrainedSchedulerBackend.start()方法创建了driverEndpoint对象。最后调用Client.submitApplication()申请启动ApplicationMastor。

TaskSchedulerImpl中的start()方法

YarnClientSchedulerBackend中start()方法的实现
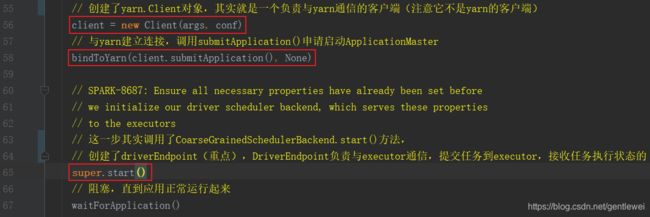
CoarseGrainedSchedulerBackend.start()方法实现 

第二阶段:ApplicationMaster的创建到Executor的启动
创建好org.apache.spark.deploy.yarn.Client对象后,调用submitApplication()方法开始申请启动ApplicationMaster。
首先进入org.apache.spark.deploy.yarn.Client.submitApplication()方法,初始化yarnClient:

对RM的第一次请求,申请创建Application



进入createContainerLaunchContext()这个方法,可以看到不同模式下启动的ApplicationMaster的类名:

最终提交应用给ResourceManager:

当ResourceManager收到请求后,在集群中选择一个NodeManager启动ExecutorLauncher:
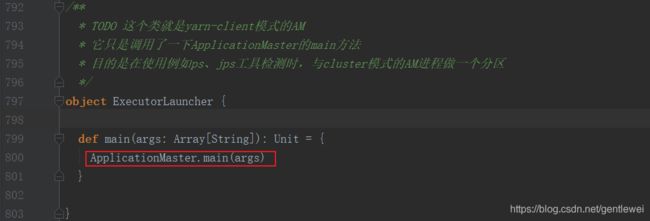

进入run()方法:

registerAM()方法真正开始注册AM

registerAM()内部实现:


![]()
接下来进入YarnAllocator..allocateResources()方法分配可用的Container,然后调用handleAllocatedContainers(),再调用runAllocatedContainers(),这个方法内部会调用ExecutorRunnable.run()方法,然后通过prepareCommand()来构建启动Exector的Linux命令,最后通过命令启动CoarseGrainedExecutorBackend(Executor进程)

![]()

然后进入ExecutorRunnable.run()方法:



最后通过yarn来完成executor的启动:

至此,yarn-client模式从spark-submit命令提交任务到executor启动完成的整个流程结束。
第三阶段:Executor的注册与任务执行
Executor启动起来后,会执行CoarseGrainedExecutorBackend.main()方法,然后向driver注册Executor,完成后,等待driver发送task来执行具体的任务。
由于CoarseGrainedExecutorBackend继承了ThreadSafeRpcEndpoint,它可以通过Rpc框架向其他Rpc终端点发送消息。它会拿到driverEndpoint的引用,向driver发送注册Executor的消息。
执行CoarseGrainedExecutorBackend.onStart()方法,开始注册Executor

DriverEndpoint收到注册请求:

如果条件满足,开始注册Executor

CoarseGrainedExecutorBackend收到DriverEndpoint发送的Executor注册成功消息,在CoarseGrainedExecutorBackend内部实例化一个Executor对象(真正的任务执行者),它会定时向driver发送心跳,等待driver下发任务。
CoarseGrainedExecutorBackend处理注册成功代码:

Executor内部向driver发送心跳的代码:
![]()

CoarseGrainedExecutorBackend的Executor启动后,接收从DriverEndpoint发送LaunchTask执行任务消息,任务执行是在Executor.launchTask()方法实现的。在执行时会创建TaskRunner线程来执行任务,任务执行完成后向DriverEndpoint发送StatusUpdate消息汇报任务状态。
CoarseGrainedExecutorBackend中代码如下:


TaskRunner内部代码:

向driver发送StatusUpdate代码:

DriverEndpoint收到StatusUpdate消息后的处理如下:

至此,整个应用提交、任务执行的流程就完整了。接下来的重点是任务的执行详细流程,
这一部分流程client与cluster模式是完全一样的,整体流程如下图,具体的源码分析后面会专门写一遍文章。

5 yarn-cluster模式源码解析

5.1 整体流程


5.2 源码分析
先从整体看下各类是如何调用的

从本文第二点“脚本提交流程”可知,任务提交后,会执行SparkSubmit.runMain()方法,通过反射的方式执行不同主类的main方法(主类名是SparkSubmit.prepareSubmitEnvironment()方法中根据不同的部署模式匹配的childMainClass的值)。
由此可知,yarn-cluster模式执行是的org.apache.spark.deploy.yarn.Client的main方法。
在main()方法中,调用了Client.run()方法,接着调用了Client.submitApplication()(其实yarn-client模式也是调用这个方法来提交应用)

接着进入createContainerLaunchContext()方法内部,可以看到yarn-cluster模式启动的是org.apache.spark.deploy.yarn.ApplicationMaster

ResourceManager收到YarnClient发送的请求后,选择一个合适的NodeManager启动ApplicationMaster。接着执行ApplicationMaster的main方法,然后跳转到ApplicationMaster.run()方法中,

run()方法首先执行了用户的main方法,初始化了SparkContext

进入startUserApplication()方法内部,可以看到创建了线程,通过反射的方式执行用户代码的main方法来初始化SparkContext

执行完startUserApplication()方法后,开始注册AM,从这里开始一直到CoarseGrainedExecutorBackend启动的流程,与yarn-client模式是一样的。

看到这里,我有一个疑问:yarn-cluster模式是从Client.submitApplication()到ApplicationMaster,接着ApplicationMaster.startUserApplication()方法会执行用户main方法,初始化SparkContext,执行SparkContext内部的_taskScheduler.start()时,会不会和yarnt-client模式一样又跳到Client.submitApplication()?这不就形成一个循环了吗?
答案是不会。
差别在于两者执行val (sched, ts) = SparkContext.createTaskScheduler(this, master, deployMode)方法时返回的SchedulerBackend的实现不一样:

当执行SparkContext里的_taskScheduler.start()时,其实走的不同SchedulerBackend的start()方法:
yarn-client模式:走的YarnClientSchedulerBackend.start()方法,这个方法内部创建了一个Client对象,并调用了Client.submitApplication()来提交应用。

yarn-cluster模式:走的YarnClusterSchedulerBackend.start()方法,这个方法内部并没有创建client,所以不会又回到Client.submitApplication()。(走到这里本来就是从Client.submitApplication()方法过来的)。所以不会形成循环。

6 yarn-client与yarn-cluster的比较
