ET和LT的原理和区别
前言
学习自用,有错麻烦提出
基本知识
ET是一次事件只会触发一次,如一次客户端发来消息,fd可读,epoll_wait返回.等下次再调用epoll_wait则不会返回了
LT是一次事件会触发多次,如一次客户端发消息,fd可读,epoll_wait返回,不处理这个fd,再次调用epoll_wait,立刻返回,
LT和ET的内部实现
对于epoll,每次返回会有个ready list,以下参考自[1],不同于select,epoll是采用回调的机制来把fd加进ready_list中的,(后面有提到),select是依赖于文件系统file_operation的poll操作,通过调用驱动的__pollwait(),在这个函数里设置好回调等待唤醒(这个有点不太确定,驱动函数的_poll看不太懂)
对于ET和LT模式,两者只在epoll_wait函数里有不同,因为epoll是基于回调的,在epoll_wait里进行的操作不多,只是检查现在的ready list情况,即调用_poll函数来判断ready list上的fd是否确实有事件(来自参考资料[9]), 同时检查每个fd是否是非EPOLLET的,即是否是LT模式,,,LT模式的fd则留在ready list中,等下次调用epoll_wait的时候会在此poll检查,ET模式的fd返回用户态后则删去
注意这里,由于内核对用户态的不信任,内核态和用户态的传输数据总是拷贝的
以上可看出,ET比LT的高效点在于这里,论单纯的ET和LT调用的开销很容易看出ET较为高效,而若要算上应用层开销复杂度,则另当别论,即ET和LT的哪个更高效要分应用场景讨论
LT和ET的应用场景和使用方法
使用方法
ET要与非阻塞fd一起使用,因为ET一次事件只触发一次,所以epoll_wait返回后一定要处理完毕,对于可读事件,要一直read fd到此fd被read完为止,而如果设置成blocking以后,fd上的数据read完后会阻塞,即while{epoll_wait(); read(fd)}这段代码会一直阻塞而影响重新调用epoll_wait来监听其他事件,正确做法是设置fd成non_blocking,且epoll_wait返回后吧事件read到EAGAIN为止,注意这里只是单线程下(不过哪怕是用线程池,线程池中线程阻塞了也进行不了其他任务)
LT可搭配非阻塞也可搭配阻塞使用
应用场景
LT的编程会比ET的编程更简洁的场景
对于可读事件,ET模式下的编程需要read到EAGAIN位置,发来的数据量多且并发量大的时候,还可能造成其他事件的饥饿,需要在应用层再额外代码以保证及时响应,而LT可直接每个消息事件read固定大小以保证每个连接公平(不管是单线程还是多线程模型),数据量大的且没读完的下次还会继续触发;另外如果是epoll_wait监听listen fd->处理新连接的流程,新连接个数
(ET用应用层维护的例子TODO)
对于写事件,ET会实现更简单高效,例子:
要write1M数据,而缓冲区只有2kb,则需要epoll_wait() 可写事件EPOLLOUT,对于ET模式,等写完后则直接就可以了
而如果是LT模式对付这样场景,在写完后,需要再调用一次epoll_ctl来删去EPOLLOUT事件,否则下次调用epoll_wait还是会继续触发返回可写事件,具体代码可看参考资料[4]中文末位置的链接
可以看出,对于EPOLLOUT可写事件,用ET更高效
上面讲的可读事件和可写事件分别用LT和ET的代码实验,可见参考资料[5]
服务器场景
对于服务器编程,要处理三个半事件,这里先讲可读和连接到来事件.并讲下缓冲区满的可写事件
muduo所使用的连接到来事件(acceptor)是LT,对于消息到来(poller)也是LT模式..先不讨论为什么这么设计,因为陈硕还有其他要考虑的方面TODO
而Nginx,listen fd用的是LT来监听,connection fd用的是ET来监听,做实验这样组合并发度最高
listen fd用LT的原因:来自[7],若使用ET(边缘触发)模式,则非常可能有两个连接请求因为太靠近,而只accept()了其中一个(why,这是用户bug还是系统API的bug??)
此博客原话:这种情况要不就修改为LT,要不就继续ET模式,但listen socket为NOBLOCK模式。 accept()不断接收,直到返回 EAGAIN or EWOULDBLOCK。
connection socket用LT并发量高的原因:(TODO)
另外ET和LT哪个更高效的讨论见参考资料[8]中评论的连接,评论中都是讨论,以后有时间再总结吧..TODO
epoll的重要结构
主要来源于参考资料[6]和[1]
eventpoll结构是epoll的核心数据结,有三个字段是比较重要的,分别是:wq、rdllist和rbr。
红黑树rbr,功能:维护监听的fd和事件,方便添加删除时间复杂度都是logn水平,用来检查的fd添加是否重复;结构:key是fd,value是epitem结构
双向链表rdllist就是上面说的双向链表,用于记录已发生的事件,并传输给应用层,,readylist中每个节点也是epitem(来自参考资料[10]),
wq用于保存有哪些进程在等待这个epoll返回。即等待队列
LT和ET的区别里就多了一步把设置了LT模式的fd留在rdllist的操作
epoll的重要函数
总览:epoll之所以高效是因为它是基于回调的,epoll_ctl是用来注册来消息时的回调函数,并用等待队列也就是上面说的wq来实现进程睡眠在此设备上
epoll_wait流程:因为是基于回调的,epoll_wait做的只是检查readylist,每个调用驱动的poll函数检查一遍是否确实有可读/可写,接着判断fd是否是EPOLLET模式,不是则将它重新放回readylist中供下次调用epoll_wait再来检查,然后把readylist调用返回给用户态
epoll_ctl流程:设置某个事件如网卡有数据的事件处理回调函数为添加fd到readylist
return_type epoll_ctl(epoll_event,fd) //省略类型
{
res = rbtree.find(fd);
if(res != rbtree.end() ) return;
rbtree[fd]=对应结构;
设置事件回调函数(如连接到来事件,消息到来事件)为添加事件fd到readylist
}epitem的封装:事件类型,fd
事件到来的回调函数:将epitem添加到readylist中
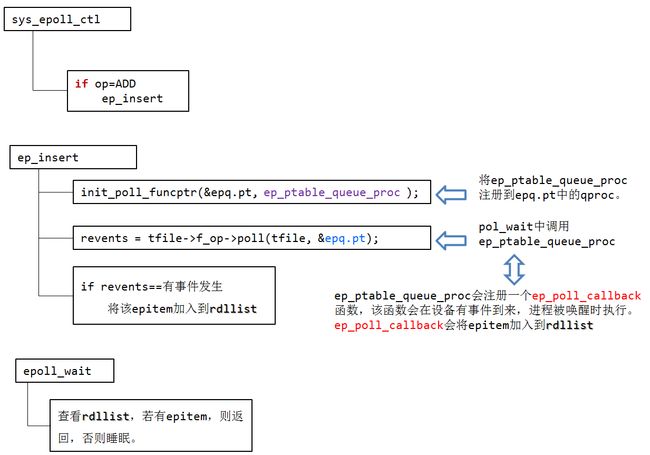
epoll底层实现
回调的实现:会把本进程放在设备里的一个队列里睡眠,当设备监测到信号的时候,就会唤醒这个队列里的进程(这就和锁的实现差不多啊)
确切的来说,epoll将事件注册到了内核中的红黑树上面,当事件状态发生改变的时候,将改变的状态插入到双向链表中(在内核里面),当内核通过对双向链表的遍历,可以探索是否有状态发生变化,如果有则将双向链表中的节点搬迁到内核外面。相比较于select省去了将数组搬迁到内核,以及在内核中遍历数组,和将遍历结果拷贝到用户态。而且select使用的是数组的遍历查找状态的改变进而使用位操作函数,epoll通过红黑树查找,是通过事件注册可以检测出是读事件,写事件,还是异常事件。当有大量连接但是其中只有一少部分处于活跃状态就会影响到性能,epoll可以处理高并发理论上连接没有限制,注意使用的时候有一个惊群问题,epoll的工作模式又分为水平触发和边沿触发,默认情况下使用水平触发通俗理解为可以读多次数据,边沿触发理解为只能读一次一次把数据读完,既然是一次读完会不会存在阻塞式读取呢?当然可以选择使用不阻塞读取防止出现阻塞读取而影响后续的任务安排,select使用数组记录事件,连接之前已经有确切的事件范围。
select的缺点
- 第一个是每次调用select需要用户态和内核态的复制,要知道用户-内核空间的内存拷贝是非常昂贵的
- 第二个是select是无状态的,每次select调用内核态都要检查一遍(epoll不用吗),且fd数组按照监听的事件分为了3个数组(是哪三个啊)
- 返回的时候返回所有fd,需要用户态遍历看哪些发生了事件
select的实现
select会经过一个系统调用进入内核态,并传入要监听的fd list,内核的系统调用会调用驱动程序的轮询函数poll(不是用户态那个poll),无限循环for(;;)直到有消息到来,并wake相应的程序
select和epoll
前面说了epoll之所以高效是因为它基于回调,
而select则是基于轮询,对于每个select()调用,会把监听的fd传入内核中,内核再一个个轮询注册回调(而epoll是用epoll_ctl提前注册),另外select返回的时候要返回所有监听的fd,返回到用户态后,应用层要自己再轮询一遍(为什么不直接返回发生事件的fd呢)
为什么连接少又活跃的时候应该选择select而不是epoll,是什么实现原理导致的呢?原因如下(来自参考资料14)
select和poll即使只有一个描述符就绪,也要遍历整个集合。如果集合中活跃的描述符很少,遍历过程的开销就会变得很大,而如果集合中大部分的描述符都是活跃的,遍历过程的开销又可以忽略。epoll的实现中是基于回调的,无需遍历,如果是LT,也只用遍历先前活跃的描述符,在活跃描述符较少的情况下就会很有优势,在代码的分析过程中可以看到epoll的实现过于复杂并且其实现过程中需要同步处理(锁),如果大部分描述符都是活跃的,epoll的效率可能不如select或poll
参考资料
- [1](https://www.cnblogs.com/charlesblc/p/6242479.html)
- [2](https://www.zhihu.com/question/20502870)
- [3](https://www.zhihu.com/question/47002053)
- [4](https://www.zhihu.com/question/20502870/answer/89738959)
- [5]https://www.zhihu.com/question/47002053/answer/794254562
- [6](https://zhuanlan.zhihu.com/p/63179839)
- [7](http://blog.sina.com.cn/s/blog_602f87700102y2ob.html)
- [8](http://www.cppblog.com/Leaf/archive/2013/02/25/198061.html)
- [9](https://www.cnblogs.com/bbqzsl/p/7060819.html)ET的底层实现
- [epoll深层分析](https://blog.csdn.net/daaikuaichuan/article/details/83862311)
- [selct源码](https://www.cnblogs.com/shuqin/p/11587182.html)
- [select源码分析](https://blog.csdn.net/zhougb3/article/details/79792089)
- https://my.oschina.net/fileoptions/blog/911091啊,select的源码,上面的图就是它的
- https://blog.csdn.net/lishenglong666/article/details/45536611
- https://www.cnblogs.com/apprentice89/p/3234677.html图,epoll的流程
- https://www.nowcoder.com/discuss/26226,epoll的源码解析
- https://mp.weixin.qq.com/s/8Udus40t2Srxsefart3e6g?啊epoll的重要结构
- https://www.jianshu.com/p/ef418ccf2f7d啊select和epoll的区别
- https://zhuanlan.zhihu.com/p/25241630下面的评论说select 的for(;;)是为了轮询状态改变
TODO
epoll所注册的异步回调,是另一个内核线程在调用驱动的poQll_wait轮询吗,否则怎么知道发生了上面说的epoll只用监听活跃的是什么意思?难道回调的只是把活跃的加进来,实际还要靠_poll_wait再重新判断?- rdllist说清楚
- https://zhuanlan.zhihu.com/p/30937065底层epoll的锁
-
挖坑的
https://zhuanlan.zhihu.com/p/64746509
https://zhuanlan.zhihu.com/p/50984245
https://blog.csdn.net/mcheaven/article/details/44257771
https://blog.csdn.net/tianjing0805/article/details/76021440