Memcache高可用群集
Memcache高可用群集
实验环境:
| 主服务器 | 192.168.45.132 | Telnet、libevent、memcached、keepalived、magent |
|---|---|---|
| 从服务器 | 192.168.45.131 | Telnet、libevent、memcached、keepalived |
| 测试机 | 192.168.45.135 | Telnet |
实验目的:
实现存储内容的主从备份
实验搭建:
一、主服务器:
1、挂载软件包,
#挂载软件包
mount.cifs //192.168.100.3/lzp /mnt
#创建目录
mkdir /opt/magent
#解压必要安装包
cd /mnt/mem
tar zxvf magent-0.5.tar.gz -C /opt/magent/
tar zxvf libevent-2.1.8-stable.tar.gz -C /opt
tar zxvf memcached-1.5.6.tar.gz -C /opt
#安装必要组件
yum install gcc gcc-c++ make -y2、对组件进行编译安装
#编译安装libevent
cd /opt/libevent-2.1.8-stable/
./configure --prefix=/usr
make && make install
#编译安装memcached
cd /opt/memcached-1.5.6/
./configure --with-libevent=/usr
make && make install
#编译安装magent
cd /opt/magent/
#修改ketama.h文件
vim ketama.h
#ifndef SSIZE_MAX
#define SSIZE_MAX 32767
#将#endif移动到第三行,删除掉末尾的
#endif
vim Makefile
#第一行末尾添加-lm
LIBS = -levent-lm
#编译
make#编译好的magent文件
3、将编译好的magent文件复制到/usr/bin目录下,并推送给从服务器
#安装openssh推送软件
yum install openssh-clients -y
#将编译好的magent文件复制到/usr/bin目录下
cp magent /usr/bin
#推送magent文件
scp magent [email protected]:/usr/bin
The authenticity of host '192.168.45.131 (192.168.45.131)' can't be established.
ECDSA key fingerprint is SHA256:bw2256OHr5apf7CliZv/fAOyVNVsMmRn+lZ5efeQgTg.
ECDSA key fingerprint is MD5:6f:f6:70:4f:46:64:ec:17:a7:ae:c0:15:1c:8b:55:1c.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '192.168.45.131' (ECDSA) to the list of known hosts.
[email protected]'s password:
magent 100% 112KB 5.8MB/s 00:00
4、关闭防火墙和安全功能
systemctl stop firewalld.service
setenforce 05、安装keepalived,并进行修改
#安装keepalived
yum install keepalived -y
#修改配置文件
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
#写入下列内容
vrrp_script magent {
script "/opt/shell/magent.sh"
interval 2
}
global_defs {
notification_email {
[email protected]
[email protected]
[email protected]
}
notification_email_from [email protected]
smtp_server 192.168.200.1
smtp_connect_timeout 30
#修改route-id
router_id MAGENT_HA
}
vrrp_instance VI_1 {
state MASTER
#修改网卡端口
interface ens33
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
#修改,调用上边函数
track_script {
magent
}
virtual_ipaddress {
#设置虚拟指向地址
192.168.45.188
}
}6、创建magent脚本
mkdir /opt/shell
cd /opt/shell/
vim magent.sh
#!/bin/bash
K=`ps -ef | grep keepalived | grep -v grep | wc -l`
if [ $K -gt 0 ];then
magent -u root -n 51200 -l 192.168.45.188 -p 12000 -s 192.168.45.132:
11211 -b 192.168.45.131:11211
else
pkill -9 magent
fi
#给于运行权限
chmod +x magent.sh7、启动服务,并查看
#启动keepalived
systemctl start keepalived.service
#查看迁移地址
ip addr
#启动memcached
memcached -m 512k -u root -d -l 192.168.45.132 -p 11211
安装telent进行测试
yum install telnet -y
二、从服务器
1、挂载软件包,并关闭防火墙和安全功能
mount.cifs //192.168.100.3/lzp /mnt
#关闭防火墙和安全功能
systemctl stop firewalld.service
setenforce 02、解压安装包,并进行编译
#解压安装包
cd /mnt/mem
tar zxvf libevent-2.1.8-stable.tar.gz -C /opt
tar zxvf memcached-1.5.6.tar.gz -C /opt
#安装必要组件包
yum install gcc gcc-c++ make -y
#编译安装libevent
cd /opt/libevent-2.1.8-stable/
./configure --prefix=/usr
make && make install
#编译安装memcached
cd /opt/memcached-1.5.6/
./configure --with-libevent=/usr
make && make install3、安装keepalived
#安装keepalived
yum install keepalived -y
#修改keepalived文件
cd /etc/keepalived/
mv keepalived.conf keepalived.conf.bk
vim keepalived.conf
! Configuration File for keepalived
vrrp_script magent {
script "/opt/shell/magent.sh"
interval 2
}
global_defs {
notification_email {
[email protected]
[email protected]
[email protected]
}
notification_email_from [email protected]
smtp_server 192.168.200.1
smtp_connect_timeout 30
#修改router_id
router_id MAGENT_HB
}
vrrp_instance VI_1 {
state BACKUP
#修改网络接口
interface ens33
#修改virtual_router_id
virtual_router_id 52
#修改优先级
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
track_script {
magent
}
virtual_ipaddress {
#修改地址
192.168.45.188
}
}4、创建magent脚本
mkdir /opt/shell
cd /opt/shell/
vim magent.sh
#!/bin/bash
K=`ip addr | grep 192.168.45.188 | grep -v grep | wc -l`
if [ $K -gt 0 ];then
magent -u root -n 51200 -l 192.168.45.188 -p 12000 -s 192.168.45.132:
11211 -b 192.168.45.131:11211
else
pkill -9 magent
fi
chmod +x magent.sh4、启动服务
#启动keepalived
systemctl start keepalived.service
#启动memcached
memcached -m 512k -u root -d -l 192.168.45.131 -p 11211
安装telent进行测试
yum install telnet -y
三、客户机
#关闭防火墙和安全功能
systemctl stop firewalld.service
setenforce 0
#安装telnet
yum install telnet -y
#在telnet中写入文件
[root@manager ~]# telnet 192.168.45.188 12000
Trying 192.168.45.188...
Connected to 192.168.45.188.
Escape character is '^]'.
add username 0 0 7
1234567
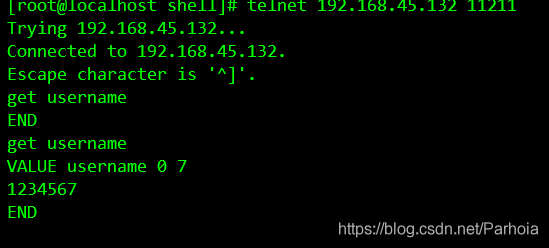
STORED在从服务器上查看
在主服务器上查看