ACL 2020最佳论文:一种全新的NLP模型测试方法CheckList
AI TIME欢迎每一位AI爱好者的加入!
前段时间,ACL 2020最佳论文奖的公布引起了轰动!这篇论文题为《Beyond Accuracy: Behavioral Testing of NLP Models with CheckList》,作者分别来自微软研究院、华盛顿大学、以及加州大学欧文分校。受到软件工程中行为测试的启发,研究者们提出了一种全新的 NLP 模型测试方法——CheckList,帮助人们更为清晰、系统地了解各种模型的优缺点。
本期AI Time PHD直播间,我们有幸邀请到该论文的二作,华盛顿大学博士吴彤霜同学,为大家分享这项研究工作!

吴彤霜,本科毕业于香港科技大学,目前在华盛顿大学读博士四年级,导师为Jeffrey Heer和Dan Weld。主要研究方向是通过结合人机交互的技术,来探索和改进自然语言处理模型的训练和评估步骤,最终帮助用户更有效、系统地与他们的模型进行交互。
背景:如何评估模型的好坏?
假设我们需要评估一个NLP分类模型、或者问答系统模型,大家想到的第一个指标很可能是:准确度!的确,accuracy或者F1这种标准度量十分常见。现在很多模型在GLUE、SuperGLUE这些知名的benchmark数据集上表现优异,准确率甚至超过人类水平。
然而,这种一键评估的方式,能暴露所有问题吗?

深入质询你的模型
如图,询问一个Visual Question Answering模型:图里的胡子是什么做的?模型回答:香蕉。如果单纯测accuracy,那么这里的表现满分。
但是,进一步深层次质询你的模型,你会发现图中什么都是“香蕉”做的!甚至当你已经不再问一个完整的问题了,模型仍然很固执地在回答“香蕉”!原因是,模型只看到你在问一个what问题,就狡猾地自动在图里找到一个显眼的物件返还给你。

模型这种类似走捷径或作弊的行为,也导致了很多其他的离谱现象。比如稍微扰动一下你的问题(多加一个问号),模型就不会数数了。

另一方面,对于不同问题,模型很可能给出相互矛盾的答案。这背后可能存在数据采样偏差或者建模的缺陷等等问题。

图:当你用不同的问法来问同一问题时,模型就会“犯傻”
提出模型测试的宏观方法
针对“我的模型能不能用”这个问题,该团队受到软件工程中最小单元测试和行为测试的启发,设计了一种独立于具体任务的NLP模型测试方法 — CheckList。
CheckList包含两个部分:一是帮助大家设计测试的流程框架,二是与框架配套的工具包。
一、CheckList 流程框架
CheckList给用户了可以用于多种任务的语言能力清单,用来指导用户去测试模型。
1)
性能清单
在软件工程的测试中,第一步应该是测试一些独立的最小单元组件,例如最基本的函数或类。类似地,NLP中的最小单元可以定义为:linguistic capability,即语言学性能。例如,区分词性、近反义词、语义角色等。

需要注意,这个性能清单是独立于nlp具体任务或模型存在的、一种泛化的对照目录。这是因为宏观来看,任何模型或任务都要具备理解词义、处理否定句等基本能力。
当然这是一个基础列表,是大部分任务的交集;有一些任务或应用场景需要使用者在这个基础上做拓展。
2)
脱钩的黑盒测试
从软工中借鉴的第二个原理就是行为测试(Behavioral Testing),又称黑盒测试。它的本质是抛开实现方法,只关注系统的输入输出行为是否符合预期。
转换到NLP,目标变成:把测试和模型设计/训练进行脱钩处理。
这种方式有两个好处:
一、符合用户需求。无论内在模型结构和训练数据如何,用户只关注模型是否适用于该应用场景。
二、符合当前nlp的黑盒发展现状,即使无法访问模型或训练数据,也一样可以进行测试。
3)
三种测试类型
除了前述的性能清单,CheckList也提供了三种测试类型,两者构成了二维测试矩阵,来实现这种脱钩测试。
下面以Google情感分析模型为例,介绍这三个测试类型。

a.最小功能测试(MFT)
最小功能测试(Minimum Functionality Test),和软工的单元测试基本对应。
大家知道,IMDb Movie Reviews中大部分测试数据都是尽可能复杂,有大量包含反讽、转折的复杂段落,来看模型能否跟上逻辑的跳跃。CheckList中的测试则反其道而行之,从零开始写一个足够简单但性能完备的小测试集,独立测试每个性能,杜绝模型走捷径的可能。
比如,针对情感分析模型能否理解重要单词的词义,专门写500条简单的测试实例,以及对应的预期标签,跑完模型后得到失败率(failure rate)。

这种化繁为简、从基础入手的方式,让我们回归对模型低级性能的关注。转而再去关心更高级的性能测试。
b.不变性测试(INV)
其他两个测试类型都是所谓的“扰动测试”。相对于MFT,它们有两大特征:
一、并非从零开始,而是以现存数据集为基础,进行修改;
二、预期不再是预测结果的正误,而是相对于原有数据,模型预测结果的变与不变。
不变性测试(INVariance Test),期待改写输入之后,模型的预测不变。
举一个专有名词的例子:如果做Twitter上航空公司评价的情感分析,改变行程的目的地,从芝加哥变到达拉斯,或者从巴西变到土耳其,都不应该改变模型的预测结果。

c.定向期望测试(DIR)
定向期望测试(DIRectional Expectation Test),则期待标签会以某种方式发生变化。比如情感分析中,加一句负面的话,最终的预测结果不应该变得更正面。这个例子中,我们不是在约束标签,而是在约束标签可能性probability的分布。

4)
对测试实例的敏感性
尽管accuracy差1%就已经是很有意义的数值,CheckList里失败率的细微差别并不能反映什么。因为CheckList对测试实例相对敏感,比起绝对数值的比较,关注点更多在于“失败率是不是足够高或者足够低。”

当模型不能通过测试时,需要思考:我定义的测试实例能否真正测试这项性能?是不是最小单元?还是无意中混淆进去的模式仍会导致模型走捷径呢?
当模型通过测试,也不代表绝对掌握了相应的测试功能,因为语言是高维且非常稀疏的,实例不能穷尽这个性能所有可能出现的形式。
总之,作为一种模型测试框架,CheckList将行为测试抽象为一个独立于具体任务的模型性能x测试类型的矩阵,让用户可以通过填充矩阵,全方位地设计和构想各种测试。

图:用户可以使用矩阵来对记录对模型各项能力的测试,矩阵的行代表测试的能力(capabilities),列代表测试方法的类型(test types)。
二、CheckList测试用例生成工具包
由于测试实例的覆盖面、数量、质量等都会极大地影响测试的效果,也许我们会设计扰动方程去改写飞行目的地、生成更多数据等等。但这涉及的工程量相对较大,耗时耗力。因此,CheckList的第二大部分就是一个开源系统,提供包括可视化、填词建议等实用组件,帮助用户快速生成大规模和多样化的测试用例。
1)
MFT相关工具
CheckList工具包里第一个工具是可填充的实例模板。例如,可以填充积极的形容词,或合适的名词,从而一键生成更多实例。

如果自己定义的填充词比较受限,也可以从BERT或RoBERTa这种语言模型得到更有创造性的建议,从这些建议中保留积极的形容词。也有一些情况并不需要做筛选,比如名词替换不会影响句子的情感,这时只需让RoBERTa决定什么名词合乎语法即可。

下面是一个开源包的小动画,可以轻松地在这个交互可视化界面上选择你想要保留的词。
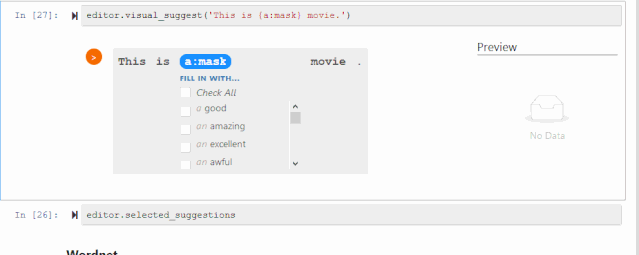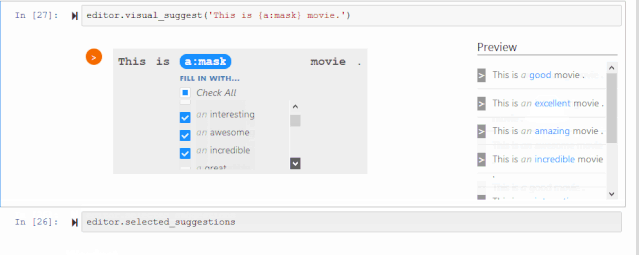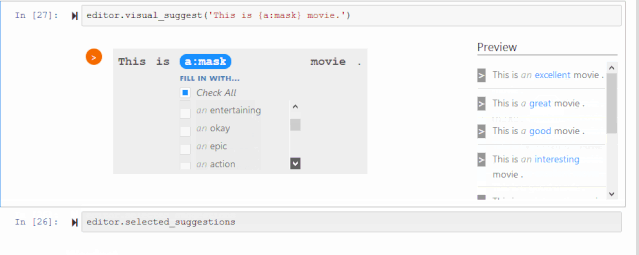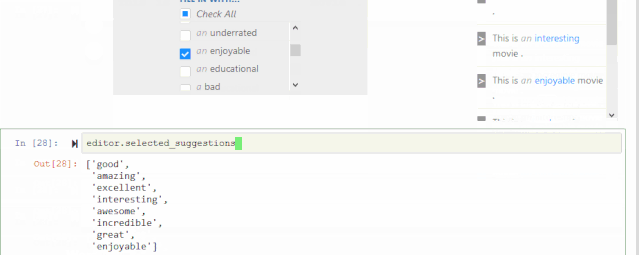
这里也有一些内置词典,是前期调研里发现大家经常用到的填充词,比如不同国家、性别、常见人名,很适合帮助测试模型的公平性。

2)
INV和DIR相关工具
为了增加数据扰动,工具包中有过滤功能,只改写一些有负面意义的句子;有词语替换功能,用WordNet得到“bad”所有可能的反义词,然后用RoBERTa筛选其中适合填充的词;包括其他常见的加减错字、否定等等。

其他功能包括帮助设定模型预期行为,比如预测标签不动、概率分布上浮下浮等。
动图:一个测试矩阵在notebook里的交互小动画,从最开始的失败率总结表,深入到每个性能和具体测试
CheckList能够揭示什么
CheckList的测试看似简单,但运用在商用或学术界的一些state-of-the-art模型上,仍然揭示了很多现有模型的缺陷。其中很多问题,是过去人们极少关注的,比如时序、对命名实体的敏感程度等。
例如测试传统的情感分析任务时,用BERT改动一些完全中性的停用词后,Google和Amazon都会有相对比较高的失败率。

图:比较三个商用模型(分别来自Mircroft,Google和Amazon),以及BERT和RoBERTa这两个学术模型
以及,尽管我们希望模型不会被无关更改或者拼写错误扰动,但实际上只是加一个随机的假链接或者用户名,几乎所有模型都有10%-25%的几率改变预测结果。研究模型是否能理解时效、简单的否定等等问题时,商用模型都表现出明显的失败率。
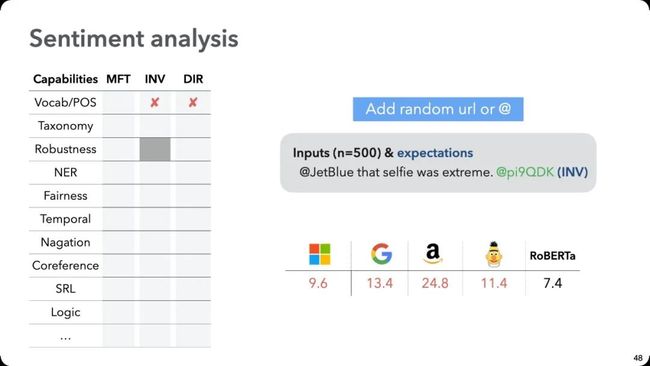
在其他两个任务(Quora question pair和Question answering)中,学术模型的表现也不容乐观。例如,模型会偏向于某一个特定性别群体,验证了“男性当医生、女性当秘书”这一传统偏见。

结语
CheckList通过一个性能清单,帮助人们理解nlp模型测试的具体内容,并通过三个测试类别促使大家思考测试的方法,最后提供了一个工具包实现更大规模的测试。该方法适用于产业链上各个位置的不同人群,包括熟悉日常应用场景和注重工程实现的开发者、特定性能的研究人员、以及唯一真正理解自己的数据和需求的终端用户。
呼吁大家行动起来,共享自己创造的测试,最终给每个任务汇集一个可复用的标准化测试组件。从而,帮助更多的人实现大规模性能测试、了解自己模型的优缺点!
相关文献及链接:
Ribeiro, M. T., Wu, T., Guestrin, C., & Singh, S. (2020). Beyond Accuracy: Behavioral Testing of NLP Models with CheckList.
Link:https://www.aclweb.org/anthology/2020.acl-main.442.pdf
Opensource: https://github.com/marcotcr/checklist
整理:鸽鸽
审稿:吴彤霜
AI Time欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你,请将简历等信息发至[email protected]!
微信联系:AITIME_HY
AI Time是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。

更多资讯请扫码关注
(点击“阅读原文”下载本次报告ppt)
(直播回放:https://b23.tv/pbu0WF)