xgboost和lightgbm算法总结(从决策树到xgboost)
目录
- 一、背景知识合集
-
- 1、决策树
-
- 1.1 ID3.0
-
- 1.1.1 思想
- 1.1.2 划分标准
- 1.1.3 优缺点
- 1.2 C4.5
-
- 1.2.1 思想
- 1.2.2 划分标准
- 1.2.3 优缺点
- 1.3 CART
-
- 1.3.1 思想
- 1.3.2 划分标准
- 1.3.3 优缺点
- 1.4 其他和总结
- 2、模型的方差和偏差
- 3、目标函数、损失函数(成本函数)和正则项
-
- 3.1 损失函数
- 3.2 正则项
- 4、集成模型
-
- 4.1 集成学习模型框架
- 4.2 bagging和boosting框架
-
- 4.2.1 bagging框架——随机森林(Random Forest)
- 4.2.2 boosting框架---Adaboost
-
- 4.2.3 boosting框架---GBDT和Adaboost
- 二、 xgboost 和LightGBM
-
- 1、 xgboost
-
- 1.1 xgboost和GBDT比较
- 1.2 xgboost和Random Forest比较
- 2、 LightGBM和xgboost 比较
-
- 2.1 xgboost的问题
- 2.2 LightGBM的优化
-
- 2.2.1 直方图(Histogram )算法
- 2.2.2 带深度限制的 Leaf-wise 的叶子生长策略
- 2.2.3 直方图做差来进行进一步的加速
- 2.2.4 直接支持类别特征
- 2.2.5 并行优化
-
- 2.2.5.1 特征并行
- 2.2.5.2 数据并行
- 2.2.5.3 投票并行
- 2.2.6 其他优化
- 3、 LightGBM和xgboost 调参(以python示例)
- 3.1 GBM调参及代码
- 3.2 xgboost调参及代码
- 3.3 LightGBM调参及代码
- 三 、 参考资料
xgboost和lightGBM在中外各种比赛(如kaggle)中使用频率最多的一种算法之一(若不是最近几年竞赛数据越来越多图片文本语言类数据,甚至可以去掉之一)。xgboost和lightGBM是一个基于树模型的分布式Boosting算法,并不是如逻辑回归,支持向量机等单一的算法模型,因此在介绍xgboost和lightGBM算法前需对比介绍决策树、随机森林、ababoost、GBDT等算法和相关基本理论
一、背景知识合集
1、决策树
本文重点是xgboost和lightGBM算法,不会对决策树这一算法从理论和实例介绍。本部分主要介绍基本树(ID3、C4.5、CART)的思想、划分标准和优缺点。
1.1 ID3.0
1.1.1 思想
ID3 算法的核心思想就是以信息增益来度量特征选择,选择信息增益最大的特征进行分裂。算法采用自顶向下的贪婪搜索遍历可能的决策树空间(C4.5 也是贪婪搜索)。 其大致步骤为:
1.初始化特征集合和数据集合;
2.计算数据集合信息熵和所有特征的条件熵,选择信息增益最大的特征作为当前决策节点;
3.更新数据集合和特征集合(删除上一步使用的特征,并按照特征值来划分不同分支的数据集合);
4.重复 2,3 两步,若子集值包含单一特征,则为分支叶子节点。
1.1.2 划分标准
ID3 使用的分类标准是信息增益
信息增益 = 信息熵 - 条件熵:
![]()
其中
![]()
其中 其中 C_k 表示集合 D 中属于第 k 类样本的样本子集。D_i 表示 D 中特征 A 取第 i 个值的样本子集。
1.1.3 优缺点
1.ID3 没有剪枝策略,容易过拟合;
2.信息增益准则对可取值数目较多的特征有所偏好,类似“编号”的特3.征其信息增益接近于 1;
4.只能用于处理离散分布的特征;
5.没有考虑缺失值。
1.2 C4.5
1.2.1 思想
C4.5 算法最大的特点是克服了 ID3 对特征数目的偏重这一缺点,引入信息增益率来作为分类标准。除此以外,引入悲观剪枝策略进行后剪,将连续特征离散化和缺失值处理等(不算特别核心,核心是信息增益率)。
1.2.2 划分标准
利用信息增益率可以克服信息增益的缺点,其公式为
![]()
![]()
这里需要注意,信息增益率对可取值较少的特征有所偏好(分母越小,整体越大),因此 C4.5 并不是直接用增益率最大的特征进行划分,而是使用一个启发式方法:先从候选划分特征中找到信息增益高于平均值的特征,再从中选择增益率最高的。
1.2.3 优缺点
优点主要是相对ID3算法的,也就是1.2.1 里的改进点,缺点如下:
1.剪枝策略可以再优化;
2.C4.5 用的是多叉树,用二叉树效率更高;
3.C4.5 使用的熵模型拥有大量耗时的对数运算,连续值还有排序运算;
4.C4.5 在构造树的过程中,对数值属性值需要按照其大小进行排序,从中选择一个分割点,所以只适合于能够驻留于内存的数据集,当训练集大得无法在内存容纳时,程序无法运行
其实还有**C5.0算法:是C4.5应用于大数据集上的分类算法,主要在执行效率和内存使用方面进行了改进。**不过本质上划分标准一致不做具体说明。
1.3 CART
1.3.1 思想
ID3 和 C4.5 虽然在对训练样本集的学习中可以尽可能多地挖掘信息,但是其生成的决策树分支、规模都比较大,CART 算法的二分法可以简化决策树的规模,提高生成决策树的效率。而且,CART 算法既可以分类也可以回归。
1.3.2 划分标准
主要采用基尼系数,公式如下:
![]()
![]()
1.3.3 优缺点
CART 在 C4.5 的基础上进行了很多提升。
1.运算速度快,C4.5 为多叉树,运算速度慢,CART 为二叉树;CART 使用 Gini 系数作为变量的不纯度量,减少了大量的对数运算;因此速度快。
2.C4.5 只能分类,CART 既可以分类也可以回归;
3.CART 采用代理测试来估计缺失值,而 C4.5 以不同概率划分到不同节点中;
4.CART 采用“基于代价复杂度剪枝”方法进行剪枝,而 C4.5 采用悲观剪枝方法。
缺点,其实算是决策树算法本身的都存在的问题:
1.树深度一般不能过深(一般3-7层),否则容易过拟合,且内存占用较高。
2. 对于大数据量和多特征(如几十上百个特征),处理效果一般不好。
3. 决策树对于分类问题效果明显,回归问题效果不算很好。
1.4 其他和总结
除了这几种决策树算法外,还有C5.0、QUEST等,其实主要区别核心在于树的决策(特征)节点划分标准的区别。最常见的可参看下图

其他不做详述。
2、模型的方差和偏差
偏差描述的是模型倾向同类预测错误的程度,方差描述的是模型在做同类预测时出现的波动程度。这两个度量都与模型的泛化误差相关,两者值越小,对应的泛化误差也就越小。
在一个实际模型中,偏差Bias与方差Variance往往是不能兼得的。模型过于简单时,容易发生欠拟合(high bias);模型过于复杂时,又容易发生过拟合(high variance)。
具体见之前的博客用来评估模型好坏的方差和偏差的区别对比
3、目标函数、损失函数(成本函数)和正则项
把要最小化或最大化的模型算法函数称为目标函数(objective function),模型训练的目的就是求模型算法函数的参数值。
模型风险主要有:经验风险+结构风险 2部分。对应的:
目标函数=误差函数(也叫代价函数,成本函数,损失函数)+正则项(也叫惩罚函数,规则项,范数),这2项一个代表准确与否,一个代表泛化能力。
求模型参数就是对目标函数拉格朗日求导。
3.1 损失函数
(有些文章认为损失函数对应单个样本,成本函数对应集团样本)
不同的损失函数一般对应不同的模型算法:
如果是Square loss,那就是最小二乘;.
如果是Hinge Loss,那就是的SVM了;
如果是exp-Loss,那就是 Boosting了;
如果是log-Loss,那就是Logistic Regression了;
其他及具体可见。
知乎问答
3.2 正则项
正则项代表模型泛化能力,也叫范数,是具有“长度”概念的函数。常常被用来度量某个向量空间(或矩阵)中的每个向量的长度或大小。【它定义在赋范线性空间中】【在二维的欧氏几何空间中相当于欧氏范数】。参看文章机器学习中的范数规则化之(一)L0、L1与L2范数
4、集成模型
4.1 集成学习模型框架
集成学习是一种技术框架,其按照不同的思路来组合基础模型,从而达到单一模型无法到达的效果。目前,有三种常见的集成学习框架:bagging,boosting和stacking。
bagging:从训练集从进行子抽样组成每个基模型所需要的子训练集,对所有基模型预测的结果进行综合产生最终的预测结果:
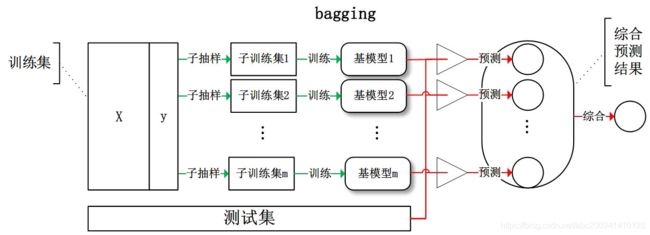
boosting:训练过程为阶梯状,基模型按次序一一进行训练(实现上可以做到并行),基模型的训练集按照某种策略每次都进行一定的转化。对所有基模型预测的结果进行线性综合产生最终的预测结果:
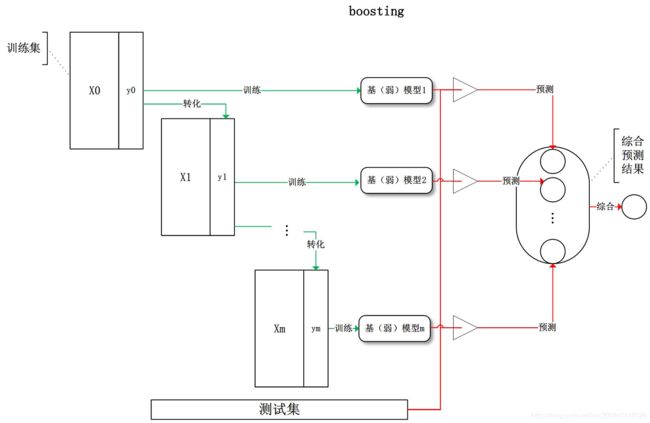
stacking:将训练好的所有基模型对训练基进行预测,第j个基模型对第i个训练样本的预测值将作为新的训练集中第i个样本的第j个特征值,最后基于新的训练集进行训练。同理,预测的过程也要先经过所有基模型的预测形成新的测试集,最后再对测试集进行预测:
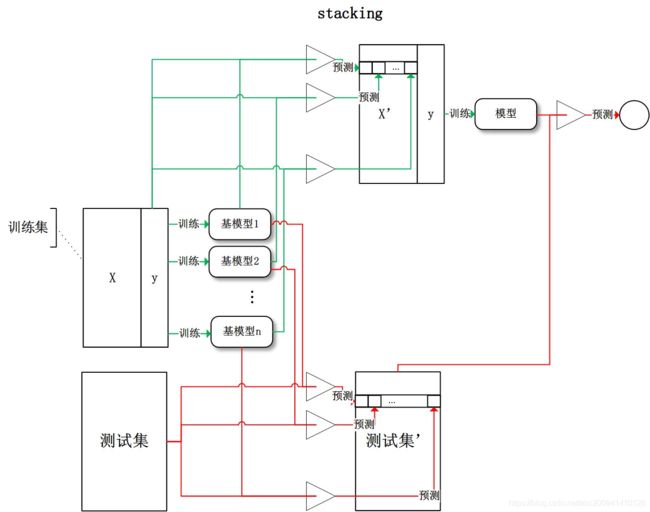
4.2 bagging和boosting框架
4.2.1 bagging框架——随机森林(Random Forest)
前文已经提过偏差和方差的概念,统计学上我们知道m个独立样本集的期望相等时,那么期望不变,方差是原来的1/m。但是如果相关性=1,则不变。bagging本质上就是利用这个方式将强基函数(低偏差,高方差),进一步减小方差,而偏差影响较小。因此一般会对特征进行随机抽样构造不同的树模型。核心是提高不同基模型的独立性。
Random Forest是典型的基于bagging框架的模型,其在bagging的基础上,进一步降低了模型的方差。Random Fores算法不仅对特征进行随机抽样,对样本集也随机抽样。这样一来,基模型之间的相关性降低,从而保证偏差相对不变,整体方差减少的效果。
4.2.2 boosting框架—Adaboost
AdaBoost(Adaptive Boosting,自适应增强),其自适应在于:前一个基本分类器分错的样本会得到加强,加权后的全体样本再次被用来训练下一个基本分类器。同时,在每一轮中加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预先指定的最大迭代次数。
Adaboost 迭代算法有三步:
1.初始化训练样本的权值分布,每个样本具有相同权重;
2.训练弱分类器,如果样本分类正确,则在构造下一个训练集中,它的权值就会被降低;反之提高。用更新过的样本集去训练下一个分类器;
3.将所有弱分类组合成强分类器,各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,降低分类误差率大的弱分类器的权重。
优缺点:
1.分类精度高;
2.可以用各种回归分类模型来构建弱学习器,非常灵活;
3.不容易发生过拟合。
4.对异常点敏感,异常点会获得较高权重。(因为这个缺点,其实实际项目中因为数据质量问题异常数据往往较多,故改算法并不常用)
想了解具体原理可以参考Adaboost 算法的原理与推导
PS:其实改算法在理论上并没有较完备的证明
4.2.3 boosting框架—GBDT和Adaboost
GBDT(Gradient Boosting Decision Tree)是一种迭代的决策树算法,该算法由多棵决策树组成,从名字中我们可以看出来它是属于 Boosting 策略,即牺牲少量方差,降低偏差。GBDT 是被公认的泛化能力较强的算法。GBDT 由三个概念组成:Regression Decision Tree(即 DT)、Gradient Boosting(即 GB),和 Shringkage(一个重要演变)。GBDT工作过程实例:学习的是残差。
GBDT的核心就在于,每一棵树学的是之前所有树结论和的残差,这个残差就是一个加预测值后能得真实值的累加量。比如A的真实年龄是18岁,但第一棵树的预测年龄是12岁,差了6岁,即残差为6岁。那么在第二棵树里我们把A的年龄设为6岁去学习,如果第二棵树真的能把A分到6岁的叶子节点,那累加两棵树的结论就是A的真实年龄;如果第二棵树的结论是5岁,则A仍然存在1岁的残差,第三棵树里A的年龄就变成1岁,继续学。这就是Gradient Boosting在GBDT中的意义。
GBDT可以用更少的feature,且避免过拟合。Boosting的最大好处在于,每一步的残差计算其实变相地增大了分错instance的权重,而已经分对的instance则都趋向于0。这样后面的树就能越来越专注那些前面被分错的instance。就像我们做互联网,总是先解决60%用户的需求凑合着,再解决35%用户的需求,最后才关注那5%人的需求,这样就能逐渐把产品做好,
想了解具体原理可以参考GBDT算法原理以及实例理解
二、 xgboost 和LightGBM
1、 xgboost
xgboost一直在竞赛江湖里被传为神器,比如kaggle/天池比赛中,某人用xgboost于千军万马中斩获冠军。Kaggle各种Top排行榜曾一度呈现Xgboost一统江湖的局面。
1.1 xgboost和GBDT比较
xgboost本质上还是一个GBDT,但是力争把速度和效率发挥到极致,所以叫X (Extreme) GBoosted。事实上,如果不考虑工程实现、解决问题上的一些差异,xgboost与gbdt比较大的不同就是目标函数的定义。推导过程可下载
1、传统GBDT以CART作为基分类器,xgboost还支持线性分类器,这个时候xgboost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)。
2、传统GBDT在目标函数优化时只用到代价函数的一阶导数信息,xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。顺便提一下,xgboost工具支持自定义代价函数,只要函数可一阶和二阶求导。
3、xgboost在目标函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和
4、列抽样(column subsampling)。xgboost借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算,这也是xgboost异于传统gbdt的一个特性。
5、xgboost工具支持并行,data事先排好序并以block的形式存储,利于并行计算。
6、除此之外,还有一些其他改进策略,如,实现了一种分裂节点寻找的近似算法,用于加速和减小内存消耗;节点分裂算法能自动利用特征的稀疏性;支持分布式计算可以运行在MPI,YARN上等。
1.2 xgboost和Random Forest比较
1、xgboost不单可以解决分类问题,还可以适用于回归问题。
2、xgboost也支持列抽样,相对比随机森林效果更好。
3、因为上节的介绍,xgboost可支持在更大数据量和更多特征上比随机森林效果好(一般不用额外做特征的相关性检验)
2、 LightGBM和xgboost 比较
2.1 xgboost的问题
xgboost构建决策树的算法基本思想是使用基于 pre-sorted 的算法:
首先,对所有特征都按照特征的数值进行预排序。
其次,在遍历分割点的时候用O(#data)的代价找到一个特征上的最好分割点。
最后,找到一个特征的分割点后,将数据分裂成左右子节点。
这样的预排序算法的优点是:能精确地找到分割点。
缺点也很明显:
1.level-wise 建树方式对当前层的所有叶子节点一视同仁,有些叶子节点分裂收益非常小,对结果没影响,但还是要分裂,加重了计算代价。
2.预排序方法空间消耗比较大,不仅要保存特征值,也要保存特征的排序索引,同时时间消耗也大,在遍历每个分裂点时都要计算分裂增益(不过这个缺点可以被近似算法所克服)
因此,造成xgboost的时间开销比较大。
2.2 LightGBM的优化
模型的基本理论都是一样。只是在具体的实施方面做了相应的改进或者优化,主要结果是在时间和内存资源方面有改进。与xgboost之于GBDT不同,LightGBM之于xgboost,除去时间和资源消耗方面有明显改进提升外,模型的评价结果方面并无明显提升属于基本一样的效果(甚至有时有稍微下降)。
2.2.1 直方图(Histogram )算法
直方图算法的基本思想是先把连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图。在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。可以加快训练的速度并减少内存的使用。
相对许多提升工具对于决策树的学习使用基于 pre-sorted 的算法(例如,在xgboost中默认的算法)。如下的是基于 histogram 算法的优点:
1、减少分割增益的计算量
Pre-sorted 算法需要 O(#data) 次的计算
Histogram 算法只需要计算 O(#bins) 次, 并且 #bins 远少于 #data
这个仍然需要 O(#data) 次来构建直方图, 而这仅仅包含总结操作
2、减少内存的使用
可以将连续的值替换为 discrete bins。 如果 #bins 较小, 可以利用较小的数据类型来存储训练数据, 如 uint8_t。
无需为 pre-sorting 特征值存储额外的信息
3、减少并行学习的通信代价
2.2.2 带深度限制的 Leaf-wise 的叶子生长策略
在 Histogram 算法之上,LightGBM 进行进一步的优化。LightGBM 抛弃了大多数 GBDT 工具使用的按层生长 (level-wise) 的决策树生长策略,而使用了带有深度限制的按叶子生长 (leaf-wise) 算法。大部分决策树的学习算法通过 level(depth)-wise 策略生长树,如下图一样:
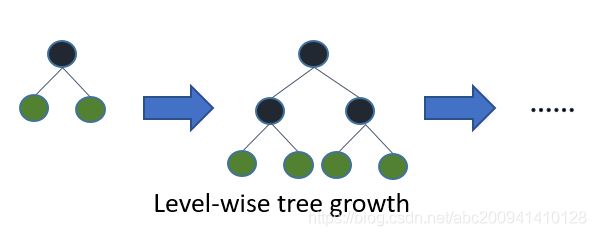
Level-wise 过一次数据可以同时分裂同一层的叶子,容易进行多线程优化,也好控制模型复杂度,不容易过拟合。但实际上 Level-wise 是一种低效的算法,因为它不加区分的对待同一层的叶子,带来了很多没必要的开销,因为实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。
leaf-wise策略生长树,如下图一样:
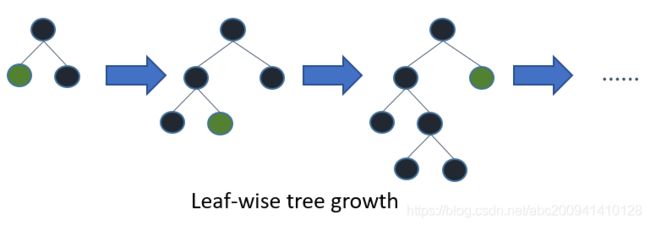
Leaf-wise 则是一种更为高效的策略,每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。因此同 Level-wise 相比,在分裂次数相同的情况下,Leaf-wise 可以降低更多的误差,得到更好的精度。Leaf-wise 的缺点是可能会长出比较深的决策树,产生过拟合。因此 LightGBM 在 Leaf-wise 之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合。
2.2.3 直方图做差来进行进一步的加速
因为前面2个优点或者策略,容易观察到:
在二叉树中可以通过利用叶节点的父节点和相邻节点的直方图的相减来获得该叶节点的直方图;
所以仅仅需要为一个叶节点建立直方图 (其 #data 小于它的相邻节点)就可以通过直方图的相减来获得相邻节点的直方图,而这花费的代价(O(#bins))很小。
2.2.4 直接支持类别特征
我们通常将类别特征转化为 one-hot coding(0/1)。 然而,对于学习树来说这不是个好的解决方案。 原因是,而类别特征的使用是在实践中很常见,而对于一个基数较大的类别特征,学习树会生长的非常不平衡,并且需要非常深的深度才能来达到较好的准确率。
事实上,最好的解决方案是将类别特征划分为两个子集,总共有 2^(k-1) - 1 种可能的划分 但是对于回归树 有个有效的解决方案。为了寻找最优的划分需要大约 k * log(k) .
基本的思想是根据训练目标的相关性对类别进行重排序。 更具体的说,根据累加值(sum_gradient / sum_hessian)重新对(类别特征的)直方图进行排序,然后在排好序的直方图中寻找最好的分割点。
2.2.5 并行优化
LightGBM 还具有支持高效并行的优点。LightGBM 原生支持并行学习,目前支持特征并行和数据并行的两种。
1.特征并行的主要思想是在不同机器在不同的特征集合上分别寻找最优的分割点,然后在机器间同步最优的分割点。
2.数据并行则是让不同的机器先在本地构造直方图,然后进行全局的合并,最后在合并的直方图上面寻找最优分割点。
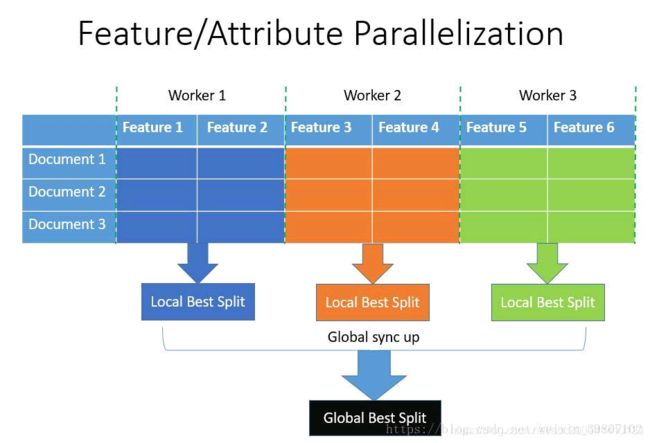
2.2.5.1 特征并行
传统的特征并行算法旨在于在并行化决策树中的【最佳分割点】主要流程如下:
1.垂直划分数据(不同的机器有不同的特征集)
2.在本地特征集寻找最佳划分点 {特征, 阈值}
3.本地进行各个划分的通信整合并得到最佳划分
4.以最佳划分方法对数据进行划分,并将数据划分结果传递给其他线程
5.其他线程对接受到的数据进一步划分
传统的特征并行方法主要不足:
1.存在计算上的局限,传统特征并行无法加速 “split”(时间复杂度为 “O(#data)”)。 因此,当数据量很大的时候,难以加速。
2.需要对划分的结果进行通信整合,其额外的时间复杂度约为 “O(#data/8)”(一个数据一个字节)
LightGBM 中的特征并行不再垂直划分数据,即每个线程都持有全部数据。 因此,LighetGBM中没有数据划分结果之间通信的开销,各个线程都知道如何划分数据。 而且,“#data” 不会变得更大,所以,在使每天机器都持有全部数据是合理的。
LightGBM 中特征并行的流程如下:
1.每个线程都在本地数据集上寻找最佳划分点{特征, 阈值}
2.本地进行各个划分的通信整合并得到最佳划分
3.执行最佳划分。
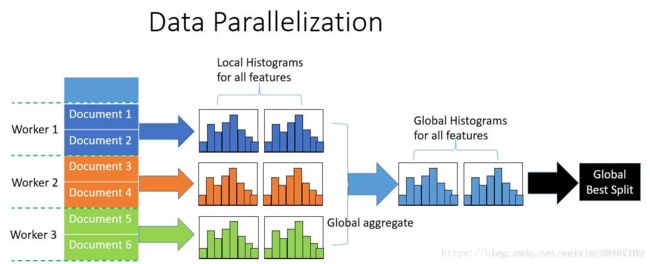
2.2.5.2 数据并行
传统算法数据并行旨在于并行化整个决策学习过程。数据并行的主要流程如下:
1.水平划分数据
2.线程以本地数据构建本地直方图
3.将本地直方图整合成全局整合图
3.在全局直方图中寻找最佳划分,然后执行此划分
传统数据划分的不足:
高通讯开销。 如果使用点对点的通讯算法,一个机器的通讯开销大约为 “O(#machine * #feature * #bin)” 。 如果使用集成的通讯算法(例如, “All Reduce”等),通讯开销大约为 “O(2 * #feature * #bin)”。
LightGBM中的数据并行中采用以下方法较少数据并行中的通讯开销:
1.不同于“整合所有本地直方图以形成全局直方图”的方式,LightGBM 使用分散规约(Reduce scatter)的方式对不同线程的不同特征(不重叠的)进行整合。 然后线程从本地整合直方图中寻找最佳划分并同步到全局的最佳划分中。
2.如上所述。LightGBM 通过直方图做差法加速训练。 基于此,我们可以进行单叶子的直方图通讯,并且在相邻直方图上使用做差法。
通过上述方法,LightGBM 将数据并行中的通讯开销减少到 “O(0.5 * #feature * #bin)”。
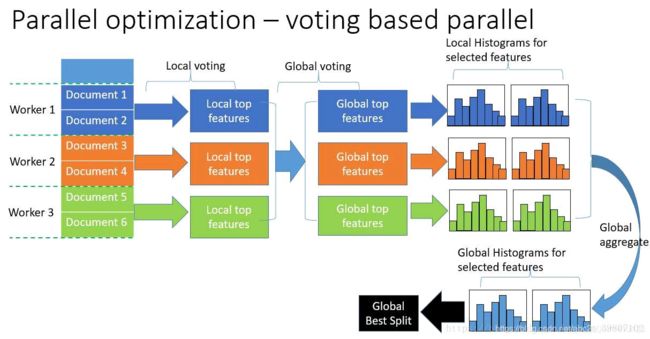
2.2.5.3 投票并行
投票并行未来将致力于将“数据并行”中的通讯开销减少至常数级别。 其将会通过两阶段的投票过程较少特征直方图的通讯开销。
2.2.6 其他优化
LightGBM 还有很多其他细节上的优化,比如 cache 访问优化,多线程优化,稀疏特征优化等等。优化汇总如下(仅做参考):
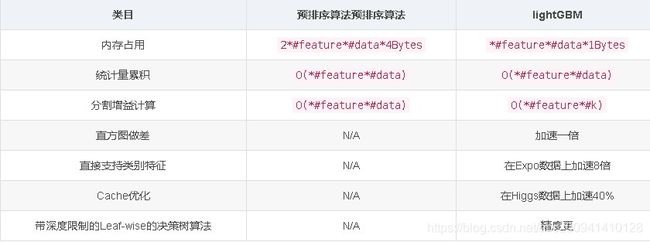
可参考官网资料https://lightgbm.apachecn.org/#/docs/
3、 LightGBM和xgboost 调参(以python示例)
LightGBM和xgboost 调参 在python中跟gbm一脉相承。因此拿来一起说。总的来说三个算法的参数可以被归为三类:
1.树参数:调节模型中每个决定树的性质;
2.Boosting参数:调节模型中boosting的操作;
3.其他模型参数:调节模型总体的各项运作。
因为每个算法有几十个参数,很多直接区默认值即可,我们只对实际应用中常见的进行说明。
3.1 GBM调参及代码
参数调节顺序:
- 固定 learning rate和估测的决策树数量n_estimators
- 树的深度max_depth
- 需继续分割的最小样本数min_samples_split
- 叶节点最少样本数min_samples_leaf
- 最大特征数max_features
- 子样本集比例subsample(也叫抽样比例)
- learning_rate学习率(决策树数量n_estimators 也要按比例变化)
调参可以2个一起用网格搜索法找最优解,1、2、7顺序相对固定。其他其实可以微调。
代码示例:
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
import xgboost as xgb
from xgboost.sklearn import XGBClassifier
from sklearn.model_selection import cross_val_score
from sklearn import metrics
from sklearn.model_selection import GridSearchCV
import matplotlib.pylab as plt
from matplotlib.pylab import rcParams
rcParams['figure.figsize'] = 12, 4
## 数据不方便提供,可看参考资料里的博客
train = pd.read_csv('train.csv')
test=pd.read_csv('test.csv')
train.dtypes
train.apply(lambda x: sum(x.isnull()))
target='target'
IDcol = 'main_waybill_no'
train['target'].value_counts()
def modelfit(alg, dtrain, predictors, performCV=True, printFeatureImportance=True, cv_folds=5):
#模型
alg.fit(dtrain[predictors], dtrain['target'])
#预测数据:
dtrain_predictions = alg.predict(dtrain[predictors])
dtrain_predprob = alg.predict_proba(dtrain[predictors])[:,1]
#交叉检验:
if performCV:
cv_score = cross_val_score(alg, dtrain[predictors], dtrain['target'], cv=cv_folds, scoring='roc_auc')
#cv_score = cross_validation.cross_val_score(alg, dtrain[predictors], dtrain['target'], cv=cv_folds, scoring='roc_auc')
#打印模型结果:
print ("\nModel Report")
print ("Accuracy : %.4g" % metrics.accuracy_score(dtrain['target'].values, dtrain_predictions))
print ("F1 : %.4g" % metrics.f1_score(dtrain['target'].values, dtrain_predictions))
print ("AUC Score (Train): %f" % metrics.roc_auc_score(dtrain['target'], dtrain_predprob))
if performCV:
print ("CV Score : Mean - %.7g | Std - %.7g | Min - %.7g | Max - %.7g" % (np.mean(cv_score),np.std(cv_score),np.min(cv_score),np.max(cv_score)))
#特征重要性:
if printFeatureImportance:
feat_imp = pd.Series(alg.feature_importances_, predictors).sort_values(ascending=False)
print(feat_imp)
feat_imp.plot(kind='bar', title='Feature Importances')
plt.ylabel('Feature Importance Score')
#变量
predictors = [x for x in train.columns if x not in [target, IDcol]]
gbm0 = GradientBoostingClassifier(random_state=10)
modelfit(gbm0, train, predictors)
#网格搜索选择最优参数,决策树数量
predictors = [x for x in train.columns if x not in [target, IDcol]]
param_test1 = {
'n_estimators':range(200,801,20)}
gsearch1 = GridSearchCV(estimator = GradientBoostingClassifier(learning_rate=0.1, min_samples_split=800,
min_samples_leaf=150,max_depth=9,max_features='sqrt', subsample=0.8,random_state=10),
param_grid = param_test1, scoring='roc_auc',n_jobs=8,iid=False, cv=5)
gsearch1.fit(train[predictors],train[target])
xx=pd.DataFrame(gsearch1.cv_results_)
means = gsearch1.cv_results_['mean_test_score']
params = gsearch1.cv_results_['params']
std=gsearch1.cv_results_['std_test_score']
means,params,std, gsearch1.best_params_, gsearch1.best_score_
#树的深度和分割的最小样本数
param_test2 = {
'max_depth':range(5,13,2), 'min_samples_split':range(500,1501,200)}
gsearch2 = GridSearchCV(estimator = GradientBoostingClassifier(learning_rate=0.1, n_estimators=320,
max_features='sqrt', subsample=0.8, random_state=10),
param_grid = param_test2, scoring='roc_auc',n_jobs=8,iid=False, cv=5)
gsearch2.fit(train[predictors],train[target])
means = gsearch2.cv_results_['mean_test_score']
params = gsearch2.cv_results_['params']
std=gsearch2.cv_results_['std_test_score']
rank=gsearch2.cv_results_['rank_test_score']
means,params,std,rank, gsearch2.best_params_, gsearch2.best_score_
# 叶节点最少样本数
param_test3 = {
'min_samples_split':range(700,1101,100), 'min_samples_leaf':range(110,211,20)}
gsearch3 = GridSearchCV(estimator = GradientBoostingClassifier(learning_rate=0.1, n_estimators=320,max_depth=9,
max_features='sqrt', subsample=0.8, random_state=10),
param_grid = param_test3, scoring='roc_auc',n_jobs=8,iid=False, cv=5)
gsearch3.fit(train[predictors],train[target])
means = gsearch3.cv_results_['mean_test_score']
params = gsearch3.cv_results_['params']
std=gsearch3.cv_results_['std_test_score']
rank=gsearch3.cv_results_['rank_test_score']
means,params,std,rank, gsearch3.best_params_, gsearch3.best_score_
modelfit(gsearch3.best_estimator_, train, predictors)
# 最大特征数
param_test4 = {
'max_features':range(11,16,1)}
gsearch4 = GridSearchCV(estimator = GradientBoostingClassifier(learning_rate=0.1, n_estimators=320,max_depth=9,
min_samples_split=800, min_samples_leaf=150, subsample=0.8, random_state=10),
param_grid = param_test4, scoring='roc_auc',n_jobs=8,iid=False, cv=5)
gsearch4.fit(train[predictors],train[target])
means = gsearch4.cv_results_['mean_test_score']
params = gsearch4.cv_results_['params']
std=gsearch4.cv_results_['std_test_score']
rank=gsearch4.cv_results_['rank_test_score']
means,params,std,rank, gsearch4.best_params_, gsearch4.best_score_
#子样本集比例
param_test5 = {
'subsample':[0.6,0.7,0.75,0.8,0.85,0.9,0.95]}
gsearch5 = GridSearchCV(estimator = GradientBoostingClassifier(learning_rate=0.1, n_estimators=320,max_depth=9,
min_samples_split=800, min_samples_leaf=150, random_state=10, max_features=12),
param_grid = param_test5, scoring='roc_auc',n_jobs=8,iid=False, cv=5)
gsearch5.fit(train[predictors],train[target])
means = gsearch5.cv_results_['mean_test_score']
params = gsearch5.cv_results_['params']
std=gsearch5.cv_results_['std_test_score']
rank=gsearch5.cv_results_['rank_test_score']
means,params,std,rank, gsearch5.best_params_, gsearch5.best_score_
modelfit(gsearch5.best_estimator_, train, predictors)
# learning_rate学习率
predictors = [x for x in train.columns if x not in [target, IDcol]]
gbm_tuned_1 = GradientBoostingClassifier(learning_rate=0.05, n_estimators=640,max_depth=9, min_samples_split=800,
min_samples_leaf=150, subsample=0.8, random_state=10, max_features=12)
modelfit(gbm_tuned_1, train, predictors)
predictors = [x for x in train.columns if x not in [target, IDcol]]
gbm_tuned_2 = GradientBoostingClassifier(learning_rate=0.01, n_estimators=3200,max_depth=9, min_samples_split=800,
min_samples_leaf=150, subsample=0.8, random_state=10, max_features=12)
modelfit(gbm_tuned_2, train, predictors)
predictors = [x for x in train.columns if x not in [target, IDcol]]
gbm_tuned_3 = GradientBoostingClassifier(learning_rate=0.005, n_estimators=6400,max_depth=9, min_samples_split=800,
min_samples_leaf=150, subsample=0.8, random_state=10, max_features=12,
warm_start=True)
modelfit(gbm_tuned_3, train, predictors, performCV=True)
需要数据练习及其他参数可参考博客Complete Machine Learning Guide to Parameter Tuning in Gradient Boosting (GBM) in Python
里面有些代码和包的调用已经过,可参考本人代码
3.2 xgboost调参及代码
参数调节顺序:
- 固定 learning rate和求出最佳决策树数量n_estimators(不需要遍历调整,这是xgboost算法优势)
- 树的深度max_depth和最小叶子节点样本权重和min_child_weight(默认1,一般大于1),避免欠拟合与过拟合
- 损失函数下降值gamma
- 抽样比例subsample和特征采样比例colsample_bytree
- L1正则项reg_alpha,耗时非常久
- L2正则项reg_lambda
- learning_rate学习率(决策树数量n_estimators 也要按比例变化)
官方参数及解释:https://xgboost.apachecn.org/#/docs/15
代码示例:
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
import xgboost as xgb
from xgboost.sklearn import XGBClassifier
from sklearn.model_selection import cross_val_score
from sklearn import metrics
from sklearn.model_selection import GridSearchCV
import matplotlib.pylab as plt
from matplotlib.pylab import rcParams
rcParams['figure.figsize'] = 12, 4
train = pd.read_csv('train.csv')
test=pd.read_csv('test.csv')
train.dtypes
train.apply(lambda x: sum(x.isnull()))
target='target'
IDcol = 'main_waybill_no'
train['target'].value_counts()
def modelfit(alg, dtrain, predictors, performCV=True, printFeatureImportance=True, cv_folds=5,early_stopping_rounds=50):
#交叉检验:求最佳决策树:
if performCV:
xgb_param = alg.get_xgb_params()
xgtrain = xgb.DMatrix(dtrain[predictors].values, label=dtrain[target].values)
cvresult = xgb.cv(xgb_param, xgtrain, num_boost_round=alg.get_params()['n_estimators'], nfold=cv_folds,
metrics='auc', early_stopping_rounds=early_stopping_rounds)
alg.set_params(n_estimators=cvresult.shape[0])
print("n_estimators:")
print(alg.set_params(n_estimators=cvresult.shape[0]))
#Fit the algorithm on the data
alg.fit(dtrain[predictors], dtrain['target'],eval_metric='auc')
#Predict training set:
dtrain_predictions = alg.predict(dtrain[predictors])
dtrain_predprob = alg.predict_proba(dtrain[predictors])[:,1]
#Print model report:
print ("\nModel Report")
print ("Accuracy : %.4g" % metrics.accuracy_score(dtrain['target'].values, dtrain_predictions))
print ("F1 : %.4g" % metrics.f1_score(dtrain['target'].values, dtrain_predictions))
print ("AUC Score (Train): %f" % metrics.roc_auc_score(dtrain['target'], dtrain_predprob))
# if performCV:
# print ("CV Score : Mean - %.7g | Std - %.7g | Min - %.7g | Max - %.7g" % (np.mean(cvresult['train-auc-mean']),np.std(cvresult['train-auc-std']),np.min(cvresult['train-auc-mean']),np.max(cvresult['train-auc-mean'])))
#Print Feature Importance:
if printFeatureImportance:
feat_imp = pd.Series(alg.get_booster().get_fscore()).sort_values(ascending=False)
print(feat_imp)
feat_imp.plot(kind='bar', title='Feature Importances')
plt.ylabel('Feature Importance Score')
#Choose all predictors except target & IDcols
predictors = [x for x in train.columns if x not in [target, IDcol]]
xgb1 = XGBClassifier(learning_rate =0.1,n_estimators=800,max_depth=9,min_child_weight=1,gamma=0,
subsample=0.8,colsample_bytree=0.8,objective= 'binary:logistic',nthread=8,scale_pos_weight=1,
seed=27)
#不需要调参最佳决策树数量
modelfit(xgb1, train, predictors)
#nthread 参数可以不赋值,树的最大深度和最小叶子节点样本权重和,避免欠拟合与过拟合
predictors = [x for x in train.columns if x not in [target, IDcol]]
param_test1 = {
'max_depth':range(6,11,1), 'min_child_weight':range(1,5,1)}
gsearch1 = GridSearchCV(estimator = XGBClassifier(learning_rate=0.1,n_estimators=95,gamma=0,colsample_bytree=0.8,
objective= 'binary:logistic',nthread=8,scale_pos_weight=1, subsample=0.8,seed=27),
param_grid = param_test1, scoring='roc_auc',n_jobs=8,iid=False, cv=5)
gsearch1.fit(train[predictors],train[target])
#grid_scores_在sklearn0.20版本中已被删除,取而代之的是cv_results_,为字典类型
xx=pd.DataFrame(gsearch1.cv_results_)
means = gsearch1.cv_results_['mean_test_score']
params = gsearch1.cv_results_['params']
std=gsearch1.cv_results_['std_test_score']
means,params,std, gsearch1.best_params_, gsearch1.best_score_
modelfit(gsearch1.best_estimator_, train, predictors)
#损失函数下降值
param_test2 = {
'gamma':[i/100.0 for i in range(0,20,2)]}
gsearch2 = GridSearchCV(estimator = XGBClassifier(learning_rate=0.1,n_estimators=95,max_depth=9,min_child_weight=2,colsample_bytree=0.8,
objective= 'binary:logistic',scale_pos_weight=1, subsample=0.8,seed=27),
param_grid = param_test2, scoring='roc_auc',n_jobs=8,iid=False, cv=5)
gsearch2.fit(train[predictors],train[target])
means = gsearch2.cv_results_['mean_test_score']
params = gsearch2.cv_results_['params']
std=gsearch2.cv_results_['std_test_score']
rank=gsearch2.cv_results_['rank_test_score']
means,params,std,rank, gsearch2.best_params_, gsearch2.best_score_
#抽样比例和特征采样比例
param_test3 = {
'subsample':[i/100.0 for i in range(70,95,5)],'colsample_bytree':[i/100.0 for i in range(70,95,5)]}
gsearch3 = GridSearchCV(estimator = XGBClassifier(learning_rate=0.1,n_estimators=95,max_depth=9,min_child_weight=2,
gamma=0.18,objective= 'binary:logistic',nthread=8,scale_pos_weight=1, seed=27),
param_grid = param_test3, scoring='roc_auc',n_jobs=8,iid=False, cv=5)
gsearch3.fit(train[predictors],train[target])
means = gsearch3.cv_results_['mean_test_score']
params = gsearch3.cv_results_['params']
std=gsearch3.cv_results_['std_test_score']
rank=gsearch3.cv_results_['rank_test_score']
means,params,std,rank, gsearch3.best_params_, gsearch3.best_score_
modelfit(gsearch3.best_estimator_, train, predictors)
#L1正则项,耗时非常久,
param_test4 = {
'reg_alpha':[0.1, 0.5,1, 1.5, 2,2.5]}
gsearch4 = GridSearchCV(estimator = XGBClassifier(learning_rate=0.1,n_estimators=95,max_depth=9,min_child_weight=2,colsample_bytree=0.8,
gamma=0.18,objective= 'binary:logistic',nthread=8,scale_pos_weight=1, subsample=0.8,seed=27),
param_grid = param_test4, scoring='roc_auc',n_jobs=8,iid=False, cv=5)
gsearch4.fit(train[predictors],train[target])
means = gsearch4.cv_results_['mean_test_score']
params = gsearch4.cv_results_['params']
std=gsearch4.cv_results_['std_test_score']
rank=gsearch4.cv_results_['rank_test_score']
means,params,std,rank, gsearch4.best_params_, gsearch4.best_score_
modelfit(gsearch4.best_estimator_, train, predictors)
#L2正则项
param_test5 = {
'reg_lambda':[i/10.0 for i in range(0,50,5)]}
gsearch5 = GridSearchCV(estimator = XGBClassifier(learning_rate=0.1,n_estimators=95,max_depth=9,min_child_weight=2,colsample_bytree=0.8,
gamma=0.18, reg_alpha=1,objective= 'binary:logistic',nthread=8,scale_pos_weight=1, subsample=0.8,seed=27),
param_grid = param_test5, scoring='roc_auc',n_jobs=8,iid=False, cv=5)
gsearch5.fit(train[predictors],train[target])
means = gsearch5.cv_results_['mean_test_score']
params = gsearch5.cv_results_['params']
std=gsearch5.cv_results_['std_test_score']
rank=gsearch5.cv_results_['rank_test_score']
means,params,std,rank, gsearch5.best_params_, gsearch5.best_score_
modelfit(gsearch5.best_estimator_, train, predictors)
#调节learning_rate和树
predictors = [x for x in train.columns if x not in [target, IDcol]]
xgb_tuned_1 = XGBClassifier(learning_rate=0.05,n_estimators=190,max_depth=9,min_child_weight=2,colsample_bytree=0.8,gamma=0.18,
reg_lambda=1.0,reg_alpha=1,objective= 'binary:logistic',nthread=8,scale_pos_weight=1, subsample=0.8,seed=27)
modelfit(xgb_tuned_1, train, predictors)
predictors = [x for x in train.columns if x not in [target, IDcol]]
xgb_tuned_2 = XGBClassifier(learning_rate=0.01,n_estimators=950,max_depth=9,min_child_weight=2,colsample_bytree=0.8,gamma=0.18,
reg_lambda=1.0,reg_alpha=1,objective= 'binary:logistic',nthread=8,scale_pos_weight=1, subsample=0.8,seed=27)
modelfit(xgb_tuned_2, train, predictors)
需要数据练习及其他参数可参考博客Complete Guide to Parameter Tuning in XGBoost with codes in Python
里面有些代码和包的调用已经改过,如果源代码跑不通可参考本人代码
3.3 LightGBM调参及代码
参数调节顺序:
- 固定 learning rate和求出最佳决策树数量n_estimators(不需要遍历调整,这是LightGBM算法优势)
- 树的深度max_depth和叶子节数目num_leaves,因为算法原因,这后一个参数特别重要
- 一个叶子上数据的最小数量min_child_samples和子树观测权重之和的最小值min_child_weight
- 抽样比例subsample和特征采样比例colsample_bytree
- L1正则项reg_alpha,耗时非常久
- L2正则项reg_lambda
- learning_rate学习率(决策树数量n_estimators 也要按比例变化)
还有很多其他参数(包括特征类型和缺失值设置),官方参数及解释:https://lightgbm.apachecn.org/#/docs/6
代码示例:
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
import xgboost as xgb
from xgboost.sklearn import XGBClassifier
import lightgbm as lgb
from lightgbm.sklearn import LGBMClassifier
#from sklearn.model_selection import cross_validate
from sklearn.model_selection import cross_val_score
from sklearn import metrics
#from sklearn.grid_search import GridSearchCV #因sklearn版本迭代会报错,用下面的语句
from sklearn.model_selection import GridSearchCV
import matplotlib.pylab as plt
from matplotlib.pylab import rcParams
rcParams['figure.figsize'] = 12, 4
#https://scikit-learn.org/stable/modules/model_evaluation.html
def modelfit(alg, dtrain, predictors, performCV=False, printFeatureImportance=True, cv_folds=5,early_stopping_rounds=50):
#Perform cross-validation:
if performCV:
lgb_param = alg.get_params()
# 构建lgb中的Dataset格式
lgtrain = lgb.Dataset(dtrain[predictors].values, label=dtrain[target].values)
cvresult = lgb.cv(lgb_param, lgtrain, num_boost_round=alg.get_params()['n_estimators'], nfold=cv_folds,
stratified=False,shuffle=True,metrics='auc', early_stopping_rounds=early_stopping_rounds,
show_stdv=True, seed=0)
#print("best n_estimators:", len(cvresult['auc-mean']))
# print('best cv stdv:', cvresult['auc-stdv'][-1])
print("best n_estimators:", len(cvresult[list(cvresult.keys())[0]]))
print('best cv score:', cvresult[list(cvresult.keys())[1]][-1])
#Fit the algorithm on the data
alg.fit(dtrain[predictors], dtrain['target'],eval_metric='auc')
#Predict training set:
dtrain_predictions = alg.predict(dtrain[predictors])
dtrain_predprob = alg.predict_proba(dtrain[predictors])[:,1]
#Print model report:
print ("\nModel Report")
print ("Accuracy : %.4g" % metrics.accuracy_score(dtrain['target'].values, dtrain_predictions))
print ("F1 : %.4g" % metrics.f1_score(dtrain['target'].values, dtrain_predictions))
print ("AUC Score (Train): %f" % metrics.roc_auc_score(dtrain['target'], dtrain_predprob))
# if performCV:
# print ("CV Score : Mean - %.7g | Std - %.7g | Min - %.7g | Max - %.7g" % (np.mean(cvresult['train-auc-mean']),np.std(cvresult['train-auc-std']),np.min(cvresult['train-auc-mean']),np.max(cvresult['train-auc-mean'])))
#Print Feature Importance:
if printFeatureImportance:
feat_imp = pd.Series(alg.feature_importances_, predictors).sort_values(ascending=False)
print(feat_imp)
feat_imp.plot(kind='bar', title='Feature Importances')
plt.ylabel('Feature Importance Score')
#Choose all predictors except target & IDcols
#min_child_samples=20,min_child_weight。采用默认值
predictors = [x for x in train.columns if x not in [target, IDcol]]
lgb1 = LGBMClassifier(learning_rate =0.1,n_estimators=800,max_depth=9,num_leaves=500,
min_child_samples=20,min_child_weight=0.001, subsample=0.8,colsample_bytree=0.8,
reg_alpha=0, reg_lambda=1,max_bin=200,
boosting_type='gbdt',objective= 'binary',nthread=8)
modelfit(lgb1, train, predictors, performCV=True)
#max_depth 和 num_leaves
predictors = [x for x in train.columns if x not in [target, IDcol]]
param_test1 = {
'max_depth':range(6,12,1), 'num_leaves':range(200,800,200)}
gsearch1 = GridSearchCV(estimator = LGBMClassifier(learning_rate =0.1,n_estimators=404,
min_child_samples=20,min_child_weight=0.001, subsample=0.8,colsample_bytree=0.8,
reg_alpha=0, reg_lambda=1,max_bin=200,
boosting_type='gbdt',objective= 'binary',nthread=8),
param_grid = param_test1, scoring='roc_auc',n_jobs=8,iid=False, cv=5)
gsearch1.fit(train[predictors],train[target])
#grid_scores_在sklearn0.20版本中已被删除,取而代之的是cv_results_,为字典类型
xx=pd.DataFrame(gsearch1.cv_results_)
means = gsearch1.cv_results_['mean_test_score']
params = gsearch1.cv_results_['params']
std=gsearch1.cv_results_['std_test_score']
means,params,std, gsearch1.best_params_, gsearch1.best_score_
modelfit(gsearch1.best_estimator_, train, predictors)
#min_data_in_leaf 和 min_sum_hessian_in_leaf
param_test2 = {
'min_child_samples':range(10,60,10),'min_child_weight':[i/1000.0 for i in range(1,6,5)]}
gsearch2 = GridSearchCV(estimator = LGBMClassifier(learning_rate =0.1,n_estimators=404,
max_depth=11,num_leaves=200, subsample=0.8,colsample_bytree=0.8,
reg_alpha=0, reg_lambda=1,max_bin=200,
boosting_type='gbdt',objective= 'binary',nthread=8),
param_grid = param_test2, scoring='roc_auc',n_jobs=8,iid=False, cv=5)
gsearch2.fit(train[predictors],train[target])
means = gsearch2.cv_results_['mean_test_score']
params = gsearch2.cv_results_['params']
std=gsearch2.cv_results_['std_test_score']
rank=gsearch2.cv_results_['rank_test_score']
means,params,std,rank, gsearch2.best_params_, gsearch2.best_score_
#feature_fraction 和 bagging_fraction
param_test3 = {
'subsample':[i/100.0 for i in range(80,95,5)],'colsample_bytree':[i/100.0 for i in range(70,90,5)]}
gsearch3 = GridSearchCV(estimator = LGBMClassifier(learning_rate =0.1,n_estimators=404,max_depth=11,num_leaves=200,
min_child_samples=10,min_child_weight=0.001,
reg_alpha=0, reg_lambda=1,max_bin=200,
boosting_type='gbdt',objective= 'binary',nthread=8),
param_grid = param_test3, scoring='roc_auc',n_jobs=8,iid=False, cv=5)
gsearch3.fit(train[predictors],train[target])
means = gsearch3.cv_results_['mean_test_score']
params = gsearch3.cv_results_['params']
std=gsearch3.cv_results_['std_test_score']
rank=gsearch3.cv_results_['rank_test_score']
means,params,std,rank, gsearch3.best_params_, gsearch3.best_score_
modelfit(gsearch3.best_estimator_, train, predictors)
#正则化参数lambda_l1(reg_alpha), lambda_l2(reg_lambda)
#
param_test4 = {
'reg_alpha': [0, 0.001, 0.01, 0.03, 0.08, 0.3, 0.5]}
#param_test4 = {'reg_alpha':[i/100.0 for i in range(50,150,10)]}
gsearch4 = GridSearchCV(estimator = LGBMClassifier(learning_rate =0.1,n_estimators=404,max_depth=11,num_leaves=200,
min_child_samples=10,min_child_weight=0.001, subsample=0.8,colsample_bytree=0.7,
reg_lambda=1, max_bin=200,
boosting_type='gbdt',objective= 'binary',nthread=8),
param_grid = param_test4, scoring='roc_auc',n_jobs=8,iid=False, cv=5)
gsearch4.fit(train[predictors],train[target])
means = gsearch4.cv_results_['mean_test_score']
params = gsearch4.cv_results_['params']
std=gsearch4.cv_results_['std_test_score']
rank=gsearch4.cv_results_['rank_test_score']
means,params,std,rank, gsearch4.best_params_, gsearch4.best_score_
modelfit(gsearch4.best_estimator_, train, predictors)
#Grid seach on subsample and max_features
param_test5 = {
'reg_lambda':[i/100.0 for i in range(50,150,5)]}
#param_test5 = {'reg_lambda': [0, 0.001, 0.01, 0.03, 0.08, 0.3, 0.5]}
gsearch5 = GridSearchCV(estimator = LGBMClassifier(learning_rate =0.1,n_estimators=404,max_depth=11,num_leaves=200,
min_child_samples=10,min_child_weight=0.001, subsample=0.8,colsample_bytree=0.7,
reg_alpha=0.3,max_bin=200,
boosting_type='gbdt',objective= 'binary',nthread=8),
param_grid = param_test5, scoring='roc_auc',n_jobs=8,iid=False, cv=5)
gsearch5.fit(train[predictors],train[target])
means = gsearch5.cv_results_['mean_test_score']
params = gsearch5.cv_results_['params']
std=gsearch5.cv_results_['std_test_score']
rank=gsearch5.cv_results_['rank_test_score']
means,params,std,rank, gsearch5.best_params_, gsearch5.best_score_
modelfit(gsearch5.best_estimator_, train, predictors)
#Choose all predictors except target & IDcols
predictors = [x for x in train.columns if x not in [target, IDcol]]
lgb_tuned_1 = LGBMClassifier(learning_rate =0.05,n_estimators=808,max_depth=11,num_leaves=200,
min_child_samples=10,min_child_weight=0.001, subsample=0.8,colsample_bytree=0.8,
reg_alpha=0.3, reg_lambda=1.45,max_bin=200,
boosting_type='gbdt',objective= 'binary',nthread=8)
modelfit(lgb_tuned_1, train, predictors)
#Choose all predictors except target & IDcols
predictors = [x for x in train.columns if x not in [target, IDcol]]
lgb_tuned_2 = LGBMClassifier(learning_rate =0.01,n_estimators=4040,max_depth=11,num_leaves=200,
min_child_samples=10,min_child_weight=0.001, subsample=0.8,colsample_bytree=0.8,
reg_alpha=0.3, reg_lambda=1.45,max_bin=200,
boosting_type='gbdt',objective= 'binary',nthread=8)
modelfit(lgb_tuned_2, train, predictors)
其他代码可参考https://blog.csdn.net/weixin_41843918/article/details/89475621
三 、 参考资料
决策树:
https://zhuanlan.zhihu.com/p/85731206
偏差-方差&损失函数-正则化:
https://blog.csdn.net/abc200941410128/article/details/78674439
https://blog.csdn.net/zouxy09/article/details/24971995/
https://www.zhihu.com/question/317383780/answer/631866229
GBDT-随机森林,集成模型等:
https://www.cnblogs.com/jasonfreak/p/5657196.html
https://zhuanlan.zhihu.com/p/86263786
https://blog.csdn.net/zpalyq110/article/details/79527653?ops_request_misc=&request_id=&biz_id=102&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-1
https://blog.csdn.net/v_JULY_v/article/details/40718799
lightgbm 和xgboost:
https://xgboost.apachecn.org/#/docs/15
https://lightgbm.apachecn.org/#/docs/6
https://blog.csdn.net/v_JULY_v/article/details/81410574
https://blog.csdn.net/weixin_39807102/article/details/81912566#141-histogram-%E7%AE%97%E6%B3%95
https://blog.csdn.net/weixin_41843918/article/details/89475621
https://blog.csdn.net/weixin_42150936/article/details/88635939?ops_request_misc=%7B%22request%5Fid%22%3A%22158287381919726869065152%22%2C%22scm%22%3A%2220140713.130056874…%22%7D&request_id=158287381919726869065152&biz_id=0&utm_source=distribute.pc_search_result.none-task
https://blog.csdn.net/weixin_41843918/article/details/89475621