分类-回归树模型(CART)在R语言中的实现
CART模型,即Classification And Regression Trees。它和一般回归分析类似,是用来对变量进行解释和预测的工具,也是数据挖掘中的一种常用算法。如果因变量是连续数据,相对应的分析称为回归树,如果因变量是分类数据,则相应的分析称为分类树。
决策树是一种倒立的树结构,它由内部节点、叶子节点和边组成。其中最上面的一个节点叫根节点。 构造一棵决策树需要一个训练集,一些例子组成,每个例子用一些属性(或特征)和一个类别标记来描述。构造决策树的目的是找出属性和类别间的关系,一旦这种关系找出,就能用它来预测将来未知类别的记录的类别。这种具有预测功能的系统叫决策树分类器。其算法的优点在于:1)可以生成可以理解的规则。2)计算量相对来说不是很大。3)可以处理多种数据类型。4)决策树可以清晰的显示哪些变量较重要。
下面以一个例子来讲解如何在R语言中建立树模型。为了预测身体的肥胖程度,可以从身体的其它指标得到线索,例如:腰围、臀围、肘宽、膝宽、年龄。
# 首先载入所需软件包
> library(rpart)
> library(maptree)
> library(TH.data)
# 读入样本数据
> data("bodyfat", package="TH.data") # 原文mboost包中没有此数据集了,改用TH.datarpart()函数用法:
rpart(formula, data, weights, subset, na.action = na.rpart, method, model = FALSE, x = FALSE, y = TRUE, parms, control, cost, …)
主要参数说明:
formula:回归方程形式:例如 y~x1+x2+x3。
data:数据:包含前面方程中变量的数据框(dataframe)。
na.action:缺失数据的处理办法:默认办法是删除因变量缺失的观测而保留自变量缺失的观测。
method:根据树末端的数据类型选择相应变量分割方法,本参数有四种取值:连续型 =>“anova”;离散型 =>“class”;计数型(泊松过程) =>“poisson”;生存分析型]“exp”。程序会根据因变量的类型自动选择方法,但一般情况下最好还是指明本参数,以便让程序清楚做哪一种树模型。
parms:用来设置三个参数:先验概率、损失矩 阵、分类纯度的度量方法。
control:控制每个节点上的最小样本量、交叉验证的次数、复杂性参量:即cp:complexity pamemeter,这个参数意味着对每一步拆分,模型的拟合优度必须提高的程度,等等。
# 建立公式
> formula <- DEXfat~age+waistcirc+hipcirc+elbowbreadth+kneebreadth
# 用rpart命令构建树模型,结果存在fit变量中
> fit <- rpart(formula,method='anova',data=bodyfat)
# 直接调用fit可以看到结果
> fit
n= 71
node), split, n, deviance, yval
* denotes terminal node
1) root 71 8535.98400 30.78282
2) waistcirc< 88.4 40 1315.35800 22.92375
4) hipcirc< 96.25 17 285.91370 18.20765 *
5) hipcirc>=96.25 23 371.86530 26.40957
10) waistcirc< 80.75 13 117.60710 24.13077 *
11) waistcirc>=80.75 10 98.99016 29.37200 *
3) waistcirc>=88.4 31 1562.16200 40.92355
6) hipcirc< 109.9 13 136.29600 35.27846 *
7) hipcirc>=109.9 18 712.39870 45.00056 *
# 也可以用画图方式将结果表达得更清楚一些
> draw.tree(fit) 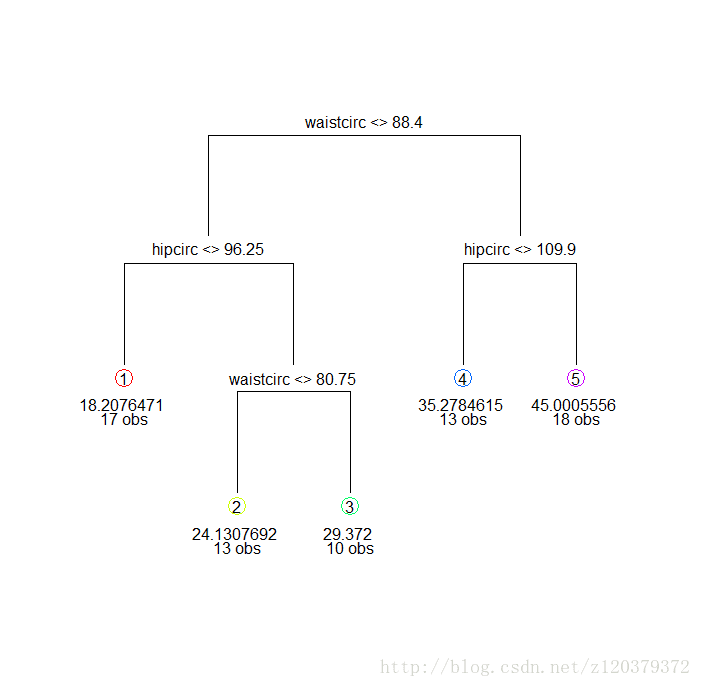
建立树模型要权衡两方面问题,一个是要拟合得使分组后的变异较小,另一个是要防止过度拟合,而使模型的误差过大,前者的参数是CP,后者的参数是Xerror。所以要在Xerror最小的情况下,也使CP尽量小。如果认为树模型过于复杂,我们需要对其进行修剪。
# 首先观察模型的误差等数据
> printcp(fit)
Regression tree:
rpart(formula = formular, data = bodyfat, method = "anova")
Variables actually used in tree construction:
[1] hipcirc waistcirc
Root node error: 8536/71 = 120.23
n= 71
CP nsplit rel error xerror xstd
1 0.662895 0 1.00000 1.04709 0.168405
2 0.083583 1 0.33710 0.41940 0.098511
3 0.077036 2 0.25352 0.43022 0.086202
4 0.018190 3 0.17649 0.31948 0.065217
5 0.010000 4 0.15830 0.27572 0.064809
# 调用CP(complexity parameter)与xerror的相关图,一种方法是寻找最小xerror点所对应的CP值,并由此CP值决定树的大小,另一种方法是利用1SE方法,寻找xerror+SE的最小点对应的CP值。
> plotcp(fit)
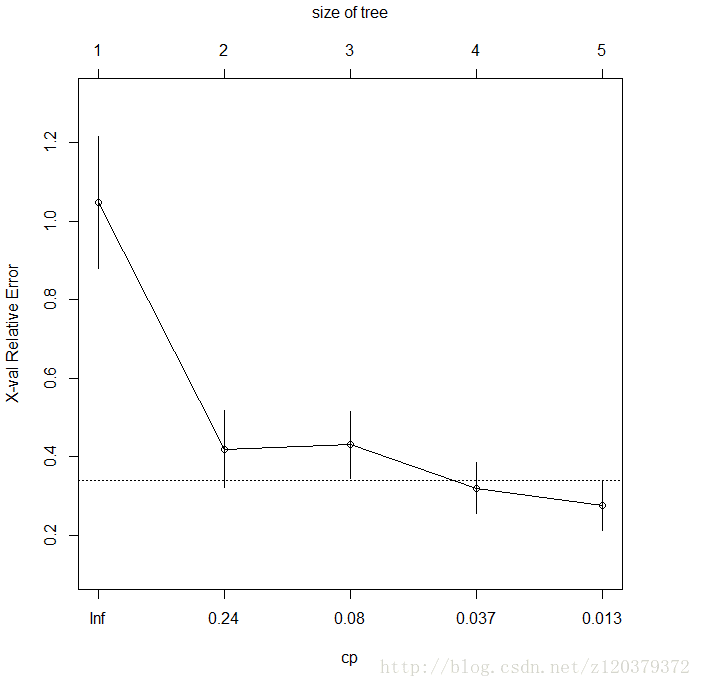
# 用prune命令对树模型进行修剪(本例的树模型不复杂,并不需要修剪)
pfit=prune(fit,cp=fit$cptable[which.min(fit$cptable[,"xerror"]),"CP"])
# 模型初步解释:腰围和臀围较大的人,肥胖程度较高,而其中腰围是最主要的因素。
# 利用模型预测某个人的肥胖程度
> ndata=data.frame(waistcirc=99,hipcirc=110,elbowbreadth=6,kneebreadth=8,
age=60)
> predict(fit,newdata=ndata)
# 本文主要参考了Yanchang Zhao的文章:“R and Data Mining: Examples and Case Studies”本文转载至:数据科学与R语言
本文转载至:我爱机器学习