走进opencv-python3 图像放缩平移
前言
本节将要介绍颜色空间变换、图像放缩、平移。旋转以及图像阈值处理
1.颜色空间变换
我们常用两种颜色转换空间的flag:BRG-GRAY,BRG-HSV。HSV颜色空间就是电视颜色设置里面的色彩、饱和度和亮度。
只需要调用函数cv2.cvtCOLOR(img,flag)
img = cv2.imread('F:/kaggle/kaggle-heart/longmao.png')
img = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)#转换成灰度图
cv2.imshow('gray',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
2.物体追踪
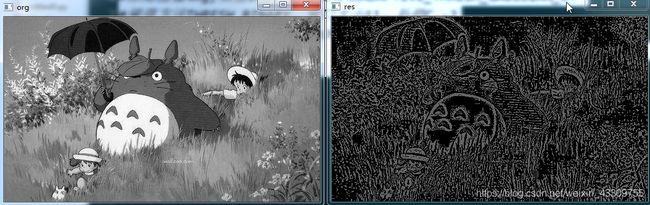
现在我们知道怎样将一幅图像从 BGR 转换到 HSV 了,我们可以利用这一点来提取带有某个特定颜色的物体。在 HSV 颜色空间中要比在 BGR 空间中更容易表示一个特定颜色。下面程序中,提取图片中的绿色。下面就是就是我们要做的几步:
• 加载图像
• 将图像转换到 HSV 空间
• 设置 HSV 阈值到绿色范围的mask
• 根据mask对原图像按位和
img = cv2.imread('F:/kaggle/kaggle-heart/longmao.png')
cv2.imshow('org',img)
hsv = cv2.cvtColor(img,cv2.COLOR_BGR2HSV)
downgreen = np.array([35,43,46])
upgreen = np.array([77,255,255])
mask = cv2.inRange(hsv,downgreen,upgreen)
res = cv2.bitwise_and(img,img,mask=mask)
cv2.imshow('res',res)
cv2.waitKey(0)
cv2.destroyAllWindows()效果如下:
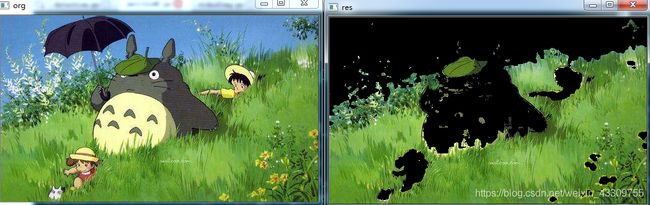
怎样找到要跟踪对象的 HSV 值呢,例如上例中绿色HSV范围?可以直接百度,或是利用如下代码:
green = np.uint8([[[0,255,0]]])
hsv_green = cv2.cvtColor(green,cv2.COLOR_BGR2HSV)
print(hsv_green)3.图片放缩
调用cv2.resize()可以实现放缩。图像的尺寸可以自己手动设置,你也可以指定缩放因子。可以选择使用不同的插值方法。在缩放时我们推荐使用 cv2.INTER_AREA,在扩展时我们推荐使用 v2.INTER_CUBIC(慢) 和 v2.INTER_LINEAR。默认情况下所有改变图像尺寸大小的操作使用的插值方法都是 cv2.INTER_LINEAR。方法如下:
img = cv2.imread('F:/kaggle/kaggle-heart/longmao.png')
cv2.imshow('org',img)
heigh,width = img.shape[:2]
#法1 缩放因子 None原为输出图像大小,如果指定缩放因子,设置为None
#放大4倍,插值方式为INTER_LINEAR
#imgX2 = cv2.resize(img,None,fx=2,fy=2,interpolation=cv2.INTER_LINEAR)
#法2 自己指定放缩后图片大小,注意缩放时要使用int取整
imgX2 = cv2.resize(img,(2*width,2*heigh),interpolation=cv2.INTER_LINEAR)
cv2.imshow('res',imgX2)
cv2.waitKey(0)
cv2.destroyAllWindows()4.图像平移
平移就是将对象换一个位置。如果你要沿(x,y)方向移动,移动的距离是(t x ,t y ),以下面的方式构建移动矩阵:
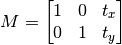
使用 Numpy 数组构建这个矩阵(数据类型是 np.float32),然后把它传给函数 cv2.warpAffine()
img = cv2.imread('F:/kaggle/kaggle-heart/longmao.png')
cv2.imshow('org',img)
heigh,width = img.shape[:2]
#右移50,下移100
M = np.float32([[1,0,50],[0,1,100]])
#cv2.warpAffine 接收的参数是2 × 3 的变换矩阵,注意输出图像格式为(width,heigh)
res = cv2.warpAffine(img,M,(width,heigh))
cv2.imshow('res',res)
cv2.waitKey(0)
cv2.destroyAllWindows()效果:

5.图像旋转
对一个图像旋转角度 θ, 需要使用到下面形式的旋转矩阵。
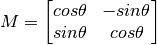
但是 OpenCV 允许你在任意地方进行旋转,但是旋转矩阵的形式应该修
改为
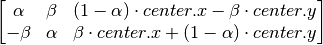
利用cv2.getRotationMatrix2D 来完成这个旋转矩阵
heigh,width = img.shape[:2]
#参数分别为旋转中心,旋转角,缩放因子
M = cv2.getRotationMatrix2D((width/2,heigh/2),45,0.5)
res = cv2.warpAffine(img,M,(width,heigh))效果:

6.仿射变换
在仿射变换中,原图中所有的平行线在结果图像中同样平行。为了创建这个矩阵我们需要从原图像中找到三个点以及他们在输出图像中的位置。然后cv2.getAffineTransform 会创建一个 2x3 的矩阵,最后这个矩阵会被传给函数 cv2.warpAffine。
#变换前位置
pts1 = np.float32([[50,50],[200,50],[100,50]])
#变换后位置
pts2 = np.float32([[10,100],[200,50],[100,250]])
M = cv2.getAffineTransform(pts1,pts2)
res = cv2.warpAffine(img,M,(width,heigh))7、视角变换
对于视角变换,我们需要一个 3x3 变换矩阵。在变换前后直线还是直线。要构建这个变换矩阵,你需要在输入图像上找 4 个点,以及他们在输出图像上对应的位置。这四个点中的任意三个都不能共线。这个变换矩阵可以调用cv2.getPerspectiveTransform() 。然后把这个矩阵传给函数cv2.warpPerspective。
pts1 = np.float32([[56,65],[368,52],[28,387],[389,390]])
pts2 = np.float32([[0,0],[300,0],[0,300],[300,300]])
#构建3x3变换矩阵
M = cv2.getPerspectiveTransform(pts1,pts2)
#接受3x3变换矩阵
res = cv2.warpPerspective(img,M,(width,heigh))
8、图像阈值
1 简单阈值
cv2.threshhold()。第一个参数就是原图像,原图像应该是灰度图。第二个参数就是用来对像素值进行分类的阈值。第三个参数就是当像素值高于(有时是小于)阈值时应该被赋予的新的像素值。OpenCV提供了多种不同的阈值方法,这是有第四个参数来决定的。这些方法包括:
• cv2.THRESH_BINARY
• cv2.THRESH_BINARY_INV
• cv2.THRESH_TRUNC
• cv2.THRESH_TOZERO
• cv2.THRESH_TOZERO_INV
这个函数有两个返回值,第一个为 retVal,即我们设置的阈值。第二个就是阈值化之后的结果图像了。
img = cv2.imread('F:/kaggle/kaggle-heart/longmao.png',0)
cv2.imshow('org',img)
#原始图像img 阈值100 赋值255 方法THRESH_BINARY
ret,thresh = cv2.threshold(img,100,255,cv2.THRESH_BINARY)
print(ret)
cv2.imshow('res',thresh)
cv2.waitKey(0)
cv2.destroyAllWindows()效果:

2 自适应阈值
上例的cv2.threshold()整幅图像采用同一个数作为阈值。这种方法简单粗暴,并不适应与所有情况,尤其是当同一幅图像上的不同部分的具有不同亮度时。这种情况下需要采用自适应阈值。此时的阈值是根据图像上的每一个小区域计算与其对应的阈值。因此在同一幅图像上的不同区域采用的是不同的阈值,从而使我们能在亮度不同的情况下得到更好的结果。
这种方法需要我们指定三个参数,返回值只有一个。
• Adaptive Method- 指定计算阈值的方法。
– cv2.ADPTIVE_THRESH_MEAN_C:阈值取自相邻区域的平均值
– cv2.ADPTIVE_THRESH_GAUSSIAN_C:阈值取值相邻区域的加权和,权重为一个高斯窗口。
• Block Size - 邻域大小(用来计算阈值的区域大小)。
• C - 这就是是一个常数,阈值就等于的平均值或者加权平均值减去这个常数。
#原始图像img,赋值100,自适应方法ADAPTIVE_THRESH_GAUSSIAN_C,
#阈值方法THRESH_BINARY,窗口大小11,补偿C -2
thresh = cv2.adaptiveThreshold(img,100,
cv2.ADAPTIVE_THRESH_GAUSSIAN_C,
cv2.THRESH_BINARY,11,-2)效果:
3、Otsu’ ’s 二值化
在cv2.threshold(),随便给了一个数来做阈值,如何这个数的好坏呢?答案就是不停的尝试。如果是一副双峰图像(简单来说双峰图像是指图像直方图中存在两个峰)呢?最好的阈值应该在两个峰之间的峰谷选一个值?这就是 Otsu 二值化要做的。简单来说就是对一副双峰图像自动根据其直方图计算出一个阈值。(对于非双峰图像,这种方法得到的结果可能会不理想)。
方法只需在 cv2.threshold()中多传入一个参数(flag):cv2.THRESH_OTSU。这时要把阈值设为 0。然后算法会找到最优阈值,这个最优阈值就是返回值 retVal。如果不使用 Otsu 二值化,返回的retVal 值与设定的阈值相等。
ret,thresh = cv2.threshold(img,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU)
print(ret)参考资料:http://www.cnblogs.com/Undo-self-blog/p/8434906.html