sklearn-数据处理(菜菜)
数据处理
-
- 数据无量纲化
-
- preprocessing.MinMaxScaler
- preprocessing.StandardScaler
- StandardScaler和MinMaxScaler选哪个?
- 缺失值
-
- 用Pandas和Numpy进行填补其实更加简单
- 处理分类型特征:编码与哑变量
-
- preprocessing.LabelEncoder:标签专用,能够将分类转换为分类数值
- preprocessing.OrdinalEncoder:特征专用,能够将分类特征转换为分类数值
- preprocessing.OneHotEncoder:独热编码,创建哑变量
今天用jupter写代码了,有点不习惯呢,有个小问题一直不对,查了 把代码单元分割的快捷键,咋整也不对,原来是用(Ctrl和Shift和“-”号),我少了个‘-’号【捂脸】,这是所有快捷键的功能: Jupyter Notebook 的快捷键.欢迎观看
1 . 获取数据
2. 数据预处理
数据预处理是从数据中检测,纠正或删除损坏,不准确或不适用于模型的记录的过程
可能面对的问题有:数据类型不同,比如有的是文字,有的是数字,有的含时间序列,有的连续,有的间断。
也可能,数据的质量不行,有噪声,有异常,有缺失,数据出错,量纲不一,有重复,数据是偏态,数据量太
大或太小
数据预处理的目的:让数据适应模型,匹配模型的需求
3 . 特征工程:
特征工程是将原始数据转换为更能代表预测模型的潜在问题的特征的过程,可以通过挑选最相关的特征,提取
特征以及创造特征来实现。其中创造特征又经常以降维算法的方式实现。
可能面对的问题有:特征之间有相关性,特征和标签无关,特征太多或太小,或者干脆就无法表现出应有的数
据现象或无法展示数据的真实面貌
特征工程的目的:1) 降低计算成本,2) 提升模型上限
4 . 建模,测试模型并预测出结果
5 . 上线,验证模型效果
数据无量纲化
在机器学习算法实践中,我们往往有着将不同规格的数据转换到同一规格,或不同分布的数据转换到某个特定分布的需求,这种需求统称为将数据“无量纲化”。譬如梯度和矩阵为核心的算法中,譬如逻辑回归,支持向量机,神经网络,无量纲化可以加快求解速度;而在距离类模型,譬如K近邻,K-Means聚类中,无量纲化可以帮我们提升模型精度,避免某一个取值范围特别大的特征对距离计算造成影响。(一个特例是决策树和树的集成算法们,对决策树我们不需要无量纲化,决策树可以把任意数据都处理得很好。)
数据的无量纲化可以是线性的,也可以是非线性的。线性的无量纲化包括中心化(Zero-centered或者Mean-subtraction)处理和缩放处理(Scale)。
中心化的本质是让所有记录减去一个固定值,即让数据样本数据平移到某个位置。缩放的本质是通过除以一个固定值,将数据固定在某个范围之中,取对数也算是一种缩放处理
preprocessing.MinMaxScaler
当数据(x)按照最小值中心化后,再按极差(最大值 - 最小值)缩放,数据移动了最小值个单位,并且会被收敛到[0,1]之间,而这个过程,就叫做数据归一化(Normalization,又称Min-Max Scaling)。注意,Normalization是归一化,不是正则化,真正的正则化是regularization,不是数据预处理的一种手段。归一化之后的数据服从正态分布,公式如下:

在sklearn当中,我们使用preprocessing.MinMaxScaler来实现这个功能。MinMaxScaler有一个重要参数,feature_range,控制我们希望把数据压缩到的范围,默认是[0,1]
from sklearn.preprocessing import MinMaxScaler
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
import pandas as pd
pd.DataFrame(data)#变成表
#实现归一化
scaler = MinMaxScaler() #实例化
scaler = scaler.fit(data) #fit,在这里本质是生成min(x)和max(x)
result = scaler.transform(data) #通过接口导出结果
#result_ = scaler.fit_transform(data) #训练和导出结果一步达成
result
scaler.inverse_transform(result) #将归一化后的结果逆转,又变成原来的了
#使用MinMaxScaler的参数feature_range实现将数据归一化到[0,1]以外的范围中
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
scaler = MinMaxScaler(feature_range=[5,10]) #依然实例化
result=scaler.fit_transform(data)
result
#当X中的特征数量非常多的时候,fit会报错并表示,数据量太大了我计算不了
#此时使用partial_fit作为训练接口
#scaler = scaler.partial_fit(data)
preprocessing.StandardScaler
当数据(x)按均值(μ)中心化后,再按标准差(σ)缩放,数据就会服从为均值为0,方差为1的正态分布(即标准正态分布),而这个过程,就叫做数据标准化(Standardization,又称Z-score normalization),公式如下

from sklearn.preprocessing import StandardScaler
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
scaler=StandardScaler()
scaler.fit(data)
scaler.mean_#查看均值的属性mean_
scaler.var_#查看方差的属性var_
x_std=scaler.transform(data)
x_std.mean()#查看均值
x_std.var()#查看方差
scaler.fit_transform(data) #也可以用fit_transform(data)一步达成结果
scaler.inverse_transform(x_std) #也可以使用inverse_transform逆转标准化
StandardScaler和MinMaxScaler选哪个?
看情况。大多数机器学习算法中,会选择StandardScaler来进行特征缩放,因为MinMaxScaler对异常值非常敏感。在PCA,聚类,逻辑回归,支持向量机,神经网络这些算法中,StandardScaler往往是最好的选择。
MinMaxScaler在不涉及距离度量、梯度、协方差计算以及数据需要被压缩到特定区间时使用广泛,比如数字图像
处理中量化像素强度时,都会使用MinMaxScaler将数据压缩于[0,1]区间之中。
建议先试试看StandardScaler,效果不好换MinMaxScaler。
除了StandardScaler和MinMaxScaler之外,sklearn中也提供了各种其他缩放处理(中心化只需要一个pandas广播一下减去某个数就好了,因此sklearn不提供任何中心化功能)。比如,在希望压缩数据,却不影响数据的稀疏性时(不影响矩阵中取值为0的个数时),我们会使用MaxAbsScaler;在异常值多,噪声非常大时,我们可能会选用分位数来无量纲化,此时使用RobustScaler。更多详情请参考以下列表。
缺失值
机器学习和数据挖掘中所使用的数据,永远不可能是完美的。很多特征,对于分析和建模来说意义非凡,但对于实际收集数据的人却不是如此,因此数据挖掘之中,常常会有重要的字段缺失值很多,但又不能舍弃字段的情况。因此,数据预处理中非常重要的一项就是处理缺失值。

import pandas as pd
data=pd.read_csv(r"E:\Narrativedata.csv" ,index_col=0 )
#index_col如果不写会把原来的索引当成特征,新生成一列索引
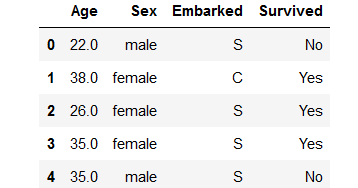
data.head()
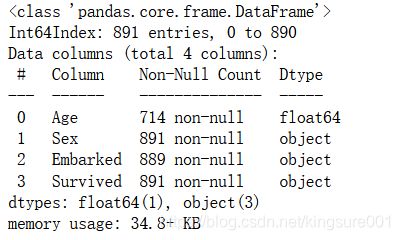
data.info()
#填补年龄
Age=data.loc[:,"Age"].values.reshape(-1,1) #loc:取出age这值和索引,values:取出值,reshape变成二维,sklearn当中特征矩阵必须是二维
Age[:20]#取出前20个,默认从0开始
from sklearn.impute import SimpleImputer
imp_mean=SimpleImputer()#实例化,默认均值填补
imp_median=SimpleImputer(strategy="median") #用中位数填补
imp_0=SimpleImputer(strategy="constant",fill_value=0)#用0填补
imp_mean=imp_mean.fit_transform(Age)
imp_median=imp_median.fit_transform(Age)
imp_0=imp_0.fit_transform(Age)
imp_mean[:20]
imp_median[:20]
imp_0[0:20]
data.loc[:,"Age"]=imp_median#在这里用中位数
data.info()
用Pandas和Numpy进行填补其实更加简单
#用众数填Embarked
Embarked=data.loc[:,"Embarked"].values.reshape(-1,1)
imp_mode=SimpleImputer(strategy="most_frequent")
data.loc[:,"Embarked"]=imp_mode.fit_transform(Embarked)
data.info()
import pandas as pd
data_=pd.read_csv(r"E:\Narrativedata.csv" ,index_col=0 )
#index_col如果不写会把原来的索引当成特征,新生成一列索引
data_.head()
data_.loc[:,"Age"]=data_.loc[:,"Age"].fillna(data_.loc[:,"Age"].median())
#fillna在DataFrame中直接填空值
data_.loc[:,"Age"]
data_.dropna(axis=0,inplace=True)
#.dropna(axis=0)删除所有有缺失值的行,.dropna(axis=1)删除所有有缺失值的列
#参数inplace,为True表示在原数据集上进行修改,为False表示生成一个复制对象,不修改原数据,默认False
data_.info()
处理分类型特征:编码与哑变量
在机器学习中,大多数算法,譬如逻辑回归,支持向量机SVM,k近邻算法等都只能够处理数值型数据,不能处理文字,在sklearn当中,除了专用来处理文字的算法,其他算法在fit的时候全部要求输入数组或矩阵,也不能够导入文字型数据(其实手写决策树和普斯贝叶斯可以处理文字,但是sklearn中规定必须导入数值型)。然而在现实中,许多标签和特征在数据收集完毕的时候,都不是以数字来表现的。比如说,学历的取值可以是[“小学”,“初中”,“高中”,“大学”],付费方式可能包含[“支付宝”,“现金”,“微信”]等等。在这种情况下,为了让数据适应算法和库,我们必须将数据进行编码,即是说,将文字型数据转换为数值型。
preprocessing.LabelEncoder:标签专用,能够将分类转换为分类数值
from sklearn.preprocessing import LabelEncoder
LabelEncoder().fit(data.iloc[:,1:-1]).classes_#属性.classes_查看标签中究竟有多少类别
data.iloc[:,-1]=LabelEncoder().fit_transform(data.iloc[:,-1])
data.head()
preprocessing.OrdinalEncoder:特征专用,能够将分类特征转换为分类数值
from sklearn.preprocessing import OrdinalEncoder
data_ = data.copy()
data_.head()
OrdinalEncoder().fit(data_.iloc[:,1:-1]).categories_#查看分类,接口categories_对应LabelEncoder的接口classes_,一模一样的功能
data_.iloc[:,1:-1] = OrdinalEncoder().fit_transform(data_.iloc[:,1:-1])
data_.head()
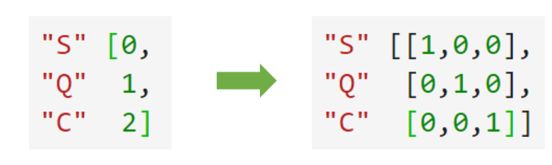
preprocessing.OneHotEncoder:独热编码,创建哑变量
我们刚才已经用OrdinalEncoder把分类变量Sex和Embarked都转换成数字对应的类别了。在舱门Embarked这一列中,我们使用[0,1,2]代表了三个不同的舱门,然而这种转换是正确的吗?
我们来思考三种不同性质的分类数据:
1) 舱门(S,C,Q)
三种取值S,C,Q是相互独立的,彼此之间完全没有联系,表达的是S≠C≠Q的概念。这是名义变量。
2) 学历(小学,初中,高中)
三种取值不是完全独立的,我们可以明显看出,在性质上可以有高中>初中>小学这样的联系,学历有高低,但是学
历取值之间却不是可以计算的,我们不能说小学 + 某个取值 = 初中。这是有序变量。
3) 体重(>45kg,>90kg,>135kg)
各个取值之间有联系,且是可以互相计算的,比如120kg - 45kg = 90kg,分类之间可以通过数学计算互相转换。这是有距变量。
然而在对特征进行编码的时候,这三种分类数据都会被我们转换为[0,1,2],这三个数字在算法看来,是连续且可以计算的,这三个数字相互不等,有大小,并且有着可以相加相乘的联系。所以算法会把舱门,学历这样的分类特征,都误会成是体重这样的分类特征。这是说,我们把分类转换成数字的时候,忽略了数字中自带的数学性质,所以给算法传达了一些不准确的信息,而这会影响我们的建模。类别OrdinalEncoder可以用来处理有序变量,但对于名义变量,我们只有使用哑变量的方式来处理,才能够尽量向算法传达最准确的信息
from sklearn.preprocessing import OneHotEncoder
enc= OneHotEncoder(categories='auto').fit(data.iloc[:,1:-1])
result=enc.transform(data.iloc[:,1:-1]).toarray()#toarray()返回数组
result
# OneHotEncoder(categories='auto').fit_transform(data.iloc[:,1:-1]).toarray() #一步到位

enc.inverse_transform(result)#还原
enc.get_feature_names() #转换特征的名字

![]()
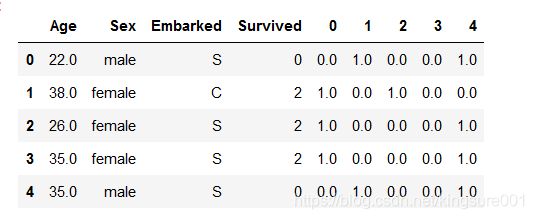
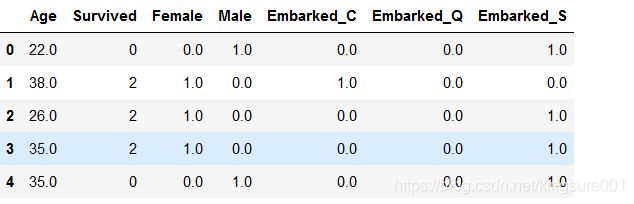
result.shapenewdata=pd.concat([data,pd.DataFrame(result)],axis=1) # np.concat:将data和result合并
#axis=1,表示跨行(按列)进行合并,也就是将两表左右相连,如果是axis=0,就是将两表上下相连
newdata.head()
newdata.drop(["Sex","Embarked"],axis=1,inplace=True) #删除名为"Sex","Embarked"的这两列(axis=1),inplace=True覆盖原数据
newdata.columns=["Age","Survived","Female","Male","Embarked_C","Embarked_Q","Embarked_S"] #添加列索引的名字
newdata.head()
附:
Pandas中loc和iloc函数区别:
loc函数:通过行索引 “Index” 中的具体值来取行数据(取"Index"为"A"的行)
iloc函数:通过行号来取行数据(如取第二行的数据)