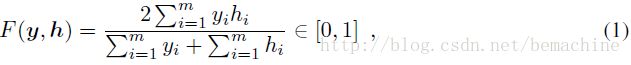多标签分类问题
1、multilabel classification的用途
多标签分类问题很常见, 比如一部电影可以同时被分为动作片和犯罪片, 一则新闻可以同时属于政治和法律,还有生物学中的基因功能预测问题, 场景识别问题,疾病诊断等。
2. 单标签分类
在传统的单标签分类中,训练集中的每一个样本只有一个相关的标签 l ,这个标签来自于一个不重合的标签集合L,|L| > 1.当|L|=2 时,这就是一个二分类问题,或文本和网页数据的过滤(filtering)问题。当|L| > 2 时是多分类问题。
3、多标签分类问题的定义
简单的说就是同一个实例,可以有多个标签, 或者被分为多个类。和多分类的区别是, 多分类中每个实例只有一个标签。下面是几个形式化的定义。
用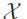 代表样本空间,
代表样本空间,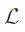 =
=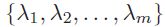 为有限标签集合, 我们假设中的样本实例
为有限标签集合, 我们假设中的样本实例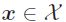 和的一个子集
和的一个子集 相关,这个子集称作相关标签集。同时补集
相关,这个子集称作相关标签集。同时补集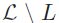 被认为与x不相关。相关标签集L用向量
被认为与x不相关。相关标签集L用向量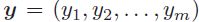 标识,其中
标识,其中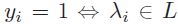 。用
。用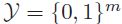 表示可能的标签集。
表示可能的标签集。
一个多标签分类器h是一个映射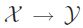 ,对每一个实例
,对每一个实例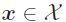 分配一个分配一个标签子集。因此分类器h的输出是一个向量
分配一个分配一个标签子集。因此分类器h的输出是一个向量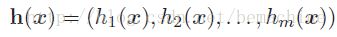 。
。
4、与多标签分类相关/相似的问题
一个同属于监督学习并和多标签分类很相关的问题就是排序问题(ranking)。排序任务是对一个标签集排序,使得排在前面的标签与相应实例更相关。
在特定分类问题中,标签属于一个层次结构(hierarchical structure)。当数据集标签属于一个层次结构的时候,我们这个任务为层次分类,如果一个样本与层次结构的多个节点相关, 那么这个任务就被称为层次多标签分类。
多实例学习(multiple-instance learning)是监督学习的一个变种,用的比较少 ,就不说了。
5. 多标签分类的方法
方法基本上分为两种,一种是将问题转化为传统的分类问题,二是调整现有的算法来适应多标签的分类
多标签学习算法分为量大类:
1)改造数据适应算法
2)改造算法适应数据
1 改造数据
(1)二分类
用L个分类器,分别对应L个标签,进行训练。
(2)标签排序+二分类
利用“成对比较”(pairwise comparison),获得L(L-1)/2个分类器,然后利用投票,得到标签的排序。接着,利用二分类,补充标签排序的投票结果,提高准确性。
(3)随机k标签
从L个标签随机取得k个标签,重复n次,获得n个分类器。这个过程有点类似随机森林。然后利用多类分类器(multi-class,与multi-label是有区别的),训练数据,最后通过投票,如果对于某一标签,其实际获得的投票数占到最大可能的投票数一半以上,那么就认为当前实例属于该标签。
实验中,通常k设为3,n设为2L。
举个例子:
【数据集】
x1, (l1,l2,l3)
x2, (l1,l2)
x3, (l2,l4)
当前数据集,总共标签数为4个,那么所有标签组合为24=16。将((l1,l2,l3))转为新类l1’,(l1,l2)转为一个新类l2’,(l2,l4)转为一个新类l3’,得到3个新类,这样就能利用多类分类器训练转换后的数据集。
2 改造算法
(1)ML-knn
机器学习-k最近邻
首先,利用knn获得未知实例x的k个近邻。针对标签j,在该k个近邻中出现cj次。
其次,利用条件概率,判断x赋予标签j的可能性。假设hj表示x属于标签j事件,¬hj表示x不属于标签j事件。那么假定x要属于标签j,需要满足:
P(hj|cj)/P(¬hj|cj)>1




(2)RankSVM
用wj和wk分别代表标签j和k的权重,按照类似排序的算法,在标签中,以相关或不相关作为判断。假定实例x与标签j相关,与标签k不相关,那就会转换成新的标签1;反之,就会转换成新的标签-1。


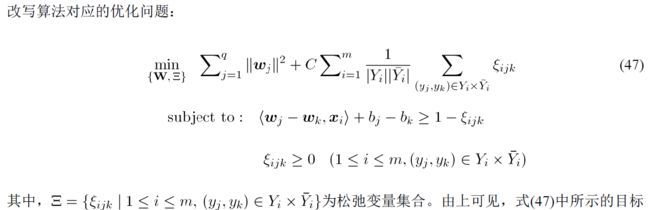

3 评价指标
目前并不存在适用于所有问题的“通用的(general-purpose)”多标记评价指标,其选择依赖于具体的学习任务。例如,对于“分类(classification)”任务而言,采用基于样本的评价指标如hamming loss可能比较合适;而对于“检索(retrieval)”任务而言,采用基于类别的评价指标如micro-averaged precision 可能比较合适。
(1)hamming loss
采用预测的标签集合与实际的标签集合按汉明距离的相似度来衡量。汉明距离值越小说明越相似,即hamming loss越小,从而学习系统的性能越好。
(2)micro-averaging

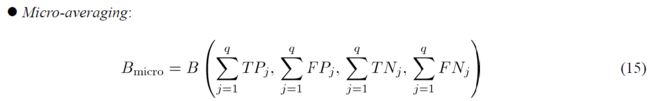
(3)ranking loss

7、 一点感悟
多标签学习,还有层次结构学习等,多个标签之间一般不是独立(independent)的,所以好的算法要利用标签之间的依赖
算法训练的时候要么降低cost function 要么学习贝叶斯概率,两种方法本质一样,但表现形式不一样
8. 其它
F-measure能比较好的平衡分类器对不同类别实例不同时在不同类上的表现,因此更适合于不平衡的数据。对一个m维二元标签向量 ,对给定的预测,F-measure定义为:
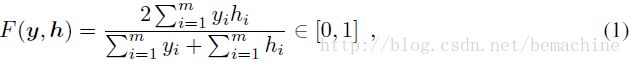 其中由定义,0/0=1
其中由定义,0/0=1
F-measure对应于精度和召回的调和平均。