红象云腾Redoop Enterprise CRH V5.0的五大过人之处
Hadoop,这个由Apache基金会所开发的分布式系统基础架构近些年来得益于其自身在数据提取、变形和加载(ETL)方面上的天然优势,得以在大数据处理应用中得到广泛的应用,但Hadoop毕竟是成长于国外的环境和土壤中,在国内应用多少会有些“水土不服”,为此,国内不少软件厂商基于Apache Hadoop积极开发适合于国内应用的大数据处理平台,而红象云腾就是其中较为出色的一家。作为一家成长自开源社区的纯粹的中国软件厂商,红象云腾的目标就是成为中国的Hadoop,而红色大象的Logo,则表面了红象云腾要达成这一目标的决心。同时,为了更专注于大数据核心底层技术的研发和产品化,让看起来“高大上”的大数据趋于平民化,今年年初,红象云腾将RedHadoop品牌正式升级为REDOOP,在坚持走自主创新的同时,以开放的心态,与广大合作伙伴一起构建大数据应用生态,让大数据应用落地。

6月30日,在“共建大数据合作生态研讨会暨红象云腾2017新品发布会”上,红象云腾宣布获得由国家新兴产业引导基金参股的华耀资本1000万Pre-A 投资,红象云腾在此次大会上,也宣布了将与众多合作伙伴合力打造开放协作的大数据生态,争取在十年内实现市值百亿级营收的宏伟目标。
而要实现这样的目标,当然需要有过硬的产品,为此,在此次大会上,红象云腾推出了里程碑式的产品——全球唯一支持五种芯片的大数据基础平台产品Redoop Enterprise CRH V5.0。那么,这款承载着红象云腾众多期许的产品到底有何过人之处?下面就由老孙来给大家详细解读CRH V5.0的五大过人之处。
一、100%开源、安全、可靠、易用
CRH V5.0提供企业级Hadoop发行版,100%开源,生命力持久、功能更新迭代快速,并经过严格的测试和大规模的商业化验证,具有很高的稳定性,由于采用标准的API(JAVA,SQL,Python,Rest,R,Scala)和标准的工具集成(PowerBI,Tableau,Qlink,Zeppelin,RStudio)以及高度可视化的操作,CRH V5.0给用户提供了一个简单易用的一站式管理解决方案。
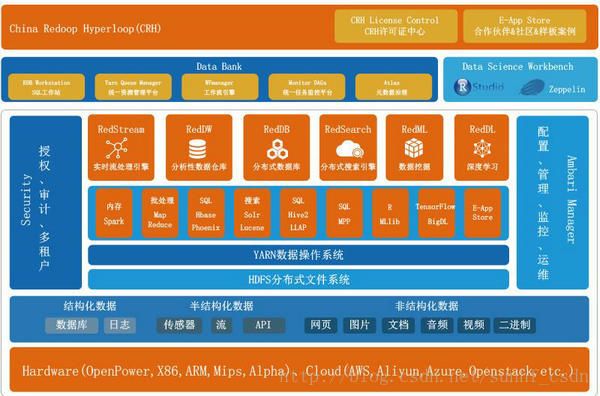
同时,基于企业安全标准集成、统一的访问安全控制和内置的数据安全,CRH V5.0在安全性上也非常出色,再加上集部署、管理、监控、告警、监控和审计的一体化的管理系统,以及日志聚合分析、数据治理、灵活的CRH-LICENSE控制,CRH V5.0不仅为用户提供了高效的可管理、可治理性,也为用户提供了足够的商业灵活性。
二、跨平台、全球唯一支持五大CPU
CRH具有广泛的跨平台性,支持X86、Power、ARM、MIPS、Alpha五大主流硬件架构,同时支持飞腾、Intel X86、OPENPOWER等多种芯片。并与浪潮,中太,航天科工飞腾等国产服务器进行过兼容性测试,支持红旗、中标麒麟、银河麒麟等多种国产服务器操作系统。
CRH V5.0同时支持FPGA/GPU硬件加速压缩编码和解码,能够大幅度提升大数据应用性能,并迅速提升运行效率。同时还支持Tensorflow/Caffe+Hadoop/Spark的深度学习RedDL平台,为客户模型训练提供深度学习能力。
三、八大应用级产品
红象大数据平台核心产品围绕HDFS存储和Yarn调度展开,上层应用场景在原有的(RedStream、RedDW、RedDB、RedSearch、RedML)基础上,新增分布式深度学习平台RedDL、可视化数据科学工作台Data Science Workbench、数据管理平台DataBank,合作伙伴生态软件E-AppStore,E-AppStore平台和社区高度协作,提供稳定可靠的接口来无缝融合更多大数据生态的软件产品,使得CRH成为一个多功能的数据分析平台,更多的第三方合作伙伴软件将出现在E-AppStore中,让CRH可以在更多的数据分析场景帮助客户解决问题。此外,升级后的CRH许可证中心,可以帮助合作伙伴更加灵活的控制集群。
RedDW
RedDW是一个分布式分析型数据库引擎,接口与Hive完全兼容,使用Hive的用户可以完全无缝迁移RedDW,并且可以获得10-20x倍性能提升,RedDW拥有Hive2的完整支持同时完全替换底层MR引擎,转而支持MPP架构,让RedDW拥有跟MPP数据库一样的性能,同时集群规模比MPP大几十倍。RedDW中首次引入 LLAP(Low Latency Analytical Processing)是一个全新的架构,LLAP 引领了内存计算(而不是磁盘计算),LLAP智能的内存缓存,可通过客户端共享数据,同时在同一个集群里面还保留了弹性扩展的能力。细粒度的资源管控机制,可以让RedDW并发性能大大增强,EDW场景中RedDW从后端离线分析引擎逐渐转向直接对接各种在线报表工具,比如:PowerBI,Zeppelin,Tableau等。
RedStream
RedStream是CRH中的实时流处理引擎,此次升级后的CRH V5.0,引入友好的SQL支持,用户编写SQL就能完成流式数据分析任务,大大降低了用户开发和维护流计算程序的成本。系统的稳定性经过无数次测试,可以保证持续不断的,7*24小时的计算,可以通过增加数据partition数,减少故障,即使在硬盘损坏的情况下依然保证零数据丢失,目前支持的数据源可以从Kafka导入。RedStream支持高度灵活的流式窗口,基于内存计算引擎保证了数据分析的时效性。
Data Science Workbench
CRH V5.0在可视化方面有了全面提升,引入了一个新的产品Data Science Workbench数据科学工作台,沿用了现有社区的Zeppelin Notebook和R语言可视化产品,通过结合CRH中机器学习RedML、RedDB分布式数据库产品,数据科学家可以用熟悉的方式使用这些分布式技术,比如:R语言使用者依然可已使用他们熟悉的R Studio,底层则通过RedML平台提供的接口直接把R语言解析运行到MLlib机器学习库中,从而变成分布式训练R模型。
RedDB
RedDB分布式数据库产品,目前在存储和数据库方面红象投入了大量的研发精力,在底层核心优先保障存储层的稳定可靠。红象分布式数据库产品结合了Hbase和Phoenix的优势,为保障稳定性和可靠性做了大量反复的测试,在V5.0中发布。结合两者的优势,在数据批量导入和压缩数据上做了大量优化和改进,大大降低Hbase的使用门槛。支持通过SQL的方式来访问Hbase数据库。通过标准的ODBC/JDBC接口直接可对接主流的前端报表工具,以SQL接口对外可提供查询服务,对内可内置多级索引支持,可以高效率精准定位数据。对非结构化数据(文本,图片,音频)提供友好的支持,非常适用于大量数据实时插入的场景,也可对数据进行更新和删除操作,支持简单的ACID事物。
RedDL
在CRH V5.0中引入了新的时下流行的深度学习计算平台RedDL,底层建立在TensorFlow之上并且Yarn集成,实现统一资源调度管理。目前RedDL在CRH V5.0中还只是预览版,已经初具简单的行业应用模型,后期在E-AppStore中将会提供训练完成的模型,让客户可简单直接的开始模型的训练,大大缩短了构建模型的时间。RedDL通过Serving的方式非常方便的提交开发完成的模型算法。结果数据可以输出到HDFS或分布式数据库中,对外提供数据查询服务。
RedSearch
分布式搜索引擎RedSearch构建在lucene之上,提供分布式的数据分片存储到不同的HDFS存储节点的功能。支持大规模索引技术,并且RedSearch平台和分析型数据仓库平台无缝互相操作,可以通过SQL的方式查询搜索引擎中的数据。还可以通过标准的SQL接口,把需要搜索的文本数据直接存储到分布式数据库RedDB中,通过建立RedSearch关联,直接往RedDB中实时插入数据或者批量导入数据,同步在RedSearch自动建立索引和分词。对提供了搜索的接口,业务系统可以实时搜索到最新入库数据。比如:一键云搜索。
RedML
分布式数据挖掘平台,提供分布式的模型算法,可近似实时的完成机器学习算法的训练。为数据科学家提供他们熟悉的工作方式,直接在他们熟悉的R语言工作台编写分析程序,底层自动转换在分布式内存机器引擎上执行,目前已经支持大量主流算法的分布式执行。目前提供了Scala、Python,R语言接口,配合数据科学工作台Data Science Workbench,以高度可视化的形式直接开发数据挖掘算法模型,并且与CRH平台其他组件相互配合完成数据分析任务。
DataBank
DataBank是红象从早期1.0开始就提供的数据银行,升级后的DataBank提供5大功能模块。
▶ RedDW Workstation SQL工作站,执行交互SQL查询服务。
▶Yarn Queue Manager统一资源管理平台,通过可视化的方式控制YARN中租户所用的资源,不同租户配置不同的资源占用配比,限制不同的计算框架能使用的资源。精确的控制集群资源使用,支持动态加载配置信息,无需重启YARN集群。
▶ WFmanager工作流引擎,提供可视化的方式创建各种CRH集群数据分析任务、使CRH平台其他组件可以直接交互,支持ETL数据流的交付能力。
▶ Monitor DAGs统一任务监控平台,对集群中所有的任务提供非常细粒度的监控,包括任务执行详情,每个任务执行日志聚合,诊断问题,对RedDW引擎的执行计划以流程图的方式呈现,有助于优化执行逻辑,快速定位性能的瓶颈。
▶ Atlas元数据治理平台,提供可视化的数据血统关系,数据变更可通过lineage进行溯源和恢复,提高数据的质量。
四、全新应用商店
在CRH V5.0中提出的E-AppStore平台,让合作伙伴和社区能够和红象云腾提供的CRH产品高度协作,帮助各行个业更加高效、低成本构建企业级一站式大数据分析平台。也让CRH在未来的发展中越来越强大,为客户解决更多的现实问题,不断打磨CRH大数据平台,为需要CRH的合作伙伴带来一流的服务,实现双赢的局面。
目前E-AppStore中主要提供两类功能,一类是社区大数据生态软件,比如:基于Hadoop的融合分布式关系型数据库EsgynDB,社区开发的Kylin多维分析引擎,支持基于MPP架构的Impala数据仓库引擎。另一类是合作伙伴提供的在CRH大数据平台实现的各行业解决方案和精品行业样板案例,可以帮助合作伙伴在更多的行业提供大数据解决方案。
五、更加强大的基础平台
Ambari Manager和Security平台为CRH V5.0提供了强大的底层监控、集群管理,部署,配置版本变更回滚、自动化运维能力,在CRH V5.0中新增多租户和审计,为集群所有组件均提供强一致性的权限认证服务,为数据库表系统提供基于列级别的精细化权限控制。
其中,集群权限认证服务,提供数据库级别的权限控制能力,保障大数据集群的安全可靠,对外提供数据库查询服务的能力。支持完整的安全权限管控,所有组件支持安全访问控制,包括并不限于HDFS、Yarn、HBase、Hive、Kafka、Spark、Spark Streaming等;支持基于角色的访问权限控制;HBase支持单元格级别访问权限控制、Hive支持行级访问权限控制;提供账户服务如LDAP以及认证服务Kerberos的高可靠,支持LDAP HA以及Kerberos HA。
多租户能力,可以提供细粒度的资源管控能力,对不同的租户限制资源,动态资源调节,把大量空闲资源分配给需要资源的租户使用。计算集群可以按需创建,按需销毁;创建集群时只需要指定所需计算资源池和特定标签节点,无需指定具体物理机器。
此外,CRH底层平台软件将Hadoop升级为2.7.1,Spark支持2.1和1.6.3两个版本,Kafka 升级到0.10。CRH提供的完全开源的Hadoop发行版,紧随社区,提供稳定可靠坚如磐石的大数据平台。
目前,CRH监控能力提升,已经上线10PB的集群,为线上几百台集群提供硬件级监控,可以实时发现硬件故障,系统故障,软件故障,运维人员可及时处理故障,让运维大数据集群智能化、降低运维成本。