hadoop-wordcount本地模式及集群模式运行
前言
上一篇文章,我们利用3台云服务器搭建了一个Hadoop集群,并通过hadoop -jar命令运行了Hadoop自带的一个wordcount例子,那本片文章就通过实现一个wordcount程序,并在本地模式下运行这个程序,了解一下mapreduce编码规范,最后 再将这个jar包提交到真正的集群上运行。
Hadoop maven依赖
本想使用springboot集成的hadoop,但是发现其版本最高只集成到Hadoop2.7.3,于是乎,不适用spring boot,直接使用hadoop2.9.2的包。maven依赖如下:
org.apache.hadoop
hadoop-common
2.9.2
org.apache.hadoop
hadoop-hdfs
2.9.2
org.apache.hadoop
hadoop-client
2.9.2
log4j
log4j
1.2.14
junit
junit
4.8.2
Hadoop本地(windows环境)运行依赖
由于是本地模式运行,所以需要导入windows下的hadoop.dll和winutils.exe,否则将会抱错java.lang.UnsatisfiedLinkError:

各个版本的hadoop.dll以及winutils.exe下载地址:
https://download.csdn.net/download/wxgxgp/11072195
(CSDN资源默认需要积分,若没有积分,请在我的博客-留言板留下邮箱,将邮件发送。)
当然你也可以去github下载(这里并不包含2.9.2版本):
https://github.com/4ttty/winutils
编写MapReduce程序
由于之前对storm有所研究,所以,这次理解mapreduce还是较为容易的,关于mapreduce的原理以及解释本人不在重复造轮子,详情请看下方链接:
MapReduce工作流程最详细解释
以下内容只是从代码层面说明mapreduce注意的一些问题。
Map阶段
public class MapperTest extends Mapper {
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String[] words = value.toString().split(" ");
for(String word : words){
context.write(new Text(word),new IntWritable(1));
}
}
}
继承Mapper类即可。注意泛型参数格式为<输入key类型,输入value类型,输出key类型,输出value类型>
注意输入类型一般是文件中每一行首的偏移量。
这个程序只能统计英文单词个数,但无法统计中文词语个数,因为英文单词之间有空格分割,而中文则没有,因此若需要统计中文词语,则需要先进行分词处理,而这就属于nlp的范围了。
Reduce阶段
public class ReduceTest extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
同样的只需要继承Reducer类即可,泛型参数格式为<输入key类型,输入value类型,输出key类型,输出value类型>,注意这里的输入key和value的类型要和map阶段输出的key和value的类型一致。
整个map-reduce从代码层面看起来很简单,就是把单词根据空格分割,然后写入到contex,然后在根据相同的单词进行一个累加计数的汇总,其实更多的是Hadoop框架为我们做了大量的事情。
编写主类
public class WordCount {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
if (args == null || args.length == 0) {
args = new String[2];
args[0] = "E:/hadoop/input/test.txt";
args[1] = "E:/hadoop/output";
}
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
job.setJarByClass(WordCount.class);
job.setMapperClass(MapperTest.class);
job.setReducerClass(ReduceTest.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
Path inputPath = new Path(args[0]);
Path outputPath = new Path(args[1]);
//自动删除已存在的目录
outputPath.getFileSystem(configuration).delete(outputPath, true);
FileInputFormat.setInputPaths(job,inputPath);
FileOutputFormat.setOutputPath(job,outputPath);
boolean wait = job.waitForCompletion(true);
System.exit(wait?0:1);
}
}
运行一下:

提交到集群运行
打包jar
因为使用的是maven,所以就用maven打包jar了。
需要注意的是:
要在pom.xml中添加打包类型:
jar
添加主类:
org.apache.maven.plugins
maven-jar-plugin
test.WordCount
true
不添加主类则提交到集群后会出现找不到主类的错误。
提交到集群
将jar包上传到服务器上,执行命令:
hadoop jar hadooptest-1.0-SNAPSHOT.jar /test/input /test/output
(注意这里的路径修改为自己的,hadooptest-1.0-SNAPSHOT.jar为打包后的jar包名称,若没有在程序里设置job名称,则会默认一jar包名称作为job名称)
其中/test/input下有一个文件text.txt,其内容如下:
哈哈哈哈
a
adad
adads
asdddqwd
asda
adds
13
132
132
a

我们也可以在web界面上看到执行情况:

最后我们在web界面查看一下结果:
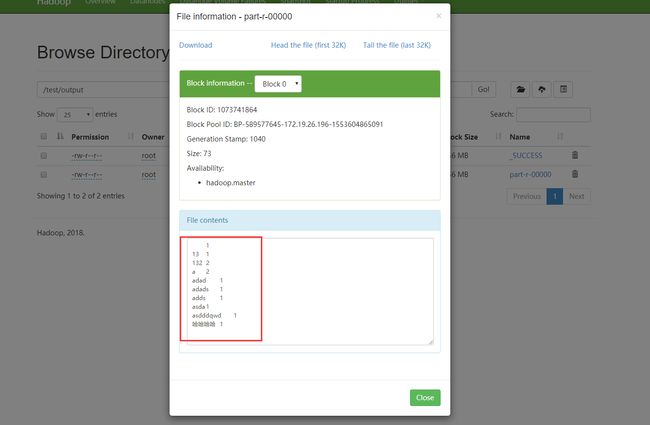
表明集群上运行成功。