Spark | SparkSql Insert Overwrite 小文件过多
SparkSql在执行Hive Insert Overwrite Table 操作时 ,默认文件生成数和表文件存储的个数有关,但一般上游表存储个数并非下游能控制的,这样的话得考虑处理小文件问题。
小文件产生原因:
spark.sql.shuffle.partitions=200 ,spark sql默认shuffle分区是200个,如果数据量比较小时,写hdfs时会产生200个小文件。
可尝试通过以下操作来解决小文件过多问题,如下
Shuffle Partition
--conf spark.sql.shuffle.partitions=10 \
--conf spark.default.parallelism=10 \目前SparkSql中reduce阶段的task个数取决于固定参数 spark.sql.shuffle.partition(默认值 200),注意,若一个作业一旦设置了该参数,它运行过程中的所有阶段的reduce个数都是同一个值。
而对于不同的作业,以及同一个作业内的不同reduce阶段,实际的数据量大小可能相差很大,例如reduce阶段要处理的数据可能是10MB,也有可能是100GB, 如果使用同一个值对实际运行效率会产生很大影响,例如10MB的数据一个task就可以解决,如果 spark.sql.shuffle.partition使用默认值200的话,那么10MB的数据就要被分成200个task处理,增加了调度开销,影响运行效率。
而spark.default.parallelism 该参数用于设置每个stage的默认task数量。
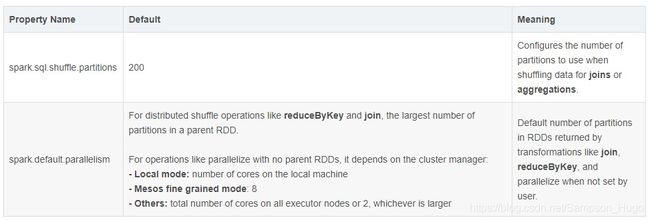
值得注意的是,
spark.default.parallelism只有在处理RDD时才会起作用,对SparkSql无效。
spark.sql.shuffle.partitions则是对sparks SQL专用的设置。
coalesce & repartition
rdd.toDF("name", "age", "address").coalesce(3).createOrReplaceTempView("tmp_table")
spark.sql("insert overwrite table t1 select name,age,address from tmp_table")
df.repartition(10).createOrReplaceTempView("tmp_table")
spark.sql("insert overwrite table t1 select name,age,address from tmp_table")coalesce 和 repartition 都是对 RDD 重新分区。 coalesce 操作使用HashPartitioner 进行重分区,第一个参数为重分区的数目,第二个为是否进行 shuffle,默认情况下是 false。
repartition 操作是 coalesce 函数第二个参数为 true 的实现。
使用 coalesce 操作 RDD 时需注意:
1)重新分区的数目需要小于原分区数据。
2)重新分区数目大于原来的分区数,那么必须制定 shuffle 参数为 true,否则分区数不变。
Distribute by 方式
distribute by是控制在map端如何拆分数据给reduce端的。hive会根据distribute by后面列,对应reduce的个数进行分发,默认是采用hash算法。大部分情况都用于解决Map输出的文件大小不均,Reduce输出文件大小不均,小文件过多,文件数过大等情况.
distribute by 控制map输出结果的分发,相同字段的map输出会发到一个reduce节点去处理;sort by为每一个reducer产生一个排序文件。cluster by = distribute by + sort by,默认只能是升序。
select name,age,address from tmp_table Distribute by name;
SparkSql自适应调整
--conf spark.sql.adaptive.enabled=true \
--conf spark.sql.adaptive.shuffle.targetPostShuffleInputSize=128000000 \SparkSQL自适应框架可以通过设置shuffle partition的上下限区间,在这个区间内对不同作业不同阶段的reduce个数进行动态调整。通过区间的设置,一方面可以大大减少调优的成本(不需要找到一个固定值),另一方面同一个作业内部不同reduce阶段的reduce个数也能动态调整。
| 属性名称 | 默认值 | 备注 |
|---|---|---|
| spark.sql.adaptive.enabled | false | 自适应执行框架的开关。 |
| spark.sql.adaptive.minNumPostShufflePartitions | 1 | reduce个数区间最小值。 |
| spark.sql.adaptive.maxNumPostShufflePartitions | 500 | reduce个数区间最大值。 |
| spark.sql.adaptive.shuffle.targetPostShuffleInputSize | 67108864 | 动态调整reduce个数的 partition 大小依据,如设置64MB,则reduce 阶段每个task最少处理 64MB的数据。 |
| spark.sql.adaptive.shuffle.targetPostShuffleRowCount | 20000000 | 动态调整reduce个数的partition条数依据,如设置20000000则reduce阶段每个task最少处理 20000000条的数据。 |
数据倾斜
Join中会经常碰到数据倾斜的场景,导致某些task处理的数据过多,出现很严重的长尾。目前SparkSQL没有对倾斜的数据进行相关的优化处理。
SparkSQL自适应框架可以根据预先的配置在作业运行过程中自动检测是否出现倾斜,并对检测到的倾斜进行优化处理。
优化的主要逻辑是对倾斜的partition进行拆分由多个task来进行处理,最后通过union进行结果合并。
支持的 Join 类型:
| join类型 | 备注 |
|---|---|
| Inner | 左/右表均可处理倾斜。 |
| Cross | 左/右表均可处理倾斜。 |
| LeftSemi | 只对左表处理倾斜。 |
| LeftAnti | 只对左表处理倾斜。 |
| LeftOuter | 只对左表处理倾斜。 |
| RightOuter | 只对右表处理倾斜。 |
参数设置:
| spark.sql.adaptive.enabled | false | 自适应执行框架的开关。 |
| spark.sql.adaptive.skewedJoin.enabled | false | 倾斜处理开关。 |
| spark.sql.adaptive.skewedPartitionFactor | 10 | 当一个 partition的size大小或大于该值(所有parititon大小的中位数) 且大于spark.sql.adaptive.skewedPartitionSizeThreshold,或者parition的条数大于该值(所有parititon条数的中位数)且大于 spark.sql.adaptive.skewedPartitionRowCountThreshold, 才会被当做倾斜的partition进行相应的处理。 |
| spark.sql.adaptive.skewedPartitionSizeThreshold | 67108864 | 倾斜的partition大小不能小于该值。 |
| spark.sql.adaptive.skewedPartitionRowCountThreshold | 10000000 | 倾斜的partition条数不能小于该值。 |
Runtime执行计划优化
SparkSQL的Catalyst优化器会将sql语句转换成物理执行计划,然后真正运行物理执行计划。但是Catalyst转换物理执行计划的过程中,由于缺少Statistics统计信息,或者Statistics统计信息不准等原因,实际转换的物理执行计划可能并不是最优的,例如转换为SortMergeJoinExec,但实际BroadcastJoin更合适。
SparkSQL自适应执行框架会在物理执行计划真正运行的过程中,动态的根据shuffle阶段shuffle write的实际数据大小,来调整是否可以用 BroadcastJoin来代替SortMergeJoin,提高运行效率。
参数:
| 属性名称 | 默认值 | 备注 |
|---|---|---|
| spark.sql.adaptive.enabled | false | 自适应执行框架的开关。 |
| spark.sql.adaptive.join.enabled | true | 开关。 |
| spark.sql.adaptiveBroadcastJoinThreshold | 等于spark.sql.autoBroadcastJoinThreshold | 运行过程中用于判断是否满足BroadcastJoin 条件 |
关于SparkSql 自适应调整最近官方正式发布了Spark3.0,新特性中有涉及到SparkSql自适应查询执行计划的优化。
更多学习:
SparkSql 自适应: https://my.oschina.net/hblt147/blog/3006406
Spark官网:http://spark.apache.org/docs/latest/configuration.html
Spark3.0: https://www.iteblog.com/archives/9754.html