假设检验实验和拟合优度检验练习题
本博客根据非常好的excel资料而编写,使用python语言操作,预计使用一周的时间更新完成。需要《非常好的excel资料》word文档,欢迎发邮件给[email protected],免费发放。这篇博客对应《非常好的excel资料》里的第4章节里的练习题。
1.1 练习题
1、①分析:单个正态分布,方差已知时μ的U检验
H_0:u=34 , H_1:u≠34
②数据
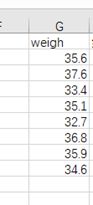
③Python代码如下
weigh = tree['weigh'][:8]
m=weigh.mean()
c=weigh.count()
def VarisknforU(a,m1,mn,stdn,n):
u=(m1-mn)/(stdn/np.sqrt(n))
uall=stats.norm.ppf(1-a/2)
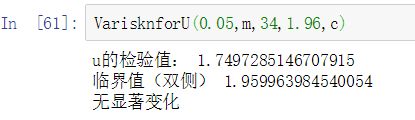
print('u的检验值:',u)
print('临界值(双侧)',uall)
if(u结果图
2、①分析:此题目属于方差未知时的t检验
② 数据:
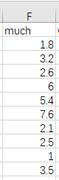
③ python代码
much=tree['much'][:10]
m2=much.mean()
s2 = much.std()
c2 = much.count()
from scipy.stats import t
def Varisnoforright(a,m1,mn,stdn,n):
u=(m1-mn)/(stdn/np.sqrt(n))
uall=t.ppf(1-a,n-1)
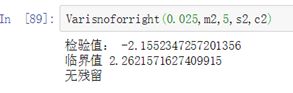
print('检验值:',u)
print('临界值',uall)
if(u结果图
3、①分析:此题目是方差已知但不等求u1-u2的检验
H_0:u1-u2=0 , H_1:u1-u2≠0
② 数据
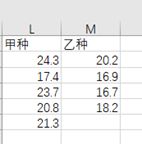
③ 法一:Excel操作如下
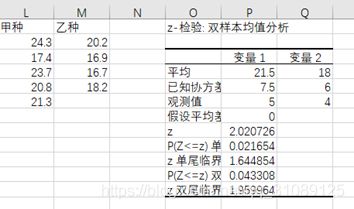
根据表格可知,z=2.020726<1.959964,则拒绝原假设,甲乙两种甜菜含糖率的平均值变化显著。
④ 法二:python操作
import pandas as pd
ex43 = pd.read_csv('D:\ex43.csv',encoding='gbk')
a = ex43['甲种']
b = ex43['乙种'][:4]
m1=a.mean()
m2=b.mean()
def U_test3(*args):
import numpy as np
from scipy import stats
tails, mean1, var1, n1, mean2, var2, n2 = [i for i in args]
segma_combine = np.sqrt(var1 / n1 + var2 / n2) # 需要先计算x1-x2的均方,即合并均方
u = abs(mean1 - mean2) / segma_combine
if tails == 2:
p = (1 - stats.norm.cdf(u, 0, 1)) * 2
if tails == 1:
p = 1 - stats.norm.cdf(u, 0, 1)
if p < 0.01:
print('extremely significant!')
elif p < 0.05:
print('significant!')
else:
print('unsignificant!')
print('u_value: %.6f,p_value: %.6f' % (u, p))
return [u, p]
执行
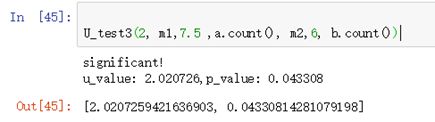
U_test3(2, m1,7.5 ,a.count(), m2,6, b.count())
结果图
4、①分析:两方差相等但未知的u1-u2的检验
H_0:u1-u2=0 , H_1:u1-u2≠0
② 数据
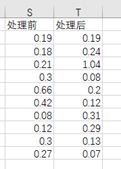
③ excel操作
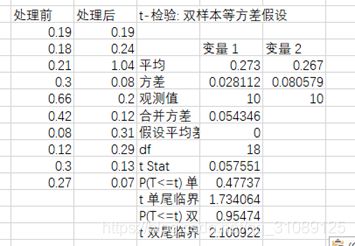
t Stat=0.057551<2.100922
所以接受原假设,处理前后含脂率的均值无显著变化。
④python操作
import pandas as pd
ins323=pd.read_csv('D:\ins323.csv',encoding='gbk',dtype={'code':int})
ins3231 = ins323[['处理前','处理后']][:8]
a = ins3231['处理前'][:7]
b = ins3231['处理后']
ttest_ind(a,b)
结果图

0.0190410>0.05,接受原假设,处理前后含脂率的均值无显著变化。
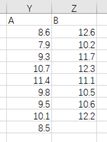
5、①分析:两个正态总体的方差齐性的F检验
H_0:σ_12=σ_22,H_1:σ_12≠σ_22
②数据
④ excel操作
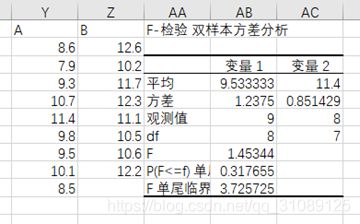
F=1.45344<3.725725,所以接受原假设,即它们方差很大程度上相等,即施肥后产量无显著提高
⑤python操作
import pandas as pd
ex45=pd.read_csv('D:\ex45.csv',encoding='gbk',dtype={'code':int})
a=ex45['A']
b=ex45['B'][:8]
stats.levene(a, b)
结果图

0.8310968>0.05,所以拒绝原假设,所以施肥后产量无显著提高
6、①数据
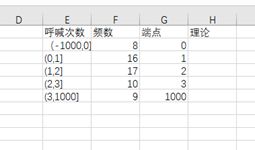
②excel操作
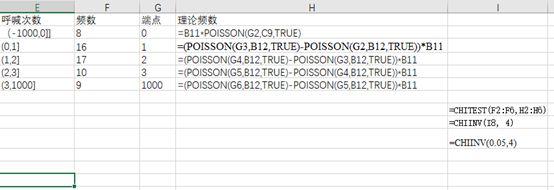
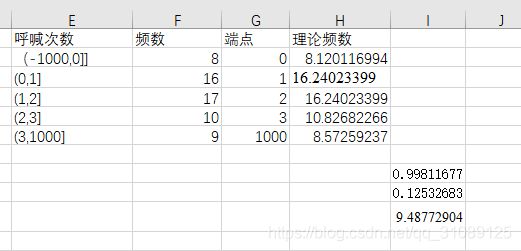
0.1253<9.4877,所以接受原假设,即符合正态分布
③python操作
import pandas as pd
import numpy as np
from pandas import DataFrame
ex46 = pd.read_csv('D:\ex46.csv',encoding='gbk')
ex461 = ex46[['呼喊次数1','频数1']][:7]
ex461=pd.DataFrame(ex461,dtype=np.int)
s11 = ex461['呼喊次数1'][:7]
s22 = ex461['频数1']
s11 = list(s11)
s22 = list(s22)
ex462 = ex46[['频数','端点']][:5]
ex461=pd.DataFrame(ex462,dtype=np.int)
s1 = pd.to_numeric(ex462['频数'])
s2 = pd.to_numeric(ex462['端点'])
mean=0
var=0
for i in range(len(s11)):
t= s11[i]*s22[i]
mean=mean+t
mean = mean/np.sum(s22)
def lilunpinshu(n,m,pingshu,qujianduandian):
from scipy import stats
j=0
a=[]
s=sum(pingshu)
for i in range(0,n):
if i==0:
aa = (stats.poisson.cdf(qujianduandian[i],mean))*s
a.append(aa)
else:
cc = stats.poisson.cdf(qujianduandian[i],mean)
c = stats.poisson.cdf(qujianduandian[i-1],mean)
a.append(s*(cc-c))
print(a)
return a
执行
chisquare(s1,lilunpinshu(s1.count(),mean,s1,s2))
结果图

因为0.998116>0.05,即接受原假设,即符合泊松分布。
7、①数据
②代码
import numpy as np
import pandas as pd
score=pd.read_csv('D:\score.csv',encoding='gbk')
a=[0]
a=a*10
score1=list(score['成绩'])
for i in range(len(score1)): #分类
j=score1[i]/10
j=int(j)
a[j]=a[j]+1
得到 [0, 0, 0, 0, 2, 4, 15, 24, 10, 5]
于是继续分类b=[6, 15, 24, 10, 5] #频率
bi=[50, 60, 70, 80,100]#端点
def lilunpinshu2(n,m,v,h):
j=0
a=[]
s=sum(b)
for i in range(0,n):
if i==0:
aa=s*stats.norm.cdf(h[i],m,v)
a.append(aa)
else:
cc=stats.norm.cdf(h[i],m,v)
c=stats.norm.cdf(h[i-1],m,v)
a.append(s*(cc-c))
return a
运行
chisquare(b,lilunpinshu2(5,m3,v3,bi))

因为统计量的值为49.83833>7.8147279,所以拒绝原假设,所以不是正态分布。
上一篇:数据挖掘之拟合优度检验
下一篇:方差分析实验