Linux下基于GTID的半同步复制的Mysql高可用架构之MHA(mysql版本:mysql-5.7.24)——主从切换(手动切换,在线切换,自动切换)+虚拟ip
参考:https://www.cnblogs.com/gomysql/p/3675429.html
一.Mysql高可用架构之MHA的介绍
1.MHA简介
- MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于 Facebook公司)开发,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在 0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
2.MHA的组成
- 该软件由两部分组成:MHA Manager(管理节点)——Manager工具包和MHA Node(数据节点)——和Node工具包。MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。MHA Node运行在每台MySQL服务器上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。
Manager工具包主要包括以下几个工具:
masterha_check_ssh 检查MHA的SSH配置状况
masterha_check_repl 检查MySQL复制状况
masterha_manger 启动MHA
masterha_check_status 检测当前MHA运行状态
masterha_master_monitor 检测master是否宕机
masterha_master_switch 控制故障转移(自动或者手动)
masterha_conf_host 添加或删除配置的server信息
Node工具包(这些工具通常由MHA Manager的脚本触发,无需人为操作)主要包括以下几个工具:
save_binary_logs 保存和复制master的二进制日志
apply_diff_relay_logs 识别差异的中继日志事件并将其差异的事件应用于其他的slave
filter_mysqlbinlog 去除不必要的ROLLBACK事件(MHA已不再使用这个工具)
purge_relay_logs 清除中继日志(不会阻塞SQL线程)
3.MHA的工作原理
- 在MHA自动故障切换过程中,MHA试图从宕机的主服务器上保存二进制日志,最大程度的保证数据的不丢失,但这并不总是可行的。例如,如果主服务器硬件故 障或无法通过ssh访问,MHA没法保存二进制日志,只进行故障转移而丢失了最新的数据。使用MySQL 5.5的半同步复制,可以大大降低数据丢失的风险。MHA可以与半同步复制结合起来。如果只有一个slave已经收到了最新的二进制日志,MHA可以将最新的二进制日志应用于其他所有的slave服务器上,因此可以保证所有节点的数据一致性。
具体工作原理介绍如下:

(1)从宕机崩溃的master保存二进制日志事件(binlog events);
(2)识别含有最新更新的slave;
(3)应用差异的中继日志(relay log)到其他的slave;
(4)应用从master保存的二进制日志事件(binlog events);
(5)提升一个slave为新的master;
(6)使其他的slave连接新的master进行复制;
二.实验环境(rhel7.3版本)
目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,一台充当备用master,另外一台充当从库,因为至少需要三台服务器,出于机器成本的考虑,淘宝也在该基础上进行了改造,目前淘宝TMHA已经支持一主一从。另外对于想快速搭建的可以参考:MHA快速搭建
我们自己使用其实也可以使用1主1从,但是master主机宕机后无法切换,以及无法补全binlog。master的mysqld进程crash后,还是可以切换成功,以及补全binlog的。
官方介绍:https://code.google.com/p/mysql-master-ha/
1.selinux和firewalld状态为disabled
2.各主机信息如下:
| 主机 | ip |
|---|---|
| server1(MHA数据节点:主库) | 172.25.83.1 |
| server2(MHA数据节点:从库,充当备用master) | 172.25.83.2 |
| server3(MHA数据节点:从库) | 172.25.83.3 |
| server4(MHA管理节点) | 172.25.83.4 |
注意:
为了尽可能的减少主库硬件损坏宕机造成的数据丢失,因此在配置MHA的同时建议配置成MySQL 5.7的半同步复制。关于半同步复制,请查看我的博文:https://mp.csdn.net/postedit/87897935
三.Mysql高可用架构之MHA的搭建部署
1.清空环境(因为server1,server2,server3之前是做过Mysql数据库的读写分离的,所以要清空环境。)
清空server1的环境(server2与server1的操作类似,这里以server1为例):
停掉之前的mysql,清空/var/lib/mysql目录下所有的mysql缓存记录
值的注意的是:必须先挂掉mysqld服务,然后再删除数据(这是因为关闭mysqld服务时,会自动保存数据)


清空server3的环境:
停掉之前的mysql-proxy服务(安装killall命令,然后利用killall命令杀掉,所有mysql-proxy的进程)
- 1.killall命令的安装如下:(先借助物理机找到killall命令对应的软件包,再进行安装)
- 2.利用killall命令杀掉所有关于mysql-proxy的进程,杀掉之后,可以利用“ps ax”命令进行确认



2.配置server1:
<1>编辑配置文件
[root@server1 ~]# vim /etc/my.cnf
server-id=1
gtid_mode=ON
enforce_gtid_consistency=ON
log_slave_updates=ON
log_bin=binlog
#log_slave_updates:默认值是off。如果不手动设置,那么log-bin只会记录直接在该库上执行SQL语句,由replication机制的SQL线程读取relay-log而执行的SQL语句不会记录到binlog,那么无法实现三级级联的同步。

<2>开启mysql,获取初始密码,进行安全初始化,创建半同步复制用户并授权,创建数据库以便后面的测试(创建数据库需要在加载半同步的插件之前进行操作)
[root@server1 ~]# systemctl start mysqld
[root@server1 ~]# grep password /var/log/mysqld.log
[root@server1 ~]# mysql_secure_installation
[root@server1 ~]# mysql -uroot -pXinjiaojiao+523
mysql> grant replication slave on *.* to 'xin'@'172.25.83.%' identified by 'Xinjiaojiao+523';
mysql> create database westos;
![]()
![]()
<3>登录数据库,安装半同步插件及配置
[root@server1 ~]# mysql -uroot -pXinjiaojiao+523
mysql> INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
mysql> INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
mysql> SET GLOBAL rpl_semi_sync_master_enabled=1;
mysql> SET GLOBAL rpl_semi_sync_master_timeout=1000000;
mysql> show variables like '%semi%'; #查看半同步的一些变量设置(来查看timeout的设置是否有效)
mysql> show status like '%semi%'; #查看半同步的一些状态的设置(来查看半同步的master端是否是打开的。)
mysql> show plugins; #查看插件(来查看半同步的插件是否加载成功)



![]()
![]()
<4>为了使得上述的半同步设置在重启mysqld服务之后,仍能生效。将半同步设置的参数加入mysqld服务的配置文件(/etc/my.cnf),并重启mysqld服务。

![]()
<5>下载MHA数据节点对应的安装包:mha4mysql-node-0.58-0.el7.centos.noarch.rpm,并进行安装

3.配置server2:
<1>编辑配置文件
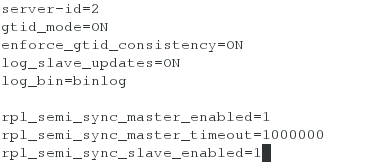
[root@server2 ~]# vim /etc/my.cnf
server-id=2
gtid_mode=ON
enforce_gtid_consistency=ON
log_slave_updates=ON
log_bin=binlog
#log_slave_updates:默认值是off。如果不手动设置,那么log-bin只会记录直接在该库上执行SQL语句,由replication机制的SQL线程读取relay-log而执行的SQL语句不会记录到binlog,那么无法实现三级级联的同步。

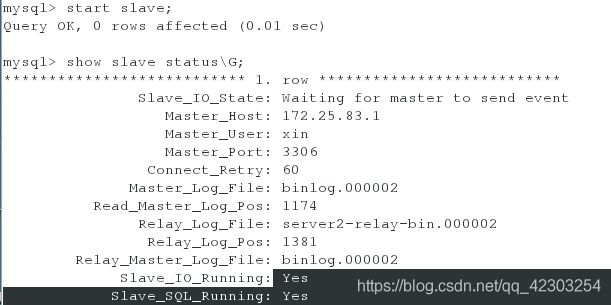
<2>开启mysql,获取初始密码,进行安全初始化,将从库和主库连接起来,开启slave,查看slave的状态,并查看数据库以确保基于gtid的半同步复制部署成功。
[root@server2 ~]# systemctl start mysqld
[root@server2 ~]# grep password /var/log/mysqld.log
[root@server2 ~]# mysql_secure_installation
[root@server2 ~]# mysql -uroot -pXinjiaojiao+523
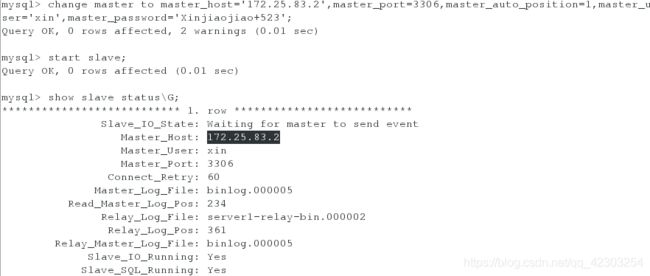
mysql> change master to master_host='172.25.83.1',master_user='xin',master_password='Xinjiaojiao+523',master_auto_position=1;
mysql> start slave;
mysql> show slave status\G;
mysql> show databases;
![]()

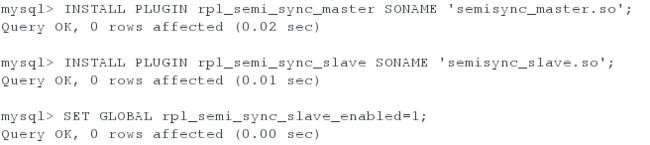
<3>登录数据库,安装半同步插件及配置
[root@server2 ~]# mysql -uroot -pXinjiaojiao+523
mysql> INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
mysql> INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
mysql> SET GLOBAL rpl_semi_sync_slave_enabled=1;
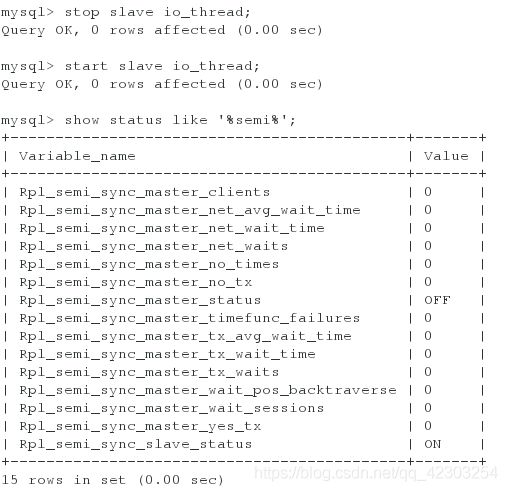
mysql> stop slave io_thread;
mysql> start slave io_thread;
mysql> show status like '%semi%'; #查看半同步的一些状态的设置(来查看半同步的slave端是否是打开的。)
mysql> show plugins; #查看插件(来查看半同步的插件是否加载成功)
![]()
![]()
<4>为了使得上述的半同步设置在重启mysqld服务之后,仍能生效。将半同步设置的参数加入mysqld服务的配置文件(/etc/my.cnf),并重启mysqld服务。(此时再次查看半同步的一些状态的设置,会看到半同步的master端和slave端都是打开的。)
![]()
<5>下载MHA数据节点对应的安装包:mha4mysql-node-0.58-0.el7.centos.noarch.rpm,并进行安装

4.配置server3(配置过程同server2,这里不再累赘)
5.在server1,server2,server3做好基于gtid的办同步复制的前提下:配置server1
<1>登陆数据库,给root用户全部的权限
[root@server1 ~]# mysql -uroot -pXinjiaojiao+523
mysql> grant all on *.* to 'root'@'%' identified by 'Xinjiaojiao+523';
![]()
<2>登陆数据库,创建 用户virtual,并赋予virtual用户insert,update,select的权限,以便后续测试虚拟ip。
[root@server1 ~]# mysql -uroot -pXinjiaojiao+523
mysql> grant insert,update,select on *.* to 'virtual'@'%' identified by 'Xinjiaojiao+523';
![]()
6.配置server4
<1>下载下面的.rpm包,并进行安装


<2>配置MHA管理节点到MHA数据节点之间的免密服务,并进行测试
[root@server4 ~]# ssh-keygen #生成密钥
[root@server4 ~]# ssh-copy-id server1 #将密钥发送给server1(MHA数据节点)
[root@server4 ~]# ssh-copy-id server2 #将密钥发送给server2(MHA数据节点)
[root@server4 ~]# ssh-copy-id server3 #将密钥发送给server3(MHA数据节点)




[root@server4 ~]# ssh server1 #测试是否实现了server4到server1之间的免密
[root@server4 ~]# ssh server2 #测试是否实现了server4到server2之间的免密
[root@server4 ~]# ssh server3 #测试是否实现了server4到server3之间的免密

<3>配置MHA数据节点之间的免密服务,并进行测试
[root@server4 ~]# scp -r ~/.ssh/ server1:
[root@server4 ~]# scp -r ~/.ssh/ server2:
[root@server4 ~]# scp -r ~/.ssh/ server3:
[root@server2 ~]# ssh server1 #测试是否实现了server2与server1之间的免密
[root@server2 ~]# ssh server3 #测试是否实现了server2与server3之间的免密
#在server1,server3上的测试类似,这里不在累赘

<4>配置MHA:创建MHA的工作目录,并且创建相关配置文件
[root@server4 ~]# mkdir /etc/masterha
[root@server4 ~]# vim /etc/masterha/app1.cnf
[server default]
manager_workdir=/etc/masterha #设置manager的工作目录
manager_log=/var/log/masterha.log #设置manager的日志
master_binlog_dir=/var/log/mysql #设置master保存binlog的位置,以便MHA可以找到master的日志,我这里的也就是mysql的数据目录
master_ip_failover_script=/usr/local/bin/master_ip_failover #设置自动failover时候的切换脚本
master_ip_online_change_script=/usr/local/bin/master_ip_online_change #设置手动切换时候的切换脚本
password=Xinjiaojiao+523 #设置mysql中root用户的密码
user=root #设置监控用户root
ping_interval=1 #设置监控主库,发送ping包的时间间隔,默认是3秒,尝试三次没有回应的时候自动进行failover
remote_workdir=/tmp #设置远端mysql在发生切换时binlog的保存位置
repl_password=Xinjiaojiao+523 #设置复制用户的密码
repl_user=xin #设置复制环境中的复制用户名
#report_script=/usr/local/send_report #设置发生切换后发送的报警的脚本
#secondary_check_script=/usr/local/bin/masterha_secondary_check -s server03 -s server02
#shutdown_script="" #设置故障发生后关闭故障主机脚本(该脚本的主要作用是关闭主机防止发生脑裂,这里没有使用)
ssh_user=root #设置ssh的登录用户名
[server1]
hostname=172.25.83.1
port=3306
[server2]
hostname=172.25.83.2
port=3306
candidate_master=1 #设置为候选master,如果设置该参数以后,发生主从切换以后将会将此从库提升为主库,即使这个主库不是集群中事件最新的slave
check_repl_delay=0 #默认情况下如果一个slave落后master 100M的relay logs的话,MHA将不会选择该slave作为一个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的master
[server3]
hostname=172.25.83.3
port=3306
#no_master=1 #其中上面的candidate_master=1和check_repl_delay=0与no_master=1的意思相反,所以只需设置一个。(此参数的意思是:不会称为备选的master)

<5>检查SSH配置:检查MHA Manger到所有MHA Node的SSH连接状态:
[root@server4 ~]# masterha_check_ssh --conf=/etc/masterha/app1.cnf

<6>检查整个复制环境状况:通过masterha_check_repl脚本查看整个集群的状态
值的注意的是:在测试过程中,会发现有些卡,这是因为在server1,server2及server3的配置文件中添加了半同步的配置(rpl_semi_sync_master_enabled=1 rpl_semi_sync_master_timeout=1000000 rpl_semi_sync_slave_enabled=1 ),可能其中timeout设置的数字有点大,为了测试,我们将server1,server2及server3中的这三行注释,并重启服务,再次在server4进行测试。
[root@server4 ~]# masterha_check_ssh --conf=/etc/masterha/app1.cnf


根据测试出来的结果提示,我们可以在server2和server3上设置只读
[root@server2 ~]# mysql -uroot -pXinjiaojiao+523
[root@server3 ~]# mysql -uroot -pXinjiaojiao+523
<7>配置VIP
vip配置可以采用两种方式,一种通过keepalived的方式管理虚拟ip的浮动;另外一种通过脚本方式启动虚拟ip的方式(即不需要keepalived或者heartbeat类似的软件)。
这里采用脚本的方式来管理虚拟ip。
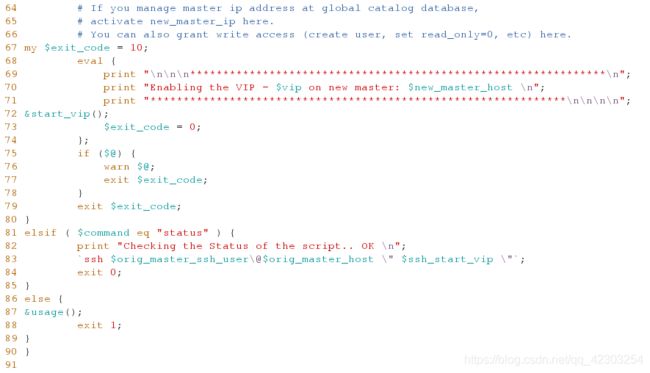
(1)在网上下载虚拟ip对应的配置文件(master_ip_failover 和master_ip_online_change),并进行相应的修改,配置文件的内容如下。
[root@server4 bin]# vim master_ip_failover #尤其注意11-13行内容的修改
[root@server4 bin]# vim master_ip_online_change #尤其注意7-9行内容的修改






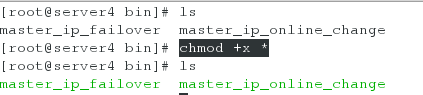
(2)给这两个脚本赋予可执行的权限
到此为止,基本MHA集群已经配置完毕。接下来就是实际的测试环节了。通过一些测试来看一下MHA到底是如何进行工作的。下面将从我们手动failover,在线切换,自动切换三种方式来介绍MHA的工作情况。
6.测试
<1>测试1:手动failover(MHA Manager必须没有运行)
手动failover,这种场景意味着在业务上没有启用MHA自动切换功能,当主服务器故障时,人工手动调用MHA来进行故障切换操作,具体命令如下:
注意:如果,MHA manager检测到没有dead的server,将报错,并结束failover:
下面模拟master(172.25.83.1)宕机的情况下手动把172.25.83.2提升为主库的操作过程。
(1)在server1上关闭mysqld服务
![]()
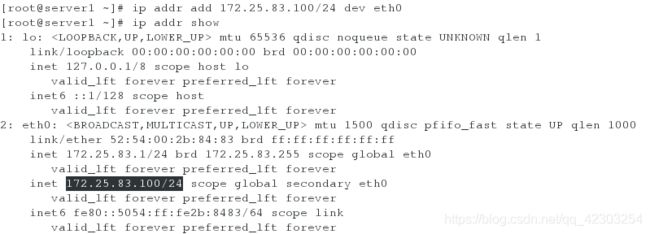
(2)在server1上添加虚拟ip,以便进行虚拟ip的实验。
(3)在server4上手动failover
[root@server4 ~]# masterha_master_switch --master_state=dead --conf=/etc/masterha/app1.cnf --dead_master_host=172.25.83.1 --dead_master_port=3306 --new_master_host=172.25.83.2 --new_master_port=3306 #两次输入yes
或者
[root@server4 ~]# masterha_master_switch --master_state=dead --conf=/etc/masterha/app1.cnf --dead_master_host=172.25.83.1 --dead_master_port=3306 --new_master_host=172.25.83.2 --new_master_port=3306 --ignore_last_failover
#即表示--ignore_last_failover可加可不加,(因为每次手动failover完成之后,都会在/etc/masterha目录下生成app1.failover.complete文件),这个参数的含义是忽略该文件的存在(因为如果该文件存在,且不加该参数,再次failover时会报错。因此要么该文件存在,加此参数;要么就将该文件删除,再进行测试)

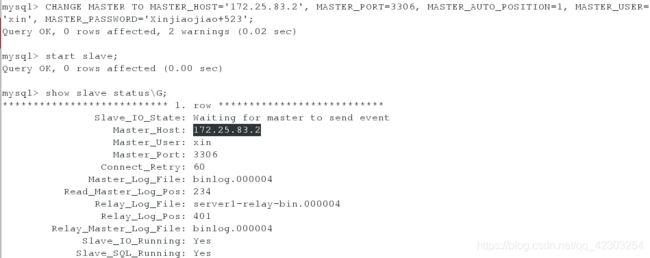
此时在server2上登陆数据库,查看master的状态;在server3上登陆数据库,查看slave的状态会看到server3显示的master是server2而不再是server1;在server1上启动mysqld服务,登陆数据库,执行命令,使得server1从库连接server2主库,并查看slave的状态,会看到server1作为从库指向server2的主库。
server2:
[root@server2 ~]# mysql -uroot -pXinjiaojiao+523
server3:
[root@server3 ~]# mysql -uroot -pXinjiaojiao+523
server1:(恢复server1作为从库)
[root@server1 ~]# mysql -uroot -pXinjiaojiao+523
此时在server1上查看ip,发现已经没有虚拟ip。而在server2上查看ip,发现虚拟ip在server2上。即成功实现了虚拟ip的漂移。
server1:
server2:




<2>测试2:在线进行切换(热切换)
- 在许多情况下, 需要将现有的主服务器迁移到另外一台服务器上。 比如主服务器硬件故障,RAID 控制卡需要重建,将主服务器移到性能更好的服务器上等等。维护主服务器引起性能下降, 导致停机时间至少无法写入数据。 另外, 阻塞或杀掉当前运行的会话会导致主主之间数据不一致的问题发生。 MHA 提供快速切换和优雅的阻塞写入,这个切换过程只需要 0.5-2s 的时间,这段时间内数据是无法写入的。在很多情况下,0.5-2s 的阻塞写入是可以接受的。因此切换主服务器不需要计划分配维护时间窗口。
MHA在线切换的大概过程:
1.检测复制设置和确定当前主服务器
2.确定新的主服务器
3.阻塞写入到当前主服务器
4.等待所有从服务器赶上复制
5.授予写入到新的主服务器
6.重新设置从服务器
注意,在线切换的时候应用架构需要考虑以下两个问题:
1.自动识别master和slave的问题(master的机器可能会切换),如果采用了vip的方式,基本可以解决这个问题。
2.负载均衡的问题(可以定义大概的读写比例,每台机器可承担的负载比例,当有机器离开集群时,需要考虑这个问题)
为了保证数据完全一致性,在最快的时间内完成切换,MHA的在线切换必须满足以下条件才会切换成功,否则会切换失败。
1.所有slave的IO线程都在运行
2.所有slave的SQL线程都在运行
3.所有的show slave status的输出中Seconds_Behind_Master参数小于或者等于running_updates_limit秒,如果在切换过程中不指 定running_updates_limit,那么默认情况下running_updates_limit为1秒。
4.在master端,通过show processlist输出,没有一个更新花费的时间大于running_updates_limit秒。
在模拟在线切换主库之前,删除之前切换时生成的文件,若有此文件,是不可以完成切换的。

下面模拟在线切换主库操作,原主库172.25.83.2变为slave,172.25.83.1提升为新的主库)
[root@server4 ~]# masterha_master_switch --conf=/etc/masterha/app1.cnf --master_state=alive --new_master_host=172.25.83.1 --new_master_port=3306 --orig_master_is_new_slave --running_updates_limit=10000 #三次输入yes
#其中参数的意思:
--orig_master_is_new_slave 切换时加上此参数是将原master变为slave节点,如果不加此参数,原来的 master将不启动
--running_updates_limit=10000,故障切换时,候选master 如果有延迟的话, mha切换不能成功,加上此参数表示延迟在此时间范围内都可切换(单位为s),但是切换的时间长短是由recover时relay日志的大小决定


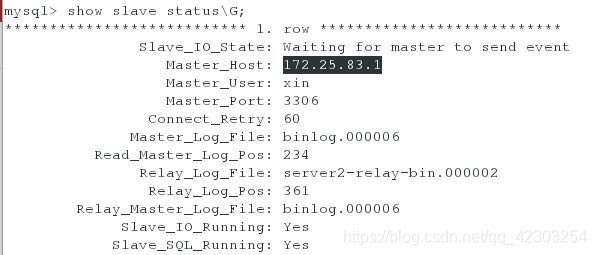
此时在server1上登陆数据库,查看master的状态;在server3上登陆数据库,查看slave的状态会看到server3显示的master是server1而不再是server1;在server2上登陆数据库,查看slave的状态,会看到server2作为从库指向server2的主库。
server1:
[root@server1 ~]# mysql -uroot -pXinjiaojiao+523
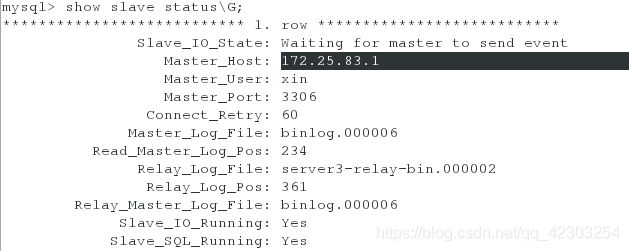
server3:
[root@server3 ~]# mysql -uroot -pXinjiaojiao+523
server2:
[root@server2 ~]# mysql -uroot -pXinjiaojiao+523
此时在server2上查看ip,发现已经没有虚拟ip。而在server1上查看ip,发现虚拟ip在server1上。即成功实现了虚拟ip的漂移。
server2:
server1:



<3>测试3:自动failover(必须先启动MHA Manager监控,否则无法自动切换)
在模拟自动failover之前,删除之前切换时生成的文件,若有此文件,是不可以完成切换的。
下面模拟master(172.25.83.1)宕机的情况下自动把172.25.83.2提升为主库的操作过程。
(1)自动切换监听打开并打入后台,并查看自动监听是否打开,以确保实验的正常进行
[root@server4 masterha]# nohup masterha_manager --conf=/etc/masterha/app1.cnf &> /dev/null & #打开自动监听,并打入后台
[root@server4 masterha]# masterha_check_status --conf=/etc/masterha/app1.cnf #检查MHA Manager的状态,以查看自动监听是否已经打开
#如果有必要,利用下面的命令来关闭自动监控
[root@server4 masterha]# masterha_stop --conf=/etc/masterha/app1.cnf
![]()
![]()
(2)关闭server1上的mysqld服务,模拟宕机
![]()
(3)验证该实验是否成功:
方法一:登陆数据库查看
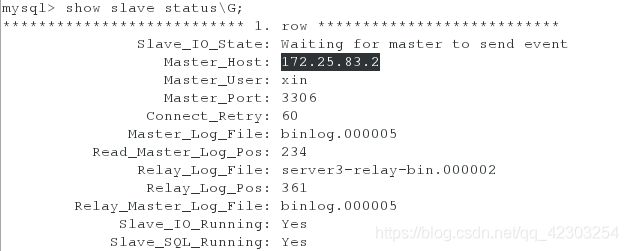
此时在server2上登陆数据库,查看master的状态;在server3上登陆数据库,查看slave的状态会看到server3显示的master是server2而不再是server1;在server1上启动mysqld服务,登陆数据库,执行命令,使得server1从库连接server2主库,并查看slave的状态,会看到server1作为从库指向server2的主库。
server2:
[root@server2 ~]# mysql -uroot -pXinjiaojiao+523
server3:
[root@server3 ~]# mysql -uroot -pXinjiaojiao+523
server1:(恢复server1作为从库)
[root@server1 ~]# mysql -uroot -pXinjiaojiao+523
此时在server1上查看ip,发现已经没有虚拟ip。而在server1上查看ip,发现虚拟ip在server1上。即成功实现了虚拟ip的漂移。
server1:
server2:
方法二:查看日志
[root@server4 masterha]# cat /var/log/masterha.log #该日志所在的目录在/etc/masterha/app1.cnf中已经指定。


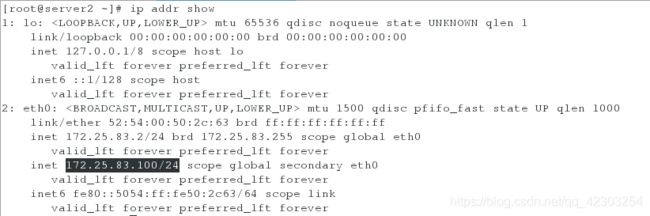

说明:设置vip的好处在于:
当授权的客户端,远程登陆数据库时,即使发生了主从切换,客户端也不会有所察觉(内部主从切换,外部无法得知)。
下面的客户端远程登陆数据库,在主从切换过程中,客户端没有收到一点点的影响。(在刚刚发生主从切换时,可能有点卡,但是等几秒钟之后,就跟没有发生主从切换一样)
