Spark Core解析《五》
一、Spark核心概念
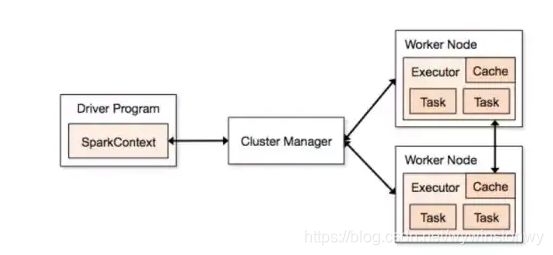
(1)Spark运行架构
(2)重要概念
Client
客户端进程,负责提交作业
Application
提交一个作业就是一个Application,一个Application只有一个SparkContext
Master
(图中的Cluster Manager),就像Hadoop中有NameNode和DataNode一样,Spark有Master和Worker。Master是集群的领导者,负责管理集群的资源,接收Client提交的作业,以及向Worker发送命令。
Worker
(图中的Woker Node),集群中的Woker,执行Master发送的命令,来具体分配资源,并在这些资源中执行任务
Driver
一个Spark作业运行时会启动一个Driver进程,也是作业的主进程,负责作业的解析、生成Stage,并调度Task到Executor上
Executor
真正执行作业的地方。Executor分布在集群的Worker上,每个Executor接收Driver命令来加载和运行Task,一个Executor可以执行一个到多个Task
SparkContext
是程序运行调度的核心,由高层调度器DAGScheduler划分程序的每个阶段,底层调度器TaskScheduler划分每个阶段的具体任务。SchedulerBankend管理整个集群中为正在运行的程序分配的计算资源Executor。
DAGScheduler
负责高层调度,划分Stage并生成程序运行的有向无环图
TaskScheduler
负责具体Stage内部的底层调度,具体Task的调度、容错等
Job
(正在执行的叫ActiveJob)是Top-level的工作单元,每个Action算子都会触发一次Job,一个Job可能包含一个或多个Stage
Stage
是用来计算中间结果的Tasksets。Tasksets中的Task逻辑对于同一RDD内的不同Partition都一样。Stage在Shuffle的地方产生,此时下一个Stage要用到上一个Stage的全部数据,所以要等上一个Stage全部执行完才能开始。Stage有两种:ShuffleMapStage和ResultStage,除了最后一个Stage是ResultStage外,其他的Stage都是ShuffleMapStage。ShuffleMapStage会产生中间结果,以文件的方式保存在集群里,Stage经常被不同的Job共享,前提是这些Job重用了同一个RDD
Task
任务执行的工作单位,每个Task会被发送到一个节点上,每个Task对应RDD的一个Partition
Taskset
划分的Stage会转换成一组相关联的任务集
RDD
(Resilient Distributed Dataset)弹性分布数据集。是不可变的、Lazy级别的、粗粒度的(数据集级别的而不是单个数据级别的)数据集合,包含一个或多个数据分片,即Partition
DAG
(Directed Acyclic Graph)有向无环图。Spark实现了DAG计算模型,DAG计算模型是指将一个计算任务按照计算规则分解为若干子任务,这些子任务之间根据逻辑关系构建成有向无环图
两种级别算子
Transformation和Action。Transformation算子会由DAGScheduler划分到pipeline中,是Lazy级别的不会触发任务的执行;Action算子会触发Job来执行pipeline中的运算
二、Spark UI详解
spark Web UI的各tab页分别进行介绍:
Job
在提交spark任务运行后,日志中会输出tracking URL即任务的日志链接。在浏览器中打开tracking URL后,默认进入Jobs页。Jobs展示的是整个spark应用任务的job整体信息:
User: spark任务提交的用户,用以进行权限控制与资源分配。
Total Uptime: spark application总的运行时间,从appmaster开始运行到结束的整体时间。
Scheduling Mode: application中task任务的调度策略,由参数spark.scheduler.mode来设置,可选的参数有FAIR和FIFO,默认是FIFO。这与yarn的资源调度策略的层级不同,yarn的资源调度是针对集群中不同application间的,而spark scheduler mode则是针对application内部task set级别的资源分配,不同FAIR策略的参数配置方式与yarn中FAIR策略的配置方式相同。
Completed Jobs: 已完成Job的基本信息,如想查看某一个Job的详细情况,可点击对应Job进行查看。
Active Jobs: 正在运行的Job的基本信息。
Event Timeline: 在application应用运行期间,Job和Exector的增加和删除事件进行图形化的展现。这个就是用来表示调度job何时启动何时结束,以及Excutor何时加入何时移除。我们可以很方便看到哪些job已经运行完成,使用了多少Excutor,哪些正在运行。

Job默认都是串行提交运行的,如果Job间没有依赖,可以使用多线程并行提交Job,实现Job并发。
Jobs Detail
在Jobs页面点击进入某个Job之后,可以查看某一Job的详细信息:
Staus: 展示Job的当前状态信息。
Active Stages: 正在运行的stages信息,点击某个stage可进入查看具体的stage信息。
Pending Stages: 排队的stages信息,根据解析的DAG图stage可并发提交运行,而有依赖的stage未运行完时则处于等待队列中。
Completed Stages: 已经完成的stages信息。
Event Timeline: 展示当前Job运行期间stage的提交与结束、Executor的加入与退出等事件信息。
DAG Visualization: 当前Job所包含的所有stage信息(stage中包含的明细的tranformation操作),以及各stage间的DAG依赖图。DAG也是一种调度模型,在spark的作业调度中,有很多作业存在依赖关系,所以没有依赖关系的作业可以并行执行,有依赖的作业不能并行执行。

Stages
在Job Detail页点击进入某个stage后,可以查看某一stage的详细信息:
Total time across all tasks: 当前stage中所有task花费的时间和。
Locality Level Summary: 不同本地化级别下的任务数,本地化级别是指数据与计算间的关系(PROCESS_LOCAL进程本地化:task与计算的数据在同一个Executor中。NODE_LOCAL节点本地化:情况一:task要计算的数据是在同一个Worker的不同Executor进程中;情况二:task要计算的数据是在同一个Worker的磁盘上,或在 HDFS 上,恰好有 block 在同一个节点上。RACK_LOCAL机架本地化,数据在同一机架的不同节点上:情况一:task计算的数据在Worker2的Executor中;情况二:task计算的数据在Worker2的磁盘上。ANY跨机架,数据在非同一机架的网络上,速度最慢)。
Input Size/Records: 输入的数据字节数大小/记录条数。
Shuffle Write: 为下一个依赖的stage提供输入数据,shuffle过程中通过网络传输的数据字节数/记录条数。应该尽量减少shuffle的数据量及其操作次数,这是spark任务优化的一条基本原则。
DAG Visualization: 当前stage中包含的详细的tranformation操作流程图。
Metrics: 当前stage中所有task的一些指标(每一指标项鼠标移动上去后会有对应解释信息)统计信息。
Event Timeline: 清楚地展示在每个Executor上各个task的各个阶段的时间统计信息,可以清楚地看到task任务时间是否有明显倾斜,以及倾斜的时间主要是属于哪个阶段,从而有针对性的进行优化。
Aggregated Metrics by Executor: 将task运行的指标信息按excutor做聚合后的统计信息,并可查看某个Excutor上任务运行的日志信息。
Tasks: 当前stage中所有任务运行的明细信息,是与Event Timeline中的信息对应的文字展示(可以点击某个task查看具体的任务日志)。

Storage
storage页面能看出application当前使用的缓存情况,可以看到有哪些RDD被缓存了,以及占用的内存资源。如果job在执行时持久化(persist)/缓存(cache)了一个RDD,那么RDD的信息可以在这个选项卡中查看。
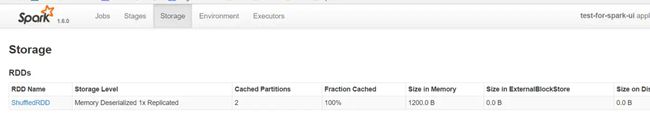
Storage Detail
点击某个RDD即可查看该RDD缓存的详细信息,包括缓存在哪个Executor中,使用的block情况,RDD上分区(partitions)的信息以及存储RDD的主机的地址。

Enviroment
Environment选项卡提供有关Spark应用程序(或SparkContext)中使用的各种属性和环境变量的信息。用户可以通过这个选项卡得到非常有用的各种Spark属性信息,而不用去翻找属性配置文件。

Executor
Executors选项卡提供了关于内存、CPU核和其他被Executors使用的资源的信息。这些信息在Executor级别和汇总级别都可以获取到。一方面通过它可以看出来每个excutor是否发生了数据倾斜,另一方面可以具体分析目前的应用是否产生了大量的shuffle,是否可以通过数据的本地性或者减小数据的传输来减少shuffle的数据量。

Summary: 该application运行过程中使用Executor的统计信息。
Executors: 每个Excutor的详细信息(包含driver),可以点击查看某个Executor中任务运行的详细日志。
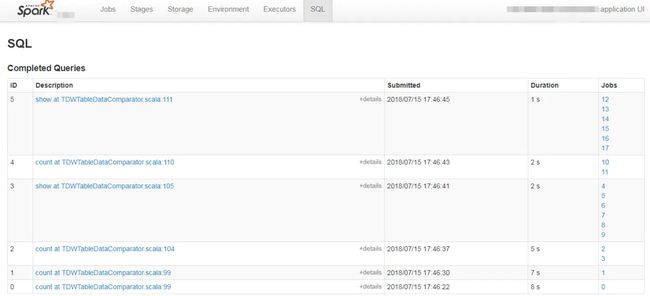
SQL
SQL选项卡(只有执行了spark SQL查询才会有SQL选项卡)可以查看SQL执行计划的细节,它提供了SQL查询的DAG以及显示Spark如何优化已执行的SQL查询的查询计划。

三、Spark运行架构以及注意事项
四、Spark和hadoop区别
hadoop
Hadoop实质上更多是一个分布式系统基础架构: 它将巨大的数据集分派到一个由普通计算机组成的集群中的多个节点进行存储,同时还会索引和跟踪这些数据,大幅度提升大数据处理和分析效率。Hadoop 可以独立完成数据的存储和处理工作,因为其除了提供HDFS分布式数据存储功能,还提供MapReduce数据处理功能。
spark
Spark 是一个专门用来对那些分布式存储的大数据进行处理的工具,没有提供文件管理系统,自身不会进行数据的存储。它必须和其他的分布式文件系统进行集成才能运作。可以选择Hadoop的HDFS,也可以选择其他平台。
五、Spark缓存的作用、Spark缓存策略
Spark中最重要的功能之一是跨操作在内存中持久化(或缓存)数据集。当您持久化一个RDD时,每个节点在内存中存储它计算的任何分区,并在该数据集(或从该数据集派生的数据集)上的其他操作中重用它们。这使得将来的操作要快得多(通常超过10倍)。缓存是迭代算法和快速交互使用的关键工具。
可以使用persist()或cache()方法将RDD标记为持久的。第一次在操作中计算它时,它将保存在节点的内存中。Spark的缓存是容错的——如果一个RDD的任何分区丢失了,它将使用最初创建它的转换自动重新计算。
此外,每个持久化的RDD可以使用不同的存储级别进行存储,例如,允许您将数据集持久化到磁盘上,将其持久化到内存中,但是作为序列化的Java对象(为了节省空间),可以跨节点复制数据集。这些级别是通过传递一个StorageLevel对象(Scala、Java、Python)来设置的。cache()方法是使用默认存储级别的简写,即StorageLevel。MEMORY_ONLY(将反序列化的对象存储在内存中)。存储级别的完整集合为:
| Storage Level |
Meaning |
| MEMORY_ONLY | 将RDD作为反序列化的Java对象存储在JVM中。如果RDD不适合内存,那么一些分区将不会被缓存,并在每次需要它们时动态地重新计算。这是默认级别。 |
| MEMORY_AND_DISK | 将RDD作为反序列化的Java对象存储在JVM中。如果RDD不适合内存,那么将不适合的分区存储在磁盘上,并在需要的时候从那里读取它们。 |
| MEMORY_ONLY_SER (Java and Scala) |
将RDD存储为序列化的Java对象(每个分区一个字节数组)。这通常比反序列化对象更节省空间,特别是在使用快速序列化器时,但读取时需要更多cpu。 |
| MEMORY_AND_DISK_SER (Java and Scala) |
与MEMORY_ONLY_SER类似,但是将不适合内存的分区溢出到磁盘,而不是在每次需要它们时动态地重新计算它们。 |
| DISK_ONLY | Store the RDD partitions only on disk.
|
| MEMORY_ONLY_2, MEMORY_AND_DISK_2, etc. | 与上面的级别相同,但是在两个集群节点上复制每个分区。 |
| OFF_HEAP (experimental) |
与MEMORY_ONLY_SER类似,但将数据存储在堆外内存中。这需要启用堆外内存。 |
七、Spark Lineage机制
利用内存加快数据加载,在其它的In-Memory类数据库或Cache类系统中也有实现。Spark的主要区别在于它采用血统(Lineage)来时实现分布式运算环境下的数据容错性(节点失效、数据丢失)问题。RDD Lineage被称为RDD运算图或RDD依赖关系图,是RDD所有父RDD的图。它是在RDD上执行transformations函数并创建逻辑执行计划(logical execution plan)的结果,是RDD的逻辑执行计划。相比其它系统的细颗粒度的内存数据更新级别的备份或者LOG机制,RDD的Lineage记录的是粗颗粒度的特定数据转换(Transformation)操作(filter, map, join etc.)行为。当这个RDD的部分分区数据丢失时,它可以通过Lineage找到丢失的父RDD的分区进行局部计算来恢复丢失的数据,这样可以节省资源提高运行效率。这种粗颗粒的数据模型,限制了Spark的运用场合,但同时相比细颗粒度的数据模型,也带来了性能的提升。
八、Spark 窄依赖和宽依赖
依赖关系决定Lineage的复杂程度,同时也是的RDD具有了容错性。因为当某一个分区里的数据丢失了,Spark程序会根据依赖关系进行局部计算来恢复丢失的数据。依赖的关系主要分为2种,分别是 宽依赖(Wide Dependencies)和窄依赖(Narrow Dependencies)。
宽依赖:是指子RDD的分区依赖于父RDD的多个分区或所有分区,也就是说存在一个父RDD的一个分区对应一个子RDD的多个分区。
窄依赖:是指父RDD的每一个分区最多被一个子RDD的分区所用,表现为一个父RDD的分区对应于一个子RDD的分区或多个父RDD的分区对应于一个子RDD的分区,也就是说一个父RDD的一个分区不可能对应一个子RDD的多个分区。
判断依赖的本质:判断是宽依赖还是窄依赖的本质实际上是根据父RDD的分区和对应的子RDD的分区来进行区分宽依赖和窄依赖的。当父RDD的分区对应多个分区时,也就是说父RDD的分区对应的另一部分数据可能是其他子RDD的数据,那么当该RDD数据丢失后,进行容错从分区就会把该RDD跟另外一个RDD的数据都重新计算一遍,这样就会导致冗余计算(因为,另一个子RDD的数据是当前丢失的子RDD所不需要的也计算了一遍)。
九、Spark Shuffle概述
Spark中的某些操作会触发一个称为shuffle的事件。shuffle是Spark重新分布数据的机制,以便在分区之间以不同的方式进行分组。这通常涉及跨执行器和机器复制数据,使shuffle成为一个复杂且昂贵的操作。
十、RDD的shuffle的依赖关系
对于 Shuffle Dependencies(一般是宽依赖),Stage 计算的输入和输出在不同的节点上,输入节点的Lineage完好,而输出节点死机的情况,通过重新计算恢复数据这种情况下,这种方法容错是有效的,否则无效,因为无法重试,需要向上追溯其祖先看是否可以重试(这就是 lineage,血统的意思),窄依赖对于数据的重算开销要远小于 宽依赖的数据重算开 销。
窄依赖( Narrow Dependency) 和 Shuffle Dependency 的概念主要用在两个地方:一个是容错中相当于 Redo 日志的功能;另一个是在调度中构建 DAG 作为不同 Stage 的划分点。
相关推荐:
hadoop,pySpark环境安装与运行实战《一》
Spark RDD操作,常用算子《二》
PySpark之算子综合实战案例《三》
Spark运行模式以及部署《四》
Spark Core解析《五》
PySpark之Spark Core调优《六》
PySpark之Spark SQL的使用《七》