Flink监控:自定义消费延迟Metrics
文章目录
-
-
- 1. 需求
- 2. 名词解释
-
- 2.1 committed-offsets
- 2.2 current-offsets
- 2.3 highWatermark
- 3. 自定义Metrics
-
- 3.1 flink kafka source connector源码分析
-
- 3.1.2 周期提交
- 3.1.3 Checkpoint时提交
- 3.2 定义HighWatermark Metrics
-
- 3.2.1 自定义flink kafka consumer
- 3.2.2 自定义序列化器
- 3.2.1 自定义HighWatermark Metrics
-
1. 需求
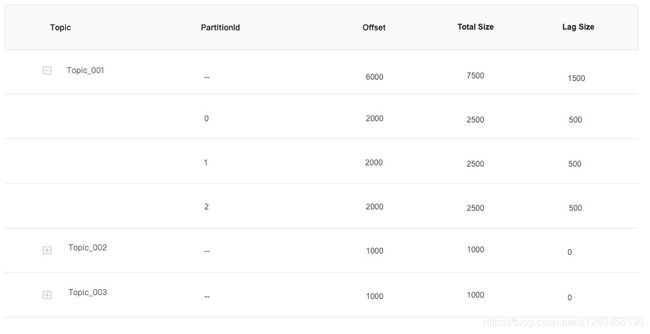
现有如下需求,以kafka作为source,使用pushgateway+prometheus架构实时统计flink任务的消费偏移量current-offset和分区偏移量总长度log-end-offset,并计算两者差值得到消费延迟lag,如图:
2. 名词解释
2.1 committed-offsets
每一次kafka消费者调用consumer.poll()后得到一批数据,然后会调用consumer.commitAsync()之类的方法进行提交,代码如下:
ConsumerRecords<byte[], byte[]> records = consumer.poll(pollTimeoutMs);
for (ConsumerRecord<byte[], byte[]> record : records) {
...
}
consumer.commitAsync();
提交后的offset会被存储到zookeeper(已废弃)或者kafka内部topic _consumer_offsets中
2.2 current-offsets
指在poll()方法拉取到的records中,准确消费到哪一条,因此current-offsets是业务强相关的,无法在kafka broker或者kafka client中查询到。在flink kafka source connector中,current-offsets有如下诠释:
This refers to the offset of the last element that we retrieved and emitted successfully
2.3 highWatermark
log-end-offsets(LEO)即日志末端位移,记录了分区副本底层日志中最后一条消息的位移值。但是kafka中因有leader副本和follower副本的存在,会有一套highWatermark机制,leader副本会取所有副本中LEO的最小值作为分区的highWatermark,只有highWatermark对用户才是可见的。详情参考
Kafka HighWatermark
3. 自定义Metrics
那么,为了满足需求,我们究竟需要使用上述的哪些指标呢?我们来分析一下flink kafka source connector源码中关于offset的提交。
3.1 flink kafka source connector源码分析
flink kafka source connector中共有三种提交模式:
public enum OffsetCommitMode {
/** Completely disable offset committing. */
DISABLED,
/** Commit offsets back to Kafka only when checkpoints are completed. */
ON_CHECKPOINTS,
/** Commit offsets periodically back to Kafka, using the auto commit functionality of internal Kafka clients. */
KAFKA_PERIODIC;
}
3.1.2 周期提交
Properties properties = new Properties();
properties.put("enable.auto.commit", "true");
properties.setProperty("auto.commit.interval.ms", "1000");
new FlinkKafkaConsumer<>("foo", new KafkaEventSchema(), properties)
这种提交模式下,我们显然只能使用current-offsets作为监控指标,因为committed-offsets是周期提交的,假设周期如代码中所示为1秒,kafka消费者客户端会自动把从 poll()方法接收到的最大偏移量提交上去,而此时flink正在消费的消息也许并未达到本次poll()接收到的最大偏移量,使用committed-offsets并不准确
3.1.3 Checkpoint时提交
在做 checkpoint 的时候会调用 FlinkKafkaConsumerBase#snapshotState方法,其中 pendingOffsetsToCommit 会保存要提交的 offset。
public final void snapshotState(FunctionSnapshotContext context) throws Exception {
if (offsetCommitMode == OffsetCommitMode.ON_CHECKPOINTS) {
// the map cannot be asynchronously updated, because only one checkpoint call can happen
// on this function at a time: either snapshotState() or notifyCheckpointComplete()
// 保存等待提交的current-offsets
pendingOffsetsToCommit.put(context.getCheckpointId(), currentOffsets);
}
for (Map.Entry<KafkaTopicPartition, Long> kafkaTopicPartitionLongEntry : currentOffsets.entrySet()) {
// 将各个分区的current-offset写入状态
unionOffsetStates.add(
Tuple2.of(kafkaTopicPartitionLongEntry.getKey(), kafkaTopicPartitionLongEntry.getValue()));
}
}
在 checkpoint 完成以后,task 会调用 notifyCheckpointComplete() 方法
// FlinkKafkaConsumerBase.java
public final void notifyCheckpointComplete(long checkpointId) throws Exception {
...
}
最终会将要提交的 offset 通过 KafkaFetcher#doCommitInternalOffsetsToKafka 方法中的 consumerThread.setOffsetsToCommit(offsetsToCommit, commitCallback); 保存到 KafkaConsumerThread.java 中的 nextOffsetsToCommit 成员变量里面,并进行提交
// KafkaConsumerThread.java
void setOffsetsToCommit(
...
extOffsetsToCommit.getAndSet(Tuple2.of(offsetsToCommit, commitCallback)
...
}
public void run() {
while (running) {
...
final Tuple2<Map<TopicPartition, OffsetAndMetadata>, KafkaCommitCallback> commitOffsetsAndCallback = nextOffsetsToCommit.getAndSet(null);
...
consumer.commitAsync(commitOffsetsAndCallback.f0, new CommitCallback(commitOffsetsAndCallback.f1));
...
}
}
这种提交模式下,我们显然也只能使用current-offsets作为监控指标,因为commit-offsets只有在checkpoint做完之后,才会进行提交。一次checkpoint的时间往往会被设置成几分钟,再加上barrier对齐、反压等环境因素,checkpoint的时间甚至会更长,这之间flink早已消费了一批又一批的数据了,差之毫厘谬以千里。
综上,我们根据需求和各概念相应的释义明确了需要的Metrics指标,即current-offsets和highWatermark,lag通过两者差值来计算。flink官方metrics有提供current-offsets,详情参考Flink Metrics,因此我们可以直接获取,接下来我们自定义HighWatermark Metrics。
3.2 定义HighWatermark Metrics
3.2.1 自定义flink kafka consumer
public class CustomerJsonConsumer extends FlinkKafkaConsumer011<Row> {
private static final long serialVersionUID = -1234567890L;
// 自定义序列化器
private CustomerJsonDeserialization customerJsonDeserialization;
public CustomerJsonConsumer(String topic, AbsKafkaDeserialization<Row> valueDeserializer, Properties props) {
// 构造器传入自定义序列化器
super(Arrays.asList(topic.split(",")), valueDeserializer, props);
this.customerJsonDeserialization = (CustomerJsonDeserialization) valueDeserializer;
}
public CustomerJsonConsumer(Pattern subscriptionPattern,
AbsKafkaDeserialization<Row> valueDeserializer, Properties props) {
super(subscriptionPattern, valueDeserializer, props);
this.customerJsonDeserialization = (CustomerJsonDeserialization) valueDeserializer;
}
// run()方法是task启动的入口
@Override
public void run(SourceContext<Row> sourceContext) throws Exception {
customerJsonDeserialization.setRuntimeContext(getRuntimeContext());
customerJsonDeserialization.initMetric();
super.run(sourceContext);
}
@Override
protected AbstractFetcher<Row, ?> createFetcher(SourceContext<Row> sourceContext,
Map<KafkaTopicPartition, Long> assignedPartitionsWithInitialOffsets,
SerializedValue<AssignerWithPeriodicWatermarks<Row>> watermarksPeriodic,
SerializedValue<AssignerWithPunctuatedWatermarks<Row>> watermarksPunctuated,
StreamingRuntimeContext runtimeContext, OffsetCommitMode offsetCommitMode,
MetricGroup consumerMetricGroup,
boolean useMetrics) throws Exception {
AbstractFetcher<Row, ?> fetcher = super.createFetcher(
sourceContext,
assignedPartitionsWithInitialOffsets,
watermarksPeriodic,
watermarksPunctuated,
runtimeContext,
offsetCommitMode,
consumerMetricGroup,
useMetrics);
// 向自定义序列化器中传入fetcher,fetcher持有kafka consumer客户端,
// 我们需要的信息都能通过consumer客户端拿到
customerJsonDeserialization.setFetcher(fetcher);
return fetcher;
}
}
3.2.2 自定义序列化器
利用反射层层抽丝剥茧,拿到SubscriptionState$TopicPartitionState对象中的highWatermark属性
public class CustomerJsonDeserialization extends AbsKafkaDeserialization<Row> {
private static final Logger LOG = LoggerFactory.getLogger(CustomerJsonDeserialization.class);
private static final long serialVersionUID = 2385115520960444192L;
String DT_TOPIC_GROUP = "topic";
String DT_PARTITION_GROUP = "partition";
private AbstractFetcher<Row, ?> fetcher;
public CustomerJsonDeserialization(TypeInformation<Row> typeInfo) {
super(typeInfo);
this.runtimeConverter = createConverter(this.typeInfo);
}
@Override
public Row deserialize(byte[] message) {
if(openMetric && firstMsg){
try {
// 只有在第一条数据到来的时候,才会调用该方法
registerPtMetric(fetcher);
} catch (Exception e) {
LOG.error("register topic partition metric error.", e);
}
firstMsg = false;
}
try {
Row row;
try {
final JsonNode root = objectMapper.readTree(message);
row = (Row) super.runtimeConverter.convert(objectMapper, root);
} catch (Throwable t) {
throw new IOException("Failed to deserialize JSON object.", t);
}
return row;
} catch (Exception e) {
// add metric of dirty data
LOG.error(e.getMessage(), e);
return null;
}
}
// fetcher由自定义flink kafka consumer传入
public void setFetcher(AbstractFetcher<Row, ?> fetcher) {
this.fetcher = fetcher;
}
protected void registerPtMetric(AbstractFetcher<Row, ?> fetcher) throws Exception {
// 通过反射获取fetcher中的kafka消费者等信息, 反射获取属性路径如下:
// Flink: Fetcher -> KafkaConsumerThread -> KafkaConsumer ->
// Kafka Consumer: KafkaConsumer -> SubscriptionState -> SubscriptionState$TopicPartitionState -> assignedPartitions() -> assignedState()
Field consumerThreadField = fetcher.getClass().getSuperclass().getDeclaredField("consumerThread");
consumerThreadField.setAccessible(true);
KafkaConsumerThread consumerThread = (KafkaConsumerThread) consumerThreadField.get(fetcher);
Field hasAssignedPartitionsField = consumerThread.getClass().getDeclaredField("hasAssignedPartitions");
hasAssignedPartitionsField.setAccessible(true);
boolean hasAssignedPartitions = (boolean) hasAssignedPartitionsField.get(consumerThread);
if(!hasAssignedPartitions){
throw new RuntimeException("wait 50 secs, but not assignedPartitions");
}
Field consumerField = consumerThread.getClass().getDeclaredField("consumer");
consumerField.setAccessible(true);
KafkaConsumer kafkaConsumer = (KafkaConsumer) consumerField.get(consumerThread);
Field subscriptionStateField = kafkaConsumer.getClass().getDeclaredField("subscriptions");
subscriptionStateField.setAccessible(true);
SubscriptionState subscriptionState = (SubscriptionState) subscriptionStateField.get(kafkaConsumer);
// 通过反射获取内部类对象
Class topicPartitionStateClazz = Class.forName("org.apache.kafka.clients.consumer.internals.SubscriptionState$TopicPartitionState");
Field highWatermarkField = topicPartitionStateClazz.getDeclaredField("highWatermark");
highWatermarkField.setAccessible(true);
Method assignedState = SubscriptionState.class.getDeclaredMethod("assignedState", TopicPartition.class);
Set<TopicPartition> assignedPartitions = subscriptionState.assignedPartitions();
assignedState.setAccessible(true);
for(TopicPartition topicPartition : assignedPartitions){
MetricGroup metricGroup = getRuntimeContext().getMetricGroup().addGroup(DT_TOPIC_GROUP, topicPartition.topic())
.addGroup(DT_PARTITION_GROUP, topicPartition.partition() + "");
// 自定义Metrics
metricGroup.gauge(DT_TOPIC_PARTITION_HIGHWATERMARK_GAUGE, new KafkaTopicPartitionHighWatermarkMetric(assignedState, subscriptionState, highWatermarkField, topicPartition));
}
}
}
3.2.1 自定义HighWatermark Metrics
public class KafkaTopicPartitionHighWatermarkMetric implements Gauge<Long> {
private Method assignedState;
private SubscriptionState subscriptionState;
private Field highWatermarkField;
private TopicPartition topicPartition;
// 重点:由于HighWatermark Gauge只会在第一条数据到来时,进行初始化定义,
// 因此如果在此时传入highwaterMark,则之后自定义Gauge实现类无法更新highwaterMark值。
// 因此,要在Gauge实现类中传入SubscriptionState等对象的引用,Flink Metrics系统才能实时更新highwaterMark值
public KafkaTopicPartitionHighWatermarkMetric(Method assignedState, SubscriptionState subscriptionState, Field highWatermarkField, TopicPartition topicPartition) {
this.assignedState = assignedState;
this.subscriptionState = subscriptionState;
this.highWatermarkField = highWatermarkField;
this.topicPartition = topicPartition;
}
@Override
public Long getValue() {
Long highWatermark = 0L;
try {
Object topicPartitionState = assignedState.invoke(subscriptionState, topicPartition);
highWatermark = (Long) highWatermarkField.get(topicPartitionState);
} catch (Exception e) {
throw new RuntimeException("get topicPartitionState failed", e);
}
return highWatermark;
}
}
参考:
https://ververica.cn/developers/flink-kafka-source-sink-source-analysis/
https://ci.apache.org/projects/flink/flink-docs-stable/dev/connectors/kafka.html#kafka-connector-metrics
https://www.cnblogs.com/huxi2b/p/7453543.html