【字符串】后缀自动机
后缀自动机
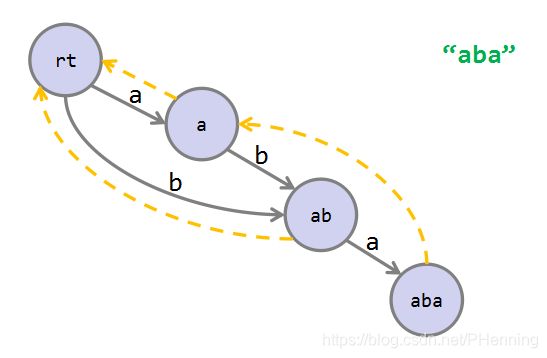
对给定字符串 S S S的后缀自动机是一个最小化确定有限状态自动机,它能够接收字符串 S S S的所有后缀(即所有子串)。可以在线性时间内、使用线性空间构造出一个以开始状态为根结点、以接受状态为中间结点的有向无环图。这个有向无环图存储了字符串 s s s的所有信息。
-
SAM中的转移边(图中的灰边)构成了一个有向无环图。每条转移边上都有一个字符,从根结点出发的路径形成的字符串与原串中的子串一一对应。
每个结点代表从根节点到这个点的所有路径形成的字符串的集合,维护了当前结点的转移 t o [ t ] to[t] to[t]、集合中最长字符串的长度 l e n len len和后缀链接 f a fa fa。 -
一个子串的右集合为该子串在原串中出现的所有位置的右端点的集合。
同一个结点中的字符串的右集合相同,这些字符串都是其中最长的一个字符串的后缀,并且长度连续。
原串的任意两个子串的右集合要么不相交,要么包含。 -
一个结点的后缀链接的右集合包含自己的右集合且大小最小。所有的后缀链接关系(图中的黄边)构成了一棵树,结点的后缀链接为它的父亲。
一个结点中的最长字符串的所有后缀就是该结点及其祖先中的所有字符串的集合。
一个结点中的最短字符串的长度比其父亲中的最长字符串长度多 1 1 1,即 min { l e n ( S ) ∣ S ∈ x } = max { l e n ( T ) ∣ T ∈ f a [ x ] } + 1 \min\{len(S)|S\in x\}=\max\{len(T)|T\in fa[x]\}+1 min{len(S)∣S∈x}=max{len(T)∣T∈fa[x]}+1所以每个结点只需记下最长字符串的长度 l e n len len就行了,最短长度可以直接计算。
构造SAM
SAM的构造采用增量法,即在一个已经构造好了的SAM上面添加字符,处理添加的字符带来的影响。
记新添加字符 t t t后需添加结点 n p np np,当前SAM中最后添加的结点为 n o w now now。于是 n o w now now中的字符串及其后缀加上字符 t t t后都能得到新的子串,于是将 n o w now now及其祖先都连一条字符 t t t的转移边指向 n p np np。
如果像这样一直畅通无阻地跑到了根节点,就把根节点设为 n p np np的父亲。
如果在这过程中,某个结点 p p p已经有了一条字符 t t t的转移边,记转移边指向结点 q q q。接下来要考虑两种情况:
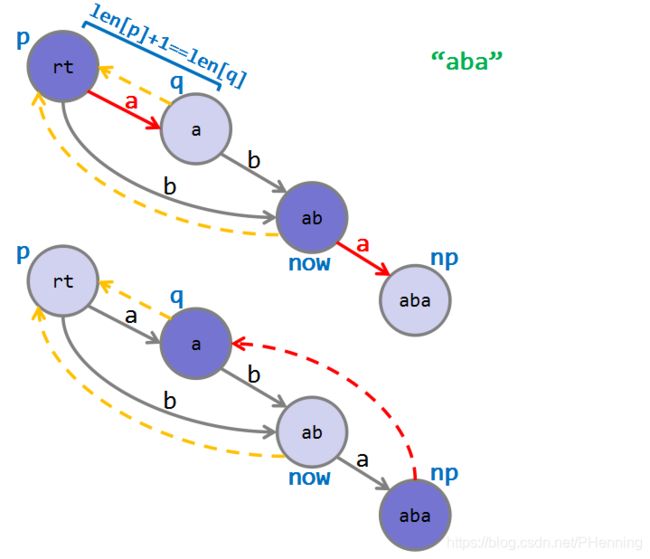
- 若 l e n [ p ] + 1 = l e n [ q ] len[p]+1=len[q] len[p]+1=len[q],即 q q q中的字符串由 p p p中的字符串加上 t t t得到,此时 q q q中的字符串仍为 n p np np中字符串的后缀(解释得更清楚一些,因为 p p p是 n o w now now的祖先,所以 p p p中的字符串是 n o w now now中的字符串的后缀, p p p添加一个字符 t t t得到 q q q, n o w now now添加一个字符 t t t得到 n p np np,所以 q q q中的字符串是 n p np np中字符串的后缀),直接把 n p np np的父亲设为 q q q。

- 若 l e n [ p ] + 1 < l e n [ q ] len[p]+1<len[q] len[p]+1<len[q], p p p转移向 q q q的时候 p p p中的字符串就可能发生了一些奇怪的事情, q q q中的字符串不再是 n p np np中字符串的后缀,于是我们新加一个点 n q nq nq(转移边和父亲跟 q q q一样, l e n [ n q ] len[nq] len[nq]设为 l e n [ p ] + 1 len[p]+1 len[p]+1),把 n q nq nq设为 q q q和 n p np np的公共父亲,再把 p p p及其祖先中指向 q q q的转移边指向 n q nq nq。
为什么可以这样做呢?因为这样做是对的。新添加的点 n q nq nq是 q q q的一个后缀,于是 q q q能转移到的点, n q nq nq也一定能够转移到。同时 p p p加上字符 t t t得到 n q nq nq, n o w now now加上字符 t t t得到 n p np np,跟上一种情况类似, n q nq nq中的字符串也是 n p np np中的字符串的后缀。
含有 q q q和 n p np np的公共后缀的点,如果有字符 t t t的转移边,则只能转移到 n q nq nq。(by hdhd)
struct node{int to[26],len,fa;};
struct suffix_automaton{
node n[maxn*2];
int tot=1,rt=1,now=1;
void insert(int t){
int p=now,q,np=++tot,nq;
now=np,n[np].len=n[p].len+1;
for(;p&&!n[p].to[t];p=n[p].fa)n[p].to[t]=np;
if(!p)n[np].fa=rt;
else{
q=n[p].to[t];
if(n[q].len==n[p].len+1)n[np].fa=q;
else{
nq=++tot,n[nq].len=n[p].len+1;
memcpy(n[nq].to,n[q].to,sizeof(n[q].to));
n[nq].fa=n[q].fa,n[q].fa=n[np].fa=nq;
for(;n[p].to[t]==q;p=n[p].fa)n[p].to[t]=nq;
}
}
}
};
后缀链接树上的动态规划
确定讨论的方向:先讨论儿子结点再讨论父亲节点。可以另外建树,采用树形动规。也可以将结点按 l e n len len排序。
...
struct suffix_automaton{
node n[maxn*2];
int id[maxn*2],c[maxn*2];
int tot=1,rt=1,now=1;
...
void dp(){
for(int i=1;i<=tot;i++)c[n[i].len]++;
for(int i=1;i<=tot;i++)c[i]+=c[i-1];
for(int i=1;i<=tot;i++)id[c[n[i].len]--]=i;
...
}
};
PS:对于代码中这种奇妙的线性排序方式,有的地方说是基数排序,有的地方说是桶排序,但是在本人印象中这是计数排序……具体是什么还需深究。
排序过后 i d [ i ] id[i] id[i]记录了 l e n len len长度第 i i i大的结点。按照 l e n len len从大到小讨论,因为 l e n [ i ] > l e n [ f a [ i ] ] len[i]>len[fa[i]] len[i]>len[fa[i]],这样保证了在讨论到父亲之前讨论完所有儿子结点。
右集合的大小
记 s i z e [ i ] size[i] size[i]为结点 i i i右集合的大小。每个结点 s i z e size size的初始值是 1 1 1,但根结点与构造自动机时额外添加的点 n q nq nq的 s i z e size size值初始为 0 0 0。
Q1: 为什么 n q nq nq的 s i z e size size值为 0 0 0?
A1: 构造SAM的时候, n q nq nq和 q q q其实是相同的点,避免计算重复。
s i z e [ i ] = ∑ f a [ j ] = i s i z e [ j ] size[i]=\sum_{fa[j]=i}size[j] size[i]=fa[j]=i∑size[j]
解读: 右集合的性质:任意两个子串的右集合要么不相交,要么包含。
所有满足 f a [ j ] = i fa[j]=i fa[j]=i的 j j j都是兄弟,且公共父亲为 i i i,所以一定都不相交,且都包含于 i i i,直接加起来就好了。
DAG上的动态规划
不同子串个数
记 s u m [ i ] sum[i] sum[i]为经过结点 i i i的不同的子串个数。
容易得到方程:
s u m [ i ] = 1 + ∑ j ∈ t o [ i ] s u m [ j ] sum[i]=1+\sum_{j\in to[i]}sum[j] sum[i]=1+j∈to[i]∑sum[j]
解读: 经过结点 i i i,可以到结点 i i i停止转移,也可以继续转移向由 i i i转移后的结点 j j j。
弦论(隐藏)
问题描述
对于一个给定长度为 N N N的字符串,求它的第 K K K小子串是什么。
输入格式
第一行是一个仅由小写英文字母构成的字符串 S S S。
第二行为两个整数 T T T和 K K K, T T T为 0 0 0则表示不同位置的相同子串算作一个。 T T T为 1 1 1则表示不同位置的相同子串算作多个。 K K K的意义如题所述。
输出格式
输出仅一行,为一个数字串,为第 K K K小的子串。如果子串数目不足 K K K个,则输出 − 1 -1 −1。
样例输入
aabc
0 3
样例输出
aab
提示
N ⩽ 5 × 1 0 5 , T < 2 , K ⩽ 1 0 9 N\leqslant 5\times 10^5,T<2,K\leqslant 10^9 N⩽5×105,T<2,K⩽109
初识SAM,看到的每一道题都特别吓人……
构造完SAM后,同样记下每个结点的 s i z e size size和 s u m sum sum, s i z e size size的求法同上,由于有相同的子串是否算作一个子串之分, s u m sum sum的求法有变动。其实就是到了一个结点停下来不再转移的时候该子串在原串中有不同的位置。
s u m [ i ] = { 1 + ∑ j ∈ t o [ i ] s u m [ j ] t = 0 s i z e [ i ] + ∑ j ∈ t o [ i ] s u m [ j ] t = 1 sum[i]=\begin{cases} 1+\sum_{j\in to[i]}sum[j]&t=0\\ size[i]+\sum_{j\in to[i]}sum[j]&t=1 \end{cases} sum[i]={1+∑j∈to[i]sum[j]size[i]+∑j∈to[i]sum[j]t=0t=1
由于题目要求输出第 K K K小的子串, t = 0 t=0 t=0时有一种图pie tuo的办法,就是把根结点以外的所有点的 s i z e size size改为 1 1 1。
Q2: 为什么 t = 0 t=0 t=0时可以把 s i z e size size改为 1 1 1?
A2: 同一个子串在不同的位置出现只算做一个,就相当于只在一个位置出现过。
Q3: 这个时候怎么 n q nq nq的 s i z e size size不改成 0 0 0了?
A3: 因为这时的 s i z e size size是实际的右集合大小,而不是打牌前的初始值。修改后不用再打牌。也不能打牌。
#include