Flink说明文档介绍---数据流编程模型
文章内容是通过相应的链接地址翻译过来的
抽象等级
程序和数据流
并行数据流
窗口
时间
有状态的操作
针对检查点的容错
批处理流
下一步
Flink提供不同级别的抽象来开发流/批处理应用程序。
接下来我们针对上面的每一个部分进行分析。
1、抽象等级
Stateful Stream Processing:是最低级别的抽象,它通过Process Function嵌套到DataStream API之中。它使得用户可以自由的处理一个或多个流中的事件,同时能够使用固定的容错状态。此外,用户可以注册回调事件时间和处理时间,让程序能够实现复杂的计算。
实际上,大部分程序不需要上面描述的低级别抽象,而是使用Core APIs(核心api),比如像DataStream API(有边界/无边界的数据流)和DataSet API(有边界的数据集)。这些流畅的API提供了通用的数据处理,像用户指定的各种各样形式的转化,joins(连接),aggregations(聚合),windows(窗口化操作),state(状态)等等,这些API中的数据类型在不同的编程语言中对应不同的类。低阶的处理函数集成了DataStream API,这样就可以针对特性的操作使用低层级的抽象。DataSet API 为有边界的 data sets提供了附加的原语,例如循环/迭代。
Table API是一种声明式的DSL环绕表,它可能会被动态修改(当处理数据流的时候)。Table API遵循可扩展的关系模型:Table有一个附加模式(类似于关系型数据库表)并且API提供了类似的操作,如select,project,join,group-by,aggregate(合集),等等。Table API声明式确切地定义了逻辑应该怎么做。尽管table API是可扩展的通过用户各种形式的自定义函数,它的表现还是不如Core APIs,但用起来代码简洁。此外,Table API可以在运行前执行优化操作。开发人员可以毫无障碍的在table和DataStream/DataSet之间进行切换,程序中可以将Table API和DataStream和DataSet APIs混合在一起使用。
Flink提供的最高等级的抽象是sql,在语义和表达上面这个类似于Table API,只是使用SQL表达式来进行相关操作,SQL层与Table API之间进行交互,SQL的查询在执行的时候会调用Table API。
2、程序和数据流
Flink程序的基本构建模块是streams(流)和transformations(转换)。(需要注意的是,flink的dataSet API所使用的DataSets内部也是流,更多内容以后解释)。从概念上讲流(可能没有结束)是一个数据流记录,而转换是一个操作,将一条或多条数据输入,然后生产出一条或多条数据。当执行的时候,Flink程序映射到Streaming dataflows,这个由数据流和转换操作组成。每一个dataflows开始于一个或多个source,终止于一个或多个sink。dataflows类似于有向无环图(DAGs)。虽然迭代构造运行特定形式的环被允许,但是大多数情况下,简单起见,我们都不考虑这一点。
一般情况下,程序中的转换和数据流中的操作是一一对应的,但有的时候一个转换也可能由多个转换操作组成。source和sink的文档在streaming connectors 和 batch connectors 。transformation的文档在dataStream operators和dataSet transformation。
3、并行数据流
Flink程序本质上是并行的和分布式的,在执行过程中,一个流(stream)包含一个或多个流分区,而每一个operator包含一个或多个operator子任务。操作子任务间彼此独立,在不同的线程中执行,甚至是在不同的机器或不同的容器上。operator子任务的数量是这一特定operator的并行度。一个流的并行度是其生产operator的并行度。相同程序中的不同operator有不同级别的并行度。
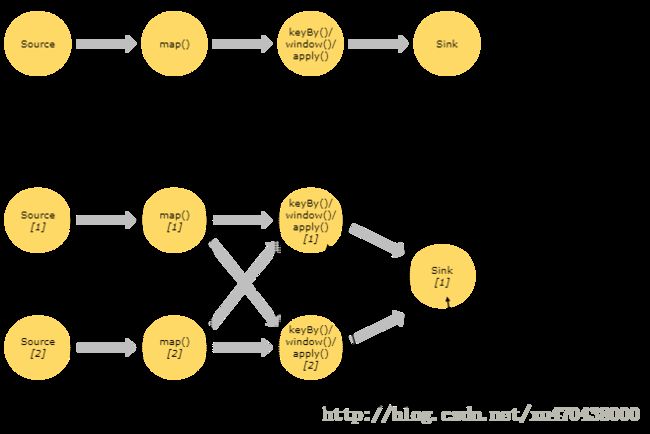
流在两个operator之间传输数据,可以通过一对一模式,或者通过redistributing模式:
(1) 一对一流(例如上图中Source与map() opreator之间)保持了元素的分区与排序。那意味着map() operator的子任务[1]将以与Source的子任务[1]生成顺序相同的顺序查看到相同的元素。
(2) Redistributing 流(如上图中 map() 与 keyBy/window 之间,以及 keyBy/window 与 Sink 之间)则改变了流的分区。每一个operator子任务 根据所选择的转换,向不同的目标子任务发送数据。比如 keyBy() (根据key的哈希值重新分区), broadcast() ,或者 rebalance() (随机重分区)。在一次 redistributing 交换中,元素间的排序只保留在每对发送与接受子任务中(比如, map() 的子任务[1]与 keyBy/window 的子任务[2])。因此在这个例子中,每个键的顺序被保留下来,但是并行确实引入了对于不同键的聚合结果到达sink的顺序的不确定性。
配置和并行度的详细配置可以查看这个文档parallel execution
4、窗口
聚合事件(例如:计数、求和)在流上的工作方式和批处理不同。例如,对流中的所有元素进行计数是无法做到的,因为流通常是无限多的,相反,流上的聚合需要由窗口来划定范围,比如"针对过去5分钟的数据进行统计"、"对最后100个元素进行求和"。
窗口可以是时间驱动的(例如:每30秒),也可以是数据驱动的(例如:每100个元素)。窗口通常被区分为不同的类型,比如滚动窗口(没有重叠),滑动窗口(有重叠),以及会话窗口(由不活动的间隙所打断)。
更多关于窗口的例子可以查看这里,更多关于窗口的明细查看这里
5、时间
当提到流程序(例如定义窗口),你可以参考不同的时间概念:
事件时间是事件创建时的时间,在事件中它通常被描述为时间戳,例如依附于生产传感器,或者生产服务。Flink通过timestamp assigners来访问事件时间戳。
摄入时间是事件进入到Flink源操作数据流的时间。
处理时间是每一个执行时间操作的operator的本地时间。
更多如何处理时间的细节查看这里
6、有状态操作
尽管数据流中的很多操作一次只查看一个独立的事件(比如事件解析器),有些操作却会记录多个事件间的信息(比如窗口运算符),这些操作都称为有状态的。
有状态操作的状态保存在一个可被视作嵌入式键/值存储的部分中。这个状态被严格地按照分区分布式方式与被有状态操作读取的流放在一起。所以我们只能在keyed streams中访问键/值状态,并且仅限于当前事件键相关联的值。调整流和状态的键确保所有状态更新都是在本地操作,以保证在没有事务开销的情况下保持一致。这种对齐还使得Flink可以透明的重新分配状态与调整流的分区。
关于更多细节,请查看这里
7、容错校验点
Flink采用stream replay(流重放)和检查点的组合来实现容错。检查点与每一个输入流及其相关的每一个运算符的状态的特定点相关联。一个数据流可以从一个检查点恢复出来,其中通过恢复operator状态并从检查点重放事件以保持一致性 (一次处理语义)。
检查点间隔是以恢复时间(需要重放的事件数量)来消除执行过程中容错的开销的一种手段
容错内部的描述提供了更多关于flink管理检查点和相关的话题。启用和配置检查点的详细信息请查看这个文档checkpointing API docs。
8、批量流处理
Flink将批处理程序作为流程序的特殊情况来处理,只是流是有边界的(限定元素的个数)。一个DataSet在内部被当做是一个数据流。
上述适用于流处理程序的概念同样适用于批处理程序,除了一些例外:
(1)、批处理程序的容错不再使用检查点。而是通过完全地重放流来恢复。因为输入是有界的,因此这是可行的。这种方法使得恢复的成本增加,但是由于避免了检查点,因而使得正常处理的开销更小。
(2)、DataSet API中的有状态操作使用简化的in-memory/out-of-core数据结构,而不是键/值索引。
(3)、DataSet API引入了特殊的同步(superstep-base)迭代,而这种迭代仅仅能在有界流上执行。细节可以查看迭代文档。
9、下一步
我们继续介绍分布式运行的基本概念