ES学习笔记
文章目录
-
- ES集群部署
-
-
- 集群(Cluster):
- 节点(Node):
-
- ES数据结构
-
-
- 分片(Shard):
- 副本(replica):
- 数据源(river):
- 索引(Index):
- 类型(Type):
- 映射(mapping):
- 文档(Document):
- 字段(field):
- 索引词(term):
- 文本(text):
- 分词(analysis):
- 数据恢复(recovery):
- 与关系型数据库的对比:
-
- ES的增删改查
ES集群部署
集群(Cluster):
集群,Cluster,包含多个节点,每个节点属于哪个集群是通过一个配置(集群名称,默认是 elasticsearch)来决定的,对于中小型应用来说,刚开始一个集群就一个节点很正常。elasticsearch 的集群搭建简单并且容易扩展。
节点(Node):
集群中的每一个节点也有一个名称(默认是随机分配的),节点名称很重要(在执行运维管理操作的时候),默认节点会去加入一个名称为“elasticsearch”的集群,如果直接启动一堆节点,那么它们会自动组成一个 elasticsearch 集群,当然一个节点也可以组成一个 elasticsearch 集群。
ES数据结构

分片(Shard):
单台机器无法存储大量数据,es 可以将一个索引中的数据切分为多个 shard,分布在多台服务器上存储。有了 shard 就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能。每个 shard 都是一个 lucene index。分片的好处是:允许水平切分/扩展集群容量;可在多个分片上进行分布式的、并行的操作,提高系统的性能和吞吐量。
副本(replica):
任何一个服务器随时可能故障或宕机,此时 shard 可能就会丢失,因此可以为每个 shard 创建多个 replica 副本。replica 可以在 shard 故障时提供备用服务,保证数据不丢失,多个 replica 还可以提升搜索操作的吞吐量和性能。primary shard(建立索引时一次设置,不能修改,默认 5 个),replica shard(随时修改数量,默认1个),默认每个索引 10 个 shard,5 个 primary shard,5 个 replica shard,最小的高可用配置,是 2 台服务器。
[主要分片(primary sahrd) 复制分片(replica shard)]
副本主要解决单点问题,提高可用性和容错性: 某个节点失败时服务不受影响, 可以从副本中恢复;提高查询效率和查询时的吞吐量: 搜索可以在所有的副本上并行执行,提高了服务的并发量。主分片和副本分片不能存储在同一个节点中,因为这样做无法保证高可用
数据源(river):
从其他存储方式 (如数据库) 中同步数据到ES的方法, 它是以插件方式存在的一个 ES 服务, 通过读取 river 中的数据并把它索引到 ES 中。官方的 river 有 CouchDB、RabbitMQ 等。
索引(Index):
索引是包含一堆有相似结构的文档数据,比如可以有一个客户索引,商品分类索引,订单索引,索引有一个名称。一个 index 包含很多 document,一个 index 就代表了一类类似的或者相同的 document。比如说建立一个 product index,商品索引,里面可能就存放了所有的商品数据,所有的商品 document。
类型(Type):
每个索引里都可以有一个或多个 type,type 是 index 中的一个逻辑数据分类,一个 type 下的 document,都有相同的 field,比如博客系统,有一个索引,可以定义用户数据 type,博客数据 type,评论数据 type。
映射(mapping):
类似于关系数据库中的 Table 结构,每个 index 都有一个映射: 定义索引中每个字段的类型。所有文档在写进索引之前都会先进行分析,如何对文本进行分词、哪些词条又会被过滤,这类行为叫做映射(mapping)。映射可以提前定义,也可以在第一次存储文档时自动识别,一般由用户自己定义规则。类似于 Solr 中 schema.xml 约束文件的作用。
文档(Document):
文档是 es 中的最小数据单元,一个 document 可以是一条客户数据,一条商品分类数据,一条订单数据,通常用 JSON 数据结构表示,每个 index 下的 type 中,都可以去存储多个 document。一个 document 里面有多个 field,每个 field 就是一个数据字段。
字段(field):
字段可以是一个简单的值(如字符串、数字、日期), 也可以是一个数组,还可以嵌套一个对象或多个对象。字段类似于关系数据库中表数据的列,每个字段都对应一个类型。可以指定如何分析某一字段的值,即对 field 指定分词器。
索引词(term):
在 ES 中,索引词(term)是一个能够被索引的精确值,可以通过 term query 进行准确搜索。
文本(text):
文本是一段普通的非结构化文字,通长文本会被分析成多个 Term,存储在 ES 的索引库中。文本字段一般需要先分析再存储,查询文本中的关键词时,需要根据搜索条件搜索出原文本。
分词(analysis):
analysis 是将文本转换为索引词的过程,分析的结果依赖于分词器。
数据恢复(recovery):
数据恢复又叫数据重新分布。当有节点加入或退出时,ES 会根据机器的负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。Kibana 工具中通过 GET _cat/health?v,就可以看到集群所处的状态。
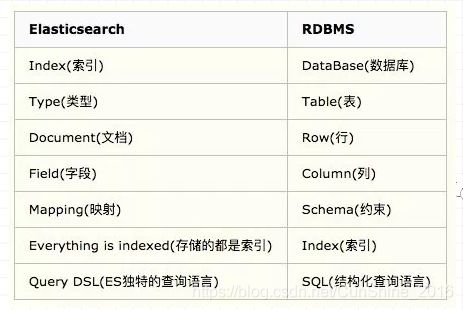
与关系型数据库的对比: