C#控制台/梅花易数一撮金小游戏的教学
封建迷信不可取,沉迷此道降智商
首先看看结果
 输入命理 二字
输入命理 二字
可以得到一首诗
具体的操作我列一下
1,获取汉字的笔画
2,通过汉字笔画所得数进行运算
3.在数据中获取满足条件的一行诗句
其中有一些难点我会告诉大家z’g
这个是背景知识
http://www.360doc.com/content/17/1007/23/4530213_693070023.shtml
直接开叭
首先 这个我还是用到数据库 SQLServer 以及EntityFramwork框架
具体的数据在这
http://www.95yijing.com/article/zhishi/meihua/150.html
把这个写入数据库
应该怎么写入呢?
把他复制粘贴成txt文本 大家都会吧
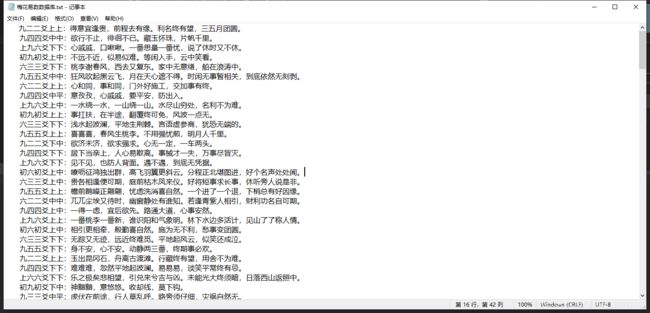
类似这样
在数据库中新建一张biao
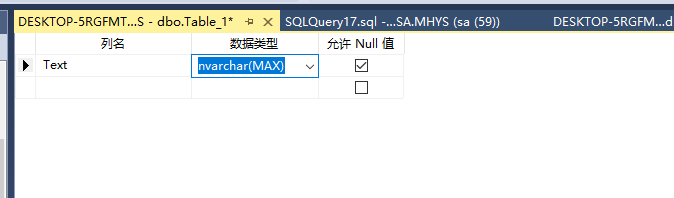
然后导入数据库
1.如何将Txt文本文件导入SQLServicer自建的表?
答:
Bulk insert A表
From 'F:\test.txt'
With
(
//txt文件如何让sql识别那个是行?那个是列?
//行的分割 如 1,张三,爱好篮球
fieldterminator=',',
//列的分割
rowterminator='\n')
这样 sql语句就会根据表的格式读取数据
以上示例中 逗号拆成一行一行 换行符拆成一列一列
什么意思?
好吧 我举个例子

新建表 名为student
新建一个txt文档


 就可以了
就可以了
大火思索一下 应该懂的吧
数据库里其实有对汉字的不支持的
第二个问题
sqlserver的解码要求
txt文本是utf-8
而sql是gbk
要导入 必会有乱码
解决方法是用NotePad++

粘贴到上面 转码 另存为txt格式
就行了

 这里有一个自增Id的制作
这里有一个自增Id的制作
DECLARE @i int
SET @i=0
UPDATE A表 SET @i=@i+1,Id=@i
这样 就得到了一个包含文本的test表
再新建一张
名为GroupIndexOnebyOne
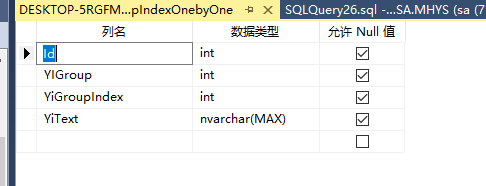
但是最终的表 应该是这样
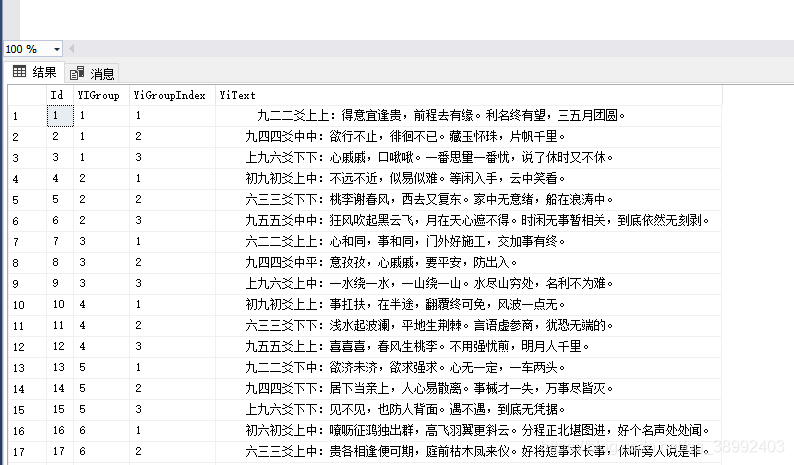 差距就在于前面的YiGroup YiGroupIndex这些结构
差距就在于前面的YiGroup YiGroupIndex这些结构
先写好结构吧
以下可能有点复杂
梅花易数的数据结构
八卦X八卦
一共64卦
一卦有三首诗
一共有 192条诗
既然64卦 一卦3 首
那我们就把YIGrop设置为一卦

这3首诗都在1个卦象内
PS:好像是乾天卦?
所以 懂我的意思吗
 192/3 = 64
192/3 = 64
之后就是在数据库输入数据结构
我偷懒了(sb才一个一个输吧)
 用了几个循环加IO
用了几个循环加IO
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.IO;
namespace JUZHEN
{
class Program
{
static void Main(string[] args)
{
int ind = 0;
List<int> myList = new List<int>();
for (int j = 1; j <= 64; j++)
{
for (int i = 1; i <= 3; i++)
{
ind++;
Console.WriteLine(ind + ","+j + "," + i);
StreamWriter sw = new StreamWriter(@"F:\txtstr1.txt", true);
sw.WriteLine(ind + "," + j + "," + i);
sw.Close();
}
}
Console.ReadLine();
}
}
}
OK 搞定了数据库
再吧test的Text列转移过最终的表这里来 最终的表名字:GroupIndexOnebyOne
```csharp
UPDATE GroupIndexOnebyOne
SET YiText=test.YiText
FROM test
WHERE GroupIndexOnebyOne.Id=test.Id
数据库的搭建结束

 获取汉字笔画
获取汉字笔画
网上有
但是代码太长了 我不想发了 另一个文章有 自己找找吧 关键词:获取汉字笔画
主体
string firstHanZi = "诚";
string secondHanZi = "佛";
string zuheHanZi = firstHanZi + secondHanZi;
int firstNums;
int secondNums;
int zuheNums;
int zuheNumsChuSix;
if (GetStrokeCount(firstHanZi) <= 8)
{
firstNums = GetStrokeCount(firstHanZi);
}
else
{
firstNums = GetStrokeCount(firstHanZi) % 8;
}
if (GetStrokeCount(secondHanZi) <= 8)
{
secondNums = GetStrokeCount(secondHanZi);
}
else
{
secondNums = GetStrokeCount(secondHanZi)% 8;
}
Console.WriteLine(string.Format("\"{0}\"的总笔画数为:{1}", zuheHanZi, GetStrokeCount(zuheHanZi)));
zuheNums = GetStrokeCount(zuheHanZi);
zuheNumsChuSix = zuheNums % 6;
Console.WriteLine("总笔画%6:"+ zuheNumsChuSix);
Console.WriteLine("卦数1:{0},卦数2:{1},总笔画%6:{2}", firstNums,secondNums,zuheNumsChuSix);
//我们只需要 3 个 数字
// 卦1 卦2 和余数
var NeiGua = mycontext.MeiHuaData.Where(p => p.YiId == firstNums).Select(p=>p.YiGroup);
var WaiGua = mycontext.MeiHuaData.Where(p => p.YiId == secondNums).Select(p => p.YiGroup);
if (zuheNumsChuSix == 0)
{
zuheNumsChuSix = 3;
}
if (zuheNumsChuSix == 2)
{
zuheNumsChuSix = 1;
}
if (zuheNumsChuSix == 3)
{
zuheNumsChuSix = 2;
}
if (zuheNumsChuSix == 4)
{
zuheNumsChuSix = 2;
}
if (zuheNumsChuSix == 5)
{
zuheNumsChuSix = 3;
}
if (zuheNumsChuSix == 6)
{
zuheNumsChuSix = 3;
}
var GetYiGroup = mycontext.MeiHuaData.Where(p=>p.YiGroup == firstNums*secondNums ).Where(q => q.YiGroupIndex == zuheNumsChuSix).Select(r=>r.YiText);
foreach (var ss in GetYiGroup)
{
Console.WriteLine("YiShuGroup:"+ss);
}
foreach (var ss in NeiGua)
{
Console.WriteLine("NeiGua:" + ss);
}
foreach (var ss in WaiGua)
{
Console.WriteLine("WaiGua:" + ss);
}
List<string> myList = new List<string>();
switch (firstNums)
{
case 1:
Console.WriteLine("乾");
break;
case 2:
Console.WriteLine("兑");
break;
case 3:
Console.WriteLine("离");
break;
case 4:
Console.WriteLine("震");
break;
case 5:
Console.WriteLine("巽");
break;
case 6:
Console.WriteLine("坎");
break;
case 7:
Console.WriteLine("艮");
break;
case 8:
Console.WriteLine("坤");
break;
default:
Console.WriteLine("你的汉字有误");
break;
}
switch (secondNums)
{
case 1:
Console.WriteLine("乾");
break;
case 2:
Console.WriteLine("兑");
break;
case 3:
Console.WriteLine("离");
break;
case 4:
Console.WriteLine("震");
break;
case 5:
Console.WriteLine("巽");
break;
case 6:
Console.WriteLine("坎");
break;
case 7:
Console.WriteLine("艮");
break;
case 8:
Console.WriteLine("坤");
break;
default:
Console.WriteLine("你的汉字有误");
break;
}
Console.ReadLine();
}
}
}
获取哪一卦的方法就是 卦1X卦2 定位到

都在lambda函数那
也没时间优化了
找时间unity版本做出来