Hive(一):row_number over(partition by,order by)用法
这篇博客 ROW_NUMBER() OVER()函数用法详解 (分组排序 例子多) 讲的很详细
语法格式:row_number() over(partition by 分组列 order by 排序列 desc)
注意: 在使用 row_number() over()函数的时候,over()里面的分组以及排序的执行晚于 where、group by、order by 的执行。
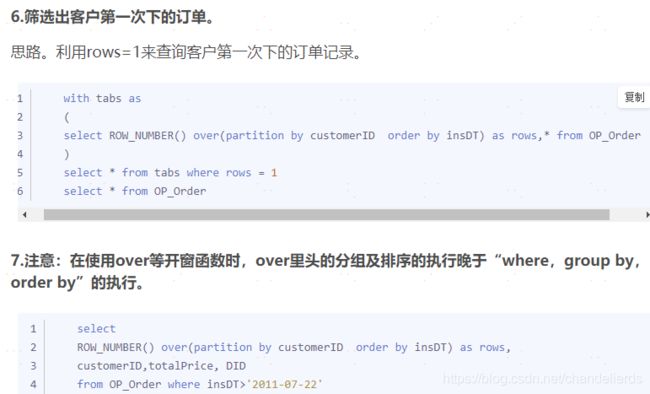
按照他的例子进行了实现: 新建Hive表tmp_learning_mary如图
drop table if exists tmp_learning_mary;
create table if not exists tmp_learning_mary(
id varchar(10),
name varchar(10) ,
age varchar(10),
salary int
);
insert into tmp_learning_mary(id,name,age,salary) values(1,'a',10,8000);
insert into tmp_learning_mary(id,name,age,salary) values(1,'a2',11,6500);
insert into tmp_learning_mary(id,name,age,salary) values(2,'b',12,13000);
insert into tmp_learning_mary(id,name,age,salary) values(2,'b2',13,4500);
insert into tmp_learning_mary(id,name,age,salary) values(3,'c',14,3000);
insert into tmp_learning_mary(id,name,age,salary) values(3,'c2',15,20000);
insert into tmp_learning_mary(id,name,age,salary) values(4,'d',16,30000);
insert into tmp_learning_mary(id,name,age,salary) values(5,'d2',17,1800);
select * from tmp_learning_mary;
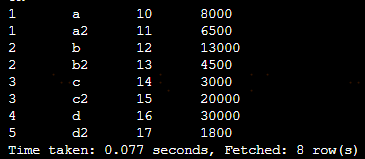
1.按照id分组,不排序
select *, row_number()over(partition by id) from tmp_learning_mary;
结果

最后一列中,每个分组内的排序是随机的
2.按照salary进行降序排序,不分组(排序列命名为ranking)
select *, row_number()over(order by salary desc) ranking from tmp_learning_mary
结果为: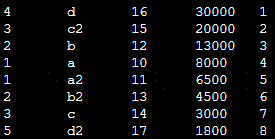
3.按照salary降序排序,同时根据id进行分组
select *, row_number()over(partition by id order by salary desc) ranking
from tmp_learning_mary;
结果为:

4.在2的基础上,找出每一组中序号为1的数据
select * from(select *, row_number()over(partition by id order by salary desc) ranking
from tmp_learning_mary) t where t.ranking < 2;
这里注意子查询语句中的表格一定要加上一个命名,我原来没有命名为t,导致报错:
![]()
错误信息为无法识别where那一块的语句,因此我把子查询语句的表命名为t,where语句写为where t.ranking < 2后可以正常运行。
还可以利用with table as的写法,具体可参考博文:Hive(二):with as用法
with t as (select *, row_number()over(partition by id order by salary desc) ranking
from tmp_learning_mary)
select * from t where ranking = 1;
最后的结果为:

5.找出年龄在13岁到16岁数据,按salary排序
select *, row_number()over(order by salary desc) ranking
from tmp_learning_mary where age between '13' and '16';
结果:
从结果中的ranking可以看出,是先进行了where语句的筛选,再进行了排序,即over()里面的分组排序是在where之后的。
6.按id进行分组,每组随机排序,找到每组序号为1的数据
随机排序的可以用order by rand()表示随机排序,这种需求可以用在对各个分组的随机采样上
select * from (select *,row_number()over(partition by id order by rand()) ranking
from tmp_learning_mary) t where t.ranking = 1;
结果:
博客中还有几点需求的是实现在工程中非常有用: