Streamsets自定义组件开发
需求痛点
在实际项目的使用过程中,有些情况下现有的组件不能完全满足具体的业务需求,比如JDBC插入数据不是真正的batch提交的、较低版本的没有提供FieldMapper和FTP/SFTP写入客户端等。这就需要我们自己编写需要的组件实现想要的功能。
开发步骤
按照官方文档提供的指南实现起来还是很容易的,下面就以JdbcQueryExecutor为例,详细介绍一下自定义开发的过程:
首先生成项目
mvn archetype:generate -DarchetypeGroupId=com.streamsets \
-DarchetypeArtifactId=streamsets-datacollector-stage-lib-tutorial \
-DarchetypeVersion=3.9.0-SNAPSHOT -DinteractiveMode=true
#执行上面的代码之后,会提示需要输入项目的包路径名和项目名称,我这里输入如下,你可以根据需要修改成自己的
com.embrace
jdbcbatch
编译项目为IDEA项目
cd jdbcbatch/
mvn idea:idea
然后使用IDEA打开项目,编写组件的代码,我这里是对JdbcQueryExecutor做一些修改,所以在Streamsets源代码中找到对应的组件类,拷贝过来,做一些修改就可以了。
组件代码导入
组件的核心代码如下图所示
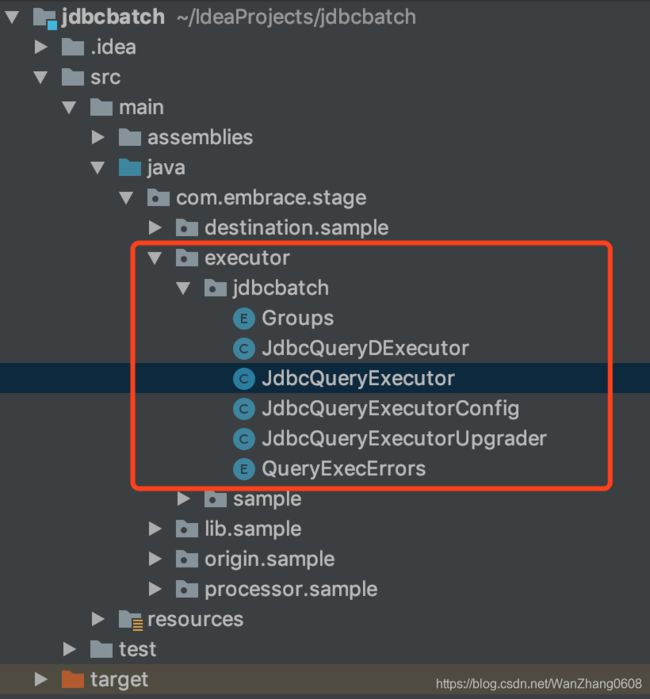
这些代码拷贝过来之后,会有报错的地方,因为依赖的其他类,这里就需要在pom文件中引入需要的包:
<properties>
<hikaricp.version>3.2.0hikaricp.version>
properties>
<dependency>
<groupId>com.streamsetsgroupId>
<artifactId>streamsets-datacollector-apiartifactId>
<version>3.9.0-SNAPSHOTversion>
<scope>providedscope>
dependency>
<dependency>
<groupId>com.streamsetsgroupId>
<artifactId>streamsets-datacollector-stagesupportartifactId>
<version>3.9.0-SNAPSHOTversion>
dependency>
<dependency>
<groupId>com.streamsetsgroupId>
<artifactId>streamsets-datacollector-jdbc-protolibartifactId>
<version>3.9.0-SNAPSHOTversion>
dependency>
<dependency>
<groupId>com.zaxxergroupId>
<artifactId>HikariCPartifactId>
<version>${hikaricp.version}version>
dependency>
组件修改
首先修改组件名称,在JdbcQueryDExecutor类中
@StageDef(
version = 2,
label = "Batch JDBC Query", # JDBC Query改为 Batch JDBC Query
description = "Executes queries against JDBC compliant database",
upgrader = JdbcQueryExecutorUpgrader.class,
icon = "rdbms-executor.png",
onlineHelpRefUrl ="index.html?contextID=task_ym2_3cv_sx"
)
然后修改核心代码,在JdbcQueryExecutor类中的write方法
@Override
public void write(Batch batch) throws StageException {
ELVars variables = getContext().createELVars();
ELEval eval = getContext().createELEval("query");
try (Connection connection = config.getConnection()) {
connection.setAutoCommit(false);//close auto commit
Iterator<Record> it = batch.getRecords();
Statement stmt = connection.createStatement();//one Statement for one batch
try {
while (it.hasNext()) {
Record record = it.next();
RecordEL.setRecordInContext(variables, record);
String query = eval.eval(variables, config.query, String.class);
LOG.debug("Executing query: {}", query);
stmt.addBatch(query); //change stmt.execute(query) to stmt.addBatch(query)
}
int[] updateCounts= stmt.executeBatch(); //execute batch
LOG.info("execute batch count:"+ updateCounts.length);
} catch (SQLException ex) {
LOG.error("Execute batch query failed", ex);
} finally {
try {
if (stmt != null)
stmt.close();
} catch (SQLException se2) {
}
}
if (config.batchCommit) {
connection.commit();
}
} catch (SQLException ex) {
LOG.error("Can't get connection", ex);
throw new StageException(QueryExecErrors.QUERY_EXECUTOR_002, ex.getMessage());
}
}
编译打包
mvn package -DskipTests
部署自定义组件
把target目录下生成的jdbcbatch-1.0-SNAPSHOT.tar.gz压缩包解压到Streamsets安装目录下的user_libs下
cd ~/IdeaProjects/datacollector/dist/target/streamsets-datacollector-3.9.0-SNAPSHOT/streamsets-datacollector-3.9.0-SNAPSHOT/user-libs/
tar xvfz ~/IdeaProjects/samplestage/target/jdbcbatch-1.0-SNAPSHOT.tar.gz jdbcbatch/lib/
修改安全策略文件
修改文件etc/sdc-security.policy,增加如下内容
grant codebase "file://${sdc.dist.dir}/user-libs/batchjdbc/-" {
permission java.security.AllPermission;
};
测试自定义组件
增加新组建后需要重启Streamsets,然后在页面就可以看到

测试后速度比原来的组件有所提升,需要的话可以在我的github上查看代码,欢迎提出意见,地址https://github.com/WanZhang1/jdbcbatch
总结
既然有些组件不能满足实际的需求,他们也提供的自定义的方法,就尝试去做修改,发现也不难,编程的乐趣也在于不断解决问题。