python实践gcForest模型对鸢尾花数据集iris进行分类
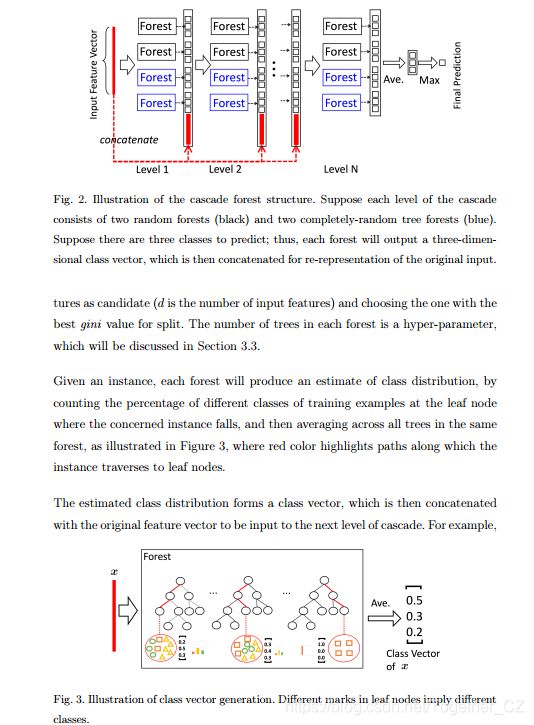
gcForest模型是2018年南京大学机器学习大师周志华老师团队提出来的以决策树和随机森林为基础模型的级联深度森林模型,这个论文我看过了感觉跟我当时硕士期间的一个研究有一点类似,当时我基于XGBOOST的再编码能力有效提升了GBDT模型的分类能力,这个gcForest模型也是需要“再编码”,然后将上一层模型的数据累加到下一层的输入中去。它的表征学习能力可以通过对高维输入数据的多粒度扫描而进行加强。串联的层数也可以通过自适应的决定从而使得模型复杂度不需要成为一个自定义的超参数,而是一个根据数据情况而自动设定的参数。值得注意的是,gcForest会比DNN有更少的超参数,更好的一点在于gcForest对参数是有非常好的鲁棒性,哪怕用默认参数也可以获得很棒的结果。下面是论文中提出的gcForest模型的示意图:
论文中提出了一种Mutil-Grained Scanning的方法,使用窗口切片的方式来进行多粒度的划分,示意图如下:

gcForest的总体结构示意图如下所示:

我们今天并不是要来详细去讨论分析gcForest模型的内部构造和算法原理,而是基于gcForest模型来做一点实践性的工作来看一下这个模型的表现能力怎么样。
官方的源码在这里,一位外国小哥实现的gcForest模块在这里。感兴趣的话都可以去拿去试试,下面是我具体的实现:
#!usr/bin/env python
#encoding:utf-8
from __future__ import division
'''
__Author__:沂水寒城
功能: gcForest 实践
'''
import numpy as np
from GCForest import gcForest
from sklearn.externals import joblib
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris, load_digits
from sklearn.model_selection import train_test_split
def irisFunc():
'''
对鸢尾花数据集进行测试
'''
iris=load_iris()
X,y=iris.data,iris.target
print('==========================Data Shape======================')
print(X.shape,y.shape)
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3)
model=gcForest(shape_1X=4, window=2,tolerance=0.0)
model.fit(X_train,y_train)
#持久化存储
joblib.dump(model,'irisModel.sav')
model=joblib.load('irisModel.sav')
y_predict=model.predict(X_test)
print('===========================y_predict======================')
print(y_predict)
accuarcy=accuracy_score(y_true=y_test,y_pred=y_predict)
print('gcForest accuarcy : {}'.format(accuarcy)) 上述代码中总体来看十分地简洁,gcForest模型的调用方式同sklearn中其他方法的调用接口十分地相似,这个就不需要太多的学习成本了,得到模型后我们先借助于joblib模块实现了模型的持久化存储,之后加载本地保存的模型来对测试数据集进行预测,结果如下图所示:

刚开始执行的时候,给我了一种深度学习模型启动的感觉,O(∩_∩)O哈哈~,我们可以看到准确率达到了97%以上,可见模型的性能还是不错的。
树模型是可以预测类别的概率的,我们这里也来做一下:
def irisFunc():
'''
对鸢尾花数据集进行测试
'''
iris=load_iris()
X,y=iris.data,iris.target
print('==========================Data Shape======================')
print(X.shape,y.shape)
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3)
model=gcForest(shape_1X=4, window=2,tolerance=0.0)
model.fit(X_train,y_train)
y_predict=model.predict_proba(X_test)
y_predict=y_predict.tolist()
print('==========================y_predict======================')
for one_res in y_predict:
print(one_res)结果如下:

从上面的结果截图中可以看到:我将类别概率预测结果转化为列表的形式,依次输出每个样本的预测结果,在每个结果中,都有三个数值,分别对应0类、1类和2类这三个类别模型判定的概率,predict方法就是将最大的概率对应的类别进行输出。
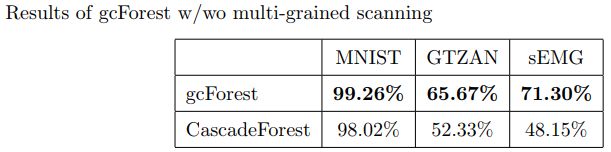
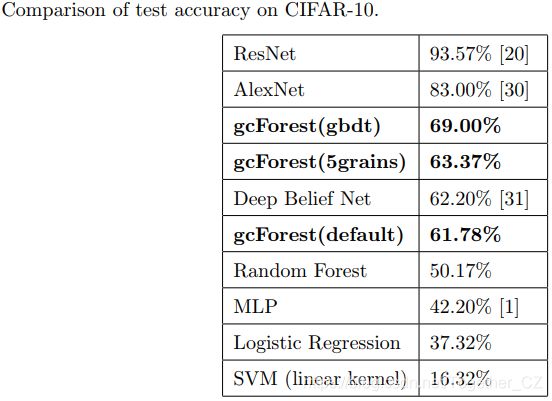
最后简单贴一下原论文中作者给出来的各种模型和数据集上gcForest的对比结果统计:






gcForest模型和多粒度扫描的结果对比: