本章主要分析Scala中List的用法,List上可进行的操作,以及需要注意的地方。
一、List字面量
首先看几个List的示例。
val fruit = List("apples", "oranges", "pears")
val nums = List(1, 2, 3, 4)
val diag3 =
List(
List(1, 0, 0),
List(0, 1, 0),
List(0, 0, 1)
)
val empty = List() 代码运行结果略。
与arrays不同的是,List是imutable的,即List中的元素不能被修改。其次List具有递归结构,比如linked list,而arrays是连续的。
有关List中的元素不能被修改,可以看下面代码。
fruit = "banana" 运行结果:

二、List类型
List变量中的元素都有相同的类型,比如List[T]表示该List对象中所有元素的类型都是T,可以在定义变量时加一个显示的类型声明,如下所示
val fruit: List[String] = List("apples", "oranges", "pears")
val nums: List[Int] = List(1, 2, 3, 4)
val diag3: List[List[Int]] =
List(
List(1, 0, 0),
List(0, 1, 0),
List(0, 0, 1)
)
val empty: List[Nothing] = List() 运行结果略。
List类型是协变的。即,如果S是T的子类,那么List[S]是List[T]的子类。
三、构造List对象
List对象由两个关键字生成,一个是Nil另一个是::。其中Nil代表空的list,::操作符表示将该元素追加到list的前面。所以,前面的代码还可以写成
val fruit = "apples" :: ("oranges" :: ("pears" :: Nil))
val nums = 1 :: (2 :: (3 :: (4 :: Nil)))
val diag3 = (1 :: (0 :: (0 :: Nil))) ::
(1 :: (0 :: (0 :: Nil))) ::
(1 :: (0 :: (0 :: Nil))) :: Nil
val empty = Nil ::操作符从后往前匹配,即A :: B :: C等价于A :: (B :: C),所以,对上面代码中的变量fruit可以写成
val fruit = "apples" :: "oranges" :: "pears" :: Nil四、List上的基本操作
List上的所有操作,底层都可以表示成以下三个: head:获取list中的第一个元素 tail:获取list中除了第一个元素之外的其他元素组成的新list isEmpty:如果当前list为空,返回true
需要注意的是head和tail方法只能作用在非空list上,否则会报错,如下所示
Nil.head 结果如下,
![]()
下面使用者三个方法,实现一个List[Int]类型变量的插入排序代码(升序)。
def isort(xs: List[Int]): List[Int] =
if (xs.isEmpty) Nil
else insert(xs.head, isort(xs.tail))
def insert(x: Int, xs: List[Int]): List[Int] =
if (xs.isEmpty || x <= xs.head) x :: xs
else xs.head :: insert(x, xs.tail) 在方法isort中,如果xs为空,直接返回Nil,否则将xs的第一个元素xs.head调用insert方法插入到xs.tail中。
在方法insert中,如果待插入的xs为空,或者待插入变量x比xs的第一个元素还小,则直接插在xs前面。否则将xs的第一个元素放在最前面,继续排列x和xs除第一个元素之外的其他元素。
五、List模式
List也可以作用在模式匹配的情况下。比如下面代码
val List(a, b, c) = fruit 运行结果如下,直接将fruit中的内容依次赋给变量a, b, c。
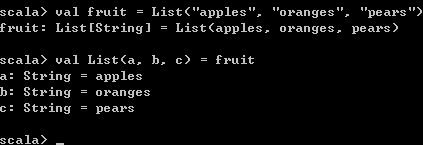
使用上面的代码,表示明确知道fruit变量中的元素个数为3。否则会出现元素个数不匹配的报错,如下
val List(x, y) = fruit 运行结果如下,
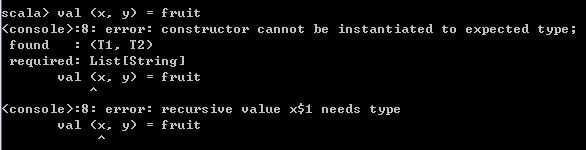
这时如果仍然想要使用模式匹配,可以使用::操作符,如下所示
val a :: b :: c = fruit
val a :: b :: c :: d = fruit
val a :: b :: c :: d :: e = fruit 运行结果如下,会将fruit变量中的第一个元素赋给变量a,第二个元素赋给b,然后将剩下的以List形式赋给变量c。
但是可赋值的变量个数不能超过List中的元素个数加一,在这种情况下最后一个变量d的内容为一个空的List。
如果变量个数超过List中的元素个数加一,就会报错。

使用这个特性改造一下插入排序代码。
def isort(xs: List[Int]): List[Int] = xs match {
case List() => List()
case x :: xs1 => insert(x, isort(xs1))
}
def insert(x: Int, xs: List[Int]): List[Int] = xs match {
case List() => List(x)
case y :: ys => if (x <= y) x :: xs
else y :: insert(x, ys)
} isort方法中,如果传入的xs是一个空List直接返回一个空List,否则,将第一个元素赋值给变量x,调用insert方法插入到剩余元素组成的xs1中。
insert方法中,如果待插入的xs为空,直接返回包含一个元素的List。否则,比较待插入元素x和xs的第一个元素y的大小,将值小的放在前面,组成一个新的List。
六、List上的一阶操作(First-order)
1、:::操作符,合并两个List对象
:::操作符作用于两个List对象上,xs ::: ys表达式的结果是得到一个新的List对象,该对象包含xs和ys中的全部元素,并且xs在前。
List(1, 2) ::: List(3, 4, 5)
List() ::: List(1, 2, 3)
List(1, 2, 3) :: List(4) 运行结果如下,
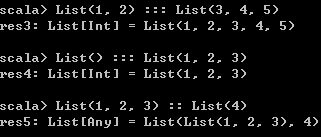
:::操作符和::类似,也是从右向左执行的。所以xs ::: ys ::: zs等价于xs ::: (ys ::: zs)
2、使用分治原则自定义:::功能
前面已经看到了Scala中实现了连接两个List对象的操作:::,如果想要手动实现该功能,比如定义一个append方法,作用与:::相同,应该怎么做?
首先看一下append方法的定义,
def append[T](xs: List[T], ys: List[T]): List[T] 接下来使用分治策略来实现该方法的方法体。前面可以看到,使用List模式匹配能够将一个List对象划分成单个元素或者子List的情况。
def append[T](xs: List[T], ys: List[T]): List[T] =
xs match {
case List() =>
case x :: xs1 =>
} 对于第一个分支,如果xs为空,那么直接返回ys即可,即
case List() => ys对于第二个分支,则继续将其切割成小的元素,
def append[T](xs: List[T], ys: List[T]): List[T] =
xs match {
case List() => ys
case x :: xs1 => x :: append(xs1, ys)
}3、length方法,获取list中元素个数
length方法,获取当前list的长度。所谓长度,是指当前list中有多少个元素。对于List来说,计算其长度,是一个比较耗费时间的操作,时间复杂度与List中的元素个数成正比,因为需要遍历其中每一个元素才能得到List的长度。
所以,xs.isEmpty比xs.length == 0的效率高,虽然两者的作用是相同的。
下面看一个示例,
List(1, 2, 3).length 结果如下,
![]()
4、init和last方法,访问List的尾部
对应前面的head方法,List上有一个last方法,用于访问该list中最后一个元素。如下所示,
List('a', 'b', 'c', 'd', 'e').last 对应于tail方法,init方法获取除去最后一个元素之外其他元素组成的新的List对象,如下所示,
List('a', 'b', 'c', 'd', 'e').init 运行结果如下,

需要注意的是,这两个方法不能作用于空的List上,否则会报错。并且,init和last方法会比tail和head方法是效率低,因为操作List后面的元素,需要遍历整个List对象才能实现。因此,在生成List对象时,最好将经常访问的元素置于List前面。
5、reverse方法,翻转List中的元素顺序
该方法会将List中的元素顺序翻转得到一个与原List顺序相反的新List对象,而不改变之前那个List对象的内容,如下所示,
val abcde = List('a', 'b', 'c', 'd', 'e')
abcde.reverse 运行结果如下,
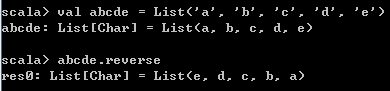
将reverse方法和前面的init, last, head, fail方法结合,有以下一些规律:
- xs.reverse.reverse结果为xs
- xs.reverse.init结果为xs.tail.reverse
- xs.reverse.tail结果为xs.init.reverse
- xs.reverse.head结果为xs.last
- xs.reverse.last结果为xs.head
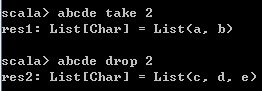
6、drop,take和splitAt方法,前缀和后缀
take方法,xs take n返回xs对象的前n个元素,形成一个新的List对象。
drop方法,xs drop n返回xs对象除了前n个元素之外的其他元素组成的新List对象。
abcde take 2
abcde drop 2 结果如下,
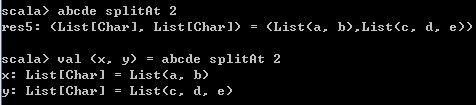
而splitAt方法,xs splitAt n表示从n个元素处,将xs分割成两个List对象。等价于xs take n, xs drop n。
abcde splitAt 2
val (x, y) = abcde splitAt 2 运行结果如下,
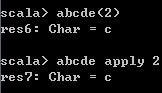
7、apply方法和下标,获取指定元素
List也可以使用下标访问指定元素abcde(2)List对象的apply`方法,等价于上面所示的访问指定位置的元素,所以下面代码和上面的是等价的
abcde apply 2 运行结果如下,
indicies方法,获取当前List对象中所有元素的下标,
abcde.indices 运行结果如下,
![]()
8、flatten方法,展平List[List]对象中的所有元素
这个方法可以将List[List]结构的对象中所有元素展开,返回一个包含所有子List元素的新的List对象,如下,
List(List(1, 2), List(3), List(), List(4, 5)).flatten 运行结果如下,
![]()
注意,该方法只能应用于List[List]的对象上,直接由List对象调用,会报错
List(1, 2, 3).flatten 结果如下,

9、zip和unzip方法,组合两个list对象为pairs形式
直接看示例吧。
abcde.indices zip abcde 结果如下,将前一个List对象的每一个元素与后一个List对象的每一个元素组合成pairs。
![]()
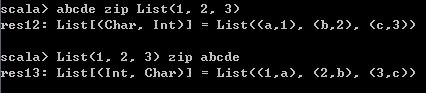
如果前后两个List对象长度不一致,将会返回较短长度的那个结果,
abcde zip List(1, 2, 3)
List(1, 2, 3) zip abcde 结果如下,
在这里还有一个特殊的方法zipWithIndex,作用是将该List对象中的每一个元素与其下标进行zip操作。
abcde.zipWithIndex 运行结果如下,
![]()
unzip方法的作用与zip方法相反,将一个pairs形式的List拆分成两个List对象,
val zipped = abcde zip List(1, 2, 3)
zipped.unzip 运行结果如下,

10、toString和mkString方法,将list中元素拼接成字符串
toString方法略。
mkString方法可以传入一个连接符,用该连接符将List对象中的各个元素拼接起来最终形成一个字符串。也可以指定其前缀和后缀。
abcde mkString "-"
abcde mkString ("[", "-", "]") 运行结果如下,

11、iterator, toArray和copyToArray方法,转换List对象类型
(1)List与Array互转
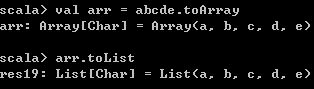
List对象转为Array,
val arr = abcde.toArray Array转List,
arr.toList 运行结果如下,
(2)copyToArray方法
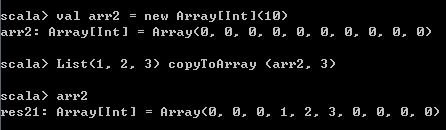
该方法可以将List对象中的元素复制到指定Array对象的指定位置,比如下面代码中,将List(1, 2, 3)中的三个元素插入到arr2对象的第3~5位置上。然后arr2这个Array中的元素个数和内容发生变化。
val arr2 = new Array[Int](10)
List(1, 2, 3) copyToArray (arr2, 3) 运行结果如下,
(3)inerator方法
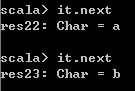
获得当前List对象的迭代器,可以用此迭代器访问下一个元素。
val it = abcde.iterator
it.next
it.next 运行结果如下,
七、List上的高阶操作(Higher-order)
1、map, flatMap, foreach方法,处理List中的每个元素
(1)map方法
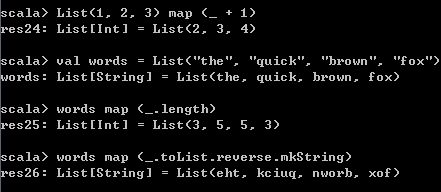
map方法接收一个函数参数,将该函数作用在List的每一个元素上,得到的结果组合成一个新的List对象。
List(1, 2, 3) map (_ + 1)
val words = List("the", "quick", "brown", "fox")
words map (_.length)
words map (_.toList.reverse.mkString) 运行结果如下,
(2)flatMap方法
和map方法有点类似,区别在于flatMap方法接收到的函数对单一元素作用后得到多个结果,会将这些结果返回到一个List对象中。和前面的flatten方法有点类似。
words map (_.toList)
words flatMap (_.toList) 运行结果如下,传入的方法是将当前元素拆分成List对象,所以一个元素经过map后会返回一个List对象,最终形成List[List]的结构。但是flatMap方法会将map得到的每一个List打散,取出其中每一个元素,组合成一个新的List对象并返回。

(3)foreach方法
该方法和map方法类似,也是接收一个函数参数,这个函数参数会作用在List中的每一个元素上。但是这个函数的返回值为Unit,所以其副作用仅仅是比如打印其中的每一个元素,或者改变某个变量的值,比如下面例子中的求和。
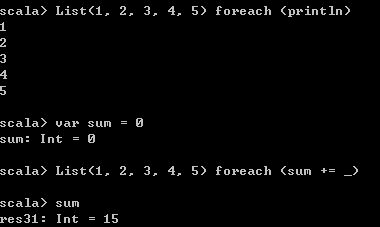
List(1, 2, 3, 4, 5) foreach (println)
var sum = 0
List(1, 2, 3, 4, 5) foreach (sum += _) 运行结果如下,
2、filter, partition, find, takeWhile, dropWhile, span方法,过滤List中的元素
(1)filter方法
传入一个函数参数,最终得到一个新的List对象,包含原List中使该函数参数值为true的元素。
List(1, 2, 3, 4, 5) filter (_ % 2 == 0) // 返回所有偶数
words filter (_.length == 3) // 返回所有字符长度为3的元素 运行结果如下,

(2)partition方法
该方法是filter方法的加强版。filter只会返回时函数参数值为true的一个新List。而partition方法,会同时返回两个List,第一个为函数参数为true的所有元素,第二个为函数参数为false的所有元素。
List(1, 2, 3, 4, 5) partition (_ % 2 == 0) 运行结果如下,
![]()
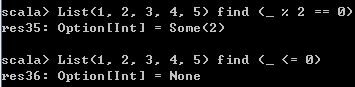
(3)find方法
和filter方法类似,但是find方法只返回List中第一个满足该函数表达式的元素,而不是返回一个List对象。返回值类型为Some(x)或者None。
List(1, 2, 3, 4, 5) find (_ % 2 == 0)
List(1, 2, 3, 4, 5) find (_ <= 0) 运行结果如下,
(4)takeWhile方法
xs takeWhile p获取xs中最前面的所有满足p表达式的元素。
List(1, 2, 3, -4, 5) takeWhile (_ > 0) 运行结果如下,直到遇到-4时不满足该表达式,尽可能长的从第一个元素取满足该表达式的元素。
![]()
(5)dropWhile方法
和takeWhile方法正好相反,尽可能的从第一个元素删除所有满足表达式的元素。
List(1, 2, 3, -4, 5) dropWhile (_ > 0) 运行结果如下,
![]()
(6)span方法
是takeWhile和dropWhile两个方法的结合形式。有点类似于splitAt方法综合了take和drop方法一样。
xs span p等价于xs takeWhile p, xs dropWhile p。
List(1, 2, 3, -4, 5) span (_ > 0) 运行结果如下,
![]()
3、forall, exists方法,判断满足条件元素是否存在
xs forall p,其中xs是一个List类型对象,p是一个判断表达式,只有当xs中每一个元素均使p的结果为true时,整个结果才返回true。而xs exists p表示xs中只要存在任意一个元素使p的结果为true,整个结果返回true。
val diag3 = (1 :: 0 :: 0 :: Nil) ::
(0 :: 1 :: 0 :: Nil) ::
(0 :: 0 :: 1 :: Nil) :: Nil
def hasZeroRow(m: List[List[Int]]) =
m exists (row => row forall (_ == 0))
hasZeroRow(diag3) 上面代码遍历diag3变量,如果diag3中某个子List的值全部为0,则结果为true。运行结果如下
![]()
4、/:, :\方法,折叠List
所谓的折叠List即对List中的元素进行汇总。比如说如果有一个函数sum(List(a, b, c))接收一个List参数,然后将该List中各元素的和进行累加,最终得到一个和,这个过程就可以称为对List的折叠。
Scala中提供了两个方法实现折叠功能
(1)/:方法,左折叠
对于左折叠,完整的调用形式是(z /: xs) (op),包含三个部分,其中z是一个初始值,xs是一个List对象,op是一个二元操作表达式。最终结果是将表达式op从z开始,依次从左到右的遍历xs中的每个元素。
(z /: List(a, b, c)) (op) 等价于 op(op(op(z, a), b), c) 用图表示的话,如下所示,

下面举个例子,
val words = List("the", "quick", "brown", "fox")
("" /: words) (_ + " " + _) 运行结果如下,最终返回一个字符串

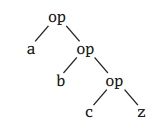
(2):\方法,右折叠
右折叠与左折叠功能类似,只不过是从右往左遍历List中的元素。
(List(a, b, c) :\ z) (op) 等价于 op(a, op(b, op(c, z))) 用图表示,
最后,用左折叠定义一个求数组和的方法,
def sum(xs: List[Int]): Int =
(0 /: xs) (_ + _)
sum(List(1, 2, 3)) 运行结果如下,

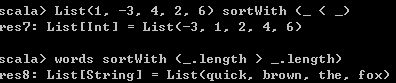
5、sortWith方法,排序List中的元素
xs sortWith before表达式中,xs是一个List对象,before是一个可用比较两个元素值的函数表达式。这个表达式的含义是,对xs中的元素进行排序,根据before方法来确定xs中哪个元素在前,哪个元素在后。
List(1, -3, 4, 2, 6) sortWith (_ < _)
words sortWith (_.length > _.length) 运行结果如下,
八、List对象上的方法
1、List.apply方法,使用传入的元素生成List对象
根据给定元素生成一个新的List对象。
List.apply(1, 2, 3) 结果,
![]()
2、List.range方法,生成包含范围内值的List
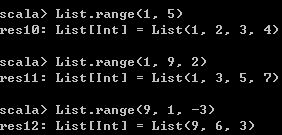
给定一个范围,根据起始值或者阶跃单位量生成一个List对象,
List.range(1, 5) // 从1到5
List.range(1, 9, 2) // 从1到9,每隔2生成一个元素
List.range(9, 1, -3) // 从9到1,每个-3生成一个元素 运行结果如下,
3、List.fill方法,根据给定元素和个数生成List
示例,
List.fill(5)('a') // 生成一个List对象,其中的元素为5个a字符
List.fill(3)("hello") // 生成一个List对象,其中元素为3个hello字符串
List.fill(2, 3)('b') // 也可以生成多维List,这里展示一个二维 运行结果如下,

4、List.tabulate方法,根据给定维度动态生成List元素值
该方法与List.fill有点类似,也是传入两个参数列表,第一个仍然是维度及长度,第二个参数列表中传入一个函数表达式而不是List.fill中那样传入一个固定值。这样,List.tabulate方法中的元素值就是动态变化的,由第二个参数列表中的表达式计算得到,改表达式的输入参数为当前元素的下标值。
val xs = List.tabulate(5)(n => "xs" + n) // 在每个下标前拼接一个xs
val squares = List.tabulate(5)(n => n * n) // 每个元素取其下标的平方值
val multiplication = List.tabulate(5, 5)(_ * _) // 每个元素取其纵横下标的乘积 运行结果如下,

5、List.concat方法,拼接多个List
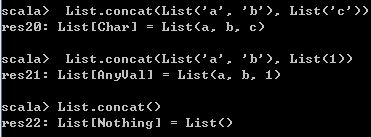
将多个List对象中的元素拼接到一起,可以拼接元素类型不同的List对象,形成一个新的List对象。类似于前面的flatten方法。
List.concat(List('a', 'b'), List('c'))
List.concat(List('a', 'b'), List(1))
List.concat() 运行结果如下,
九、zipped方法,处理多个List对象
通过前面介绍的zip方法,可以将两个List对象组合到一起,形成元素为pairs对的新List对象。Scala中还提供了一个zipped方法,在该方法之后就可以同时处理两个List对象中的元素了。
(List(10, 20), List(3, 4, 5)).zipped.map(_ * _) 运行结果如下,map方法中的两个_分别表示第一个和第二个List对象中对应位置上的元素。
![]()
zipped方法后,还可以使用forall或者exists方法,如下所示
(List("abc", "de"), List(3, 2)).zipped.forall(_.length == _)
(List("abc", "de"), List(3, 2)).zipped.exists(_.length != _) 运行结果如下,

这里需要注意的是zipped方法,只取较短那个List的长度,超过该长度的长List中的元素会被丢弃。