RFBnet论文笔记
作者认为,当前二阶段网络获得较好的准确率,然而因为特征来源于更深层的网络的庞大计算成本,所以速度较慢;一阶段网络为了加速检测而没有使用目标候选区域过程,因而牺牲了准确率,对于获得了可以与顶尖的二阶段网络准确率媲美的DSSD和RetinaNet,它们的表现提升来源于限制了效率的极深网络ResNet-101。
因此提出,建立一个快且强力的检测器,应该对轻量级网络加上人为设计的部分而不是顽固地加深模型。另一方面,一些神经学研究表明在人类视觉皮质中,population Receptive Field(pRF)的规模在视网膜定位图中是随着离心率地增加而增加的。它有助于彰显靠近中心区域的重要性并提升小空间位移带来的不灵敏度(这一块不懂,图片如下)。而一些浅层的descriptor利用这一机制在matching image patches方面也取得了较好的效果。
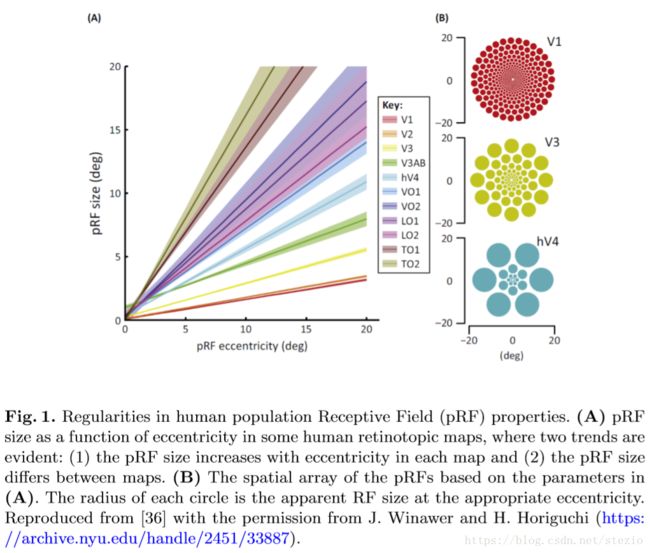
作者给出图片说明,pRF规模随着离心率增加,并且不同图谱的pRF大小规模也不一样。key指视觉皮质中的区域。
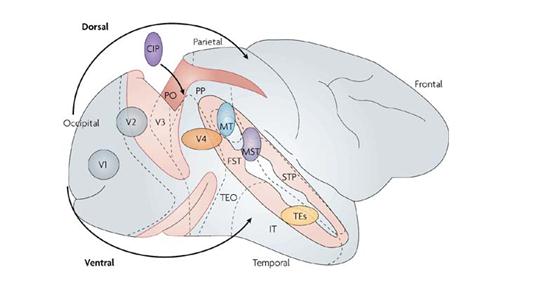
B中的spatial array基于图A参数的设置。每个圆形的半径是合适离心率下的RF的大小。
作者受人类视觉系统RF结构的启发,提出了Receptive Field Block (RFB), 以加强轻量级CNN模型学习到的深层特征,以创造快而精准的检测器。特别地,RFB根据不同大小规模的RFs对应的不同大小的kernels采用多分支池化层,利用扩大卷积层以控制离心率,并reshape生成最终的特征表达(如下图)。随后在SSD顶层组装RFB模块,另外,RFB模块是通用的,对网络结构带来很少的限制。

作者主要工作概括如下:
1.提出RFB模块进行人类视觉系统的大小和离心率的模拟,旨在增强轻量级CNN网络的深层特征。
2.将SSD的顶端卷积层换为基于RFB Net的检测器,在控制计算损失的情况下提升明显。
3.在VOC和COCO数据集上获得了实时处理速度,并通过将其连接到MobileNet证明其通用能力。
作者在介绍receptive field相关工作时,给出了一下对比:
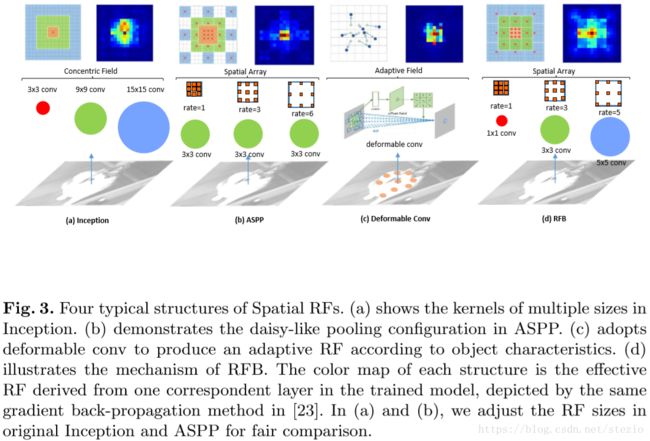
对于deformable conv介绍见:https://www.jianshu.com/p/206e7b0cb433
RFB模块包括两个部分:
1.以不同大小的核的多分支卷积层,与Inception类似,用来模拟不同规模的pRF。
2.扩大的池化或卷积层,用来重建人类视觉系统中pRF大小与离心率的关系。
RFB结构如下:

文中主要介绍的是RFB,RFB-s被用来模仿浅层视网膜图中的较小的pRFs,在更多分支上使用更小的kernels。5*5的卷积被2个3*3代替。
多分支卷积层:
作者认为根据RF在CNN中的定义,采用不同大小的核应该比相同大小的核效果更好。作者采用Inception系列最新的改动,即首先在每个branch后面加上bottleneck结构,即减少channel的1*1卷积层和n*n的卷积层。其次,用两个3*3的卷积层来代替5*5卷积层以减少参数及加深非线性层。同理采用1*n加上n*1卷积来取代原始的n*n卷积层。最后运用ResNet中的shortcut结构。
膨胀池化或卷积层:
这一概念首先在Deeplab中介绍,被命名为astrous卷积层。这一结构的基本目的是在不增加参数的情况下提取更高分辨率的特征信息。这一个设计在语义分割和目标检测中都取得了不错的效果。
作者利用膨胀池化层来模拟pRF在人类视觉皮质中离心率的效果。在每个branch,拥有特定大小kernel的卷积层之后跟着相应的dilation 的池化或卷积层。kernel size和dilation与人类视觉皮质中的pRF的大小和离心率有着相似的正函数关系。最终,所有分支的feature map被连接,整合进一个空间池化或者卷积数组。
RFB Net Detection Architecture:
RFB-Net300结构图如下:

作者采用SSD作为主架构。SSD结构如下:

而在原始的SSD上,基础网络结构后面跟着一连串瀑布状的卷积层以产生在空间分辨率上递减,感受野递增的特征图。作者保留了与SSD相同的瀑布结构,但是将在大分辨率特征图上的卷积层换成了RFB模块。RFB模块作为模拟离心率影响的雏形,随后考虑到pRF的大小和离心率的比例在不同的视觉图谱中比例不同,作者提出RFB-s来模拟人类视网膜中浅层pRFs并放到conv4_3卷积层之后。最后几层卷积层保留下来因为feature map太小而不能再用5*5的kernel进行处理。
Training Settings
训练方法在沿用SSD训练策略的前提下(包括data augmentation和hard negative mining,scale,宽高比,loss函数等等)微调学习率。
SSD训练方法https://www.cnblogs.com/xuanyuyt/p/7447111.html
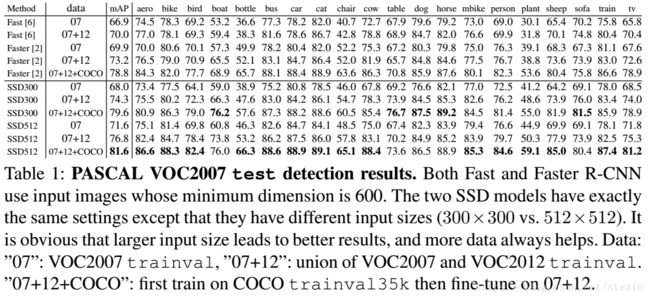
在Pascal VOC 2007数据集上取得结果如下:

RFB Net300,RFB Net512分别与SSD300*,SSD512*对应,300和512是输入图片的分辨率。而SSD300*和SSD512*是作者进行数据扩充(增加缩小后的图片产生更多的样例)后在相同环境下重新实验的结果。而原先SSD的实验结果如下:
对于RFB模块中每个结构作者做了逐个分析如下表:
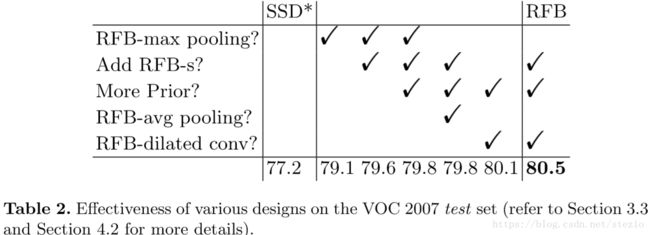
作者将RFB模块与其他结构比较如下:
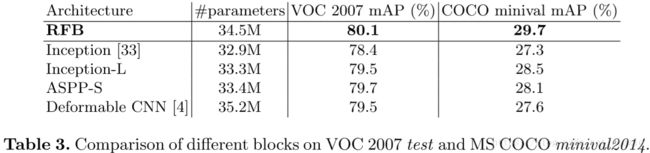
Inception-L和ASPP-S分别是对应模型在与RFB模型相同size的RF配置下的产物,所有检测结果由独立安装在检测器顶层得出。
coco数据集上结果如下:
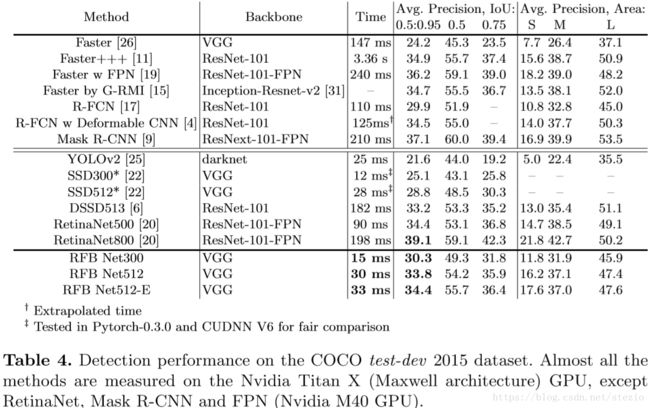
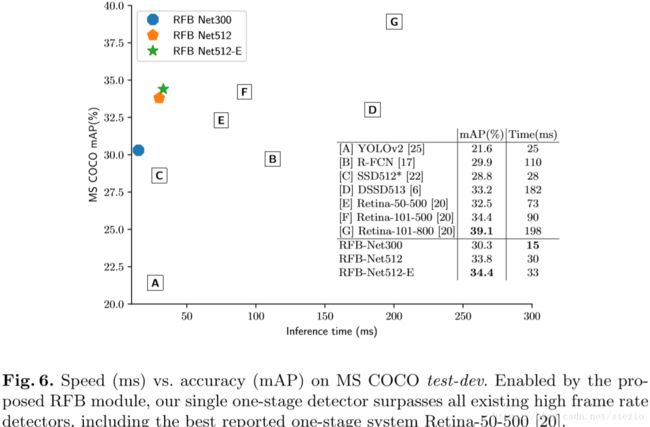
RFB Net和其他模型比较:
作者最后为了验证通用性,给出在mobilenet上的测试结果:
