02. ARM编程模型 & 汇编指令
1. ARM的基本设定
1)ARM数据类型
A. 基本数据类型
① Byte:字节,8位
② HalfWord:半字,16位(半字必须与2字节边界对齐)
③ Word:字,32位(字必须与4字节边界对齐)
④ DoubleWord(Cortex-A支持):双字,64位(双字必须与8字节对齐)

说明:关于地址对齐
ARMv6版本前的ARM处理器必须是地址对齐的,需要地址对齐的原因一般如下:
A. 某些体系结构的CPU在访问未对齐的数据时会发生异常或产生不可预知的后果。
B. 有些CPU支持非对齐的数据访问,但会严重影响存取效率。
如果发生非对齐访问,可能有如下结果:
A. 非对齐的指令预取操作
当执行ARM指令时,如果PC的值非对齐(低2位不是0),要么指令执行结果不可预知,要么地址值的低2位被忽略。
当执行Thumb指令时,如果PC的值非半字对齐(最低位不是0),要么指令执行结果不可预知,要么地址值的最低位被忽略。
B. 非对齐的数据访问操作
对于Load/Store操作,如果是非对齐的数据访问操作,系统定义了下面三种可能的结果:
① 执行结果不可预知
② 忽略字单元地址的低2位,忽略半字单元地址的最低位。即访问地址为(address AND 0xFFFFFFFC)的字单元,或访问(addreee AND 0xFFFFFFFE)的半字单元
③ 忽略字单元地址的低2位,忽略半字单元地址的最低位。但这种忽略由存储系统实现,传递给存储系统时仍原封不动。
说明:
具体行为可通过CP15协处理器配置
B. 浮点数据类型
A. ARM硬件指令集中未定义浮点数据类型
B. 解决方法
① 在协处理器指令空间定义浮点指令,通过未定义指令异常来进行软件模拟;部分浮点运算也可由浮点运算协处理器FPA10以硬件方式完成。
② ARM公司提供了以
C语音编写的浮点库
作为ARM浮点指令集的替代方法。这种方法与软件仿真相比即快又紧凑,因为他避免了中断、译码和浮点指令仿真。
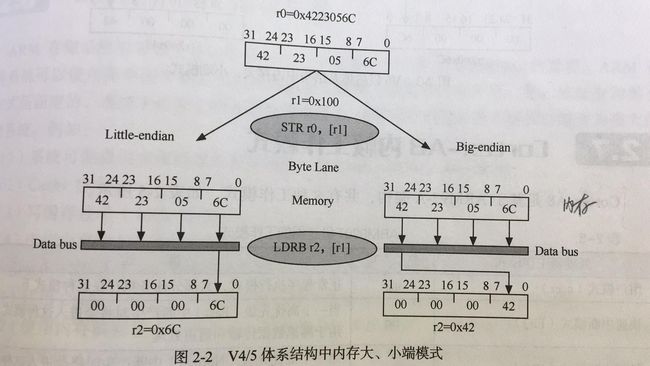
C. 存储器大小端
ARM同时支持大端模式(Big-endian)和小端模式(Little-endian),默认使用小端模式。

特别注意1:大小端模式问题只存在于多字节整型数据中
特别注意2:数据和代码在存储器中的存储格式必须和处理器采用的端格式一致
补充:上图中给出的是ARM v6之后的大小端模式,在ARM v4/5体系结构中,str 指令存储到内存中的多字节整型均采用小端模式,在ldr取出时才根据配置转换为大端或小端模式。使用CPSR的E位 + CP15_c1可以控制load/store endian,具体设置方式可参考《ARM Architecture Reference Manual》A2.7 Endian support(P72)
2)支持的指令集
A. ARM指令集(32 bit)
效率高,但代码密度低
B. Thumb指令集(16 bit)
代码密度高,但某些操作(e.g. 异常处理)必须切换到ARM模式运行。所以代码需要适时切换指令集。
ARM & Thumb模式切换是有开销的,而且二者的编译方式也不一样,这就增加了软件开发管理的负担。
C. Thumb2指令集(16 & 32big)
随ARM v7架构推出,在Thumb中加入部分32 bit指令,首次实现
16 bit & 32 bit指令并存,避免了指令集的切换
。目前主要应用在Cortex-M系列处理器中(e.g. Cortex-M3就只支持Thumb2指令集)。
当然,
使用Thumb2指令集也意味着不向后兼容
。
D. Java bytecode
Jazalle cores支持Java字节码
2. Cortex-A8编程模型
1)处理器工作模式
|
处理器工作模式
|
简写
|
描述
|
|
用户模式(User)
|
usr
|
正常程序执行模式,大部分任务执行在这个模式(用户
程序均运行在usr模式)
|
|
快速中断模式(FIQ)
|
fiq
|
高优先级(fast)中断产生时会进入这种模式,一般用于
高速数据传输和通道处理
|
|
中断模式(IRQ)
|
irq
|
低优先级(normal)中断产生时会进入这种模式,一般
用于通常中断处理
|
|
特权模式(Supervisor)
|
svc
|
当复位或软中断指令执行时会进入这种模式,是一种供
操作系统使用的保护模式(Uboot & Linux内核运行在svc模式)
|
|
数据访问中止模式(Abort)
|
abt
|
当存取异常时会进入这种模式,用于虚拟存储或存储保护
|
|
未定义指令中止模式(Undefined)
|
und
|
当执行未定义指令时进入这种模式,有时用于通过软件
仿真协处理器硬件的工作方式
|
|
系统模式(System)
|
sys
|
使用和User模式相同寄存器集的模式,用于运行特权级
操作系统任务
|
|
监控模式(Monitor)
|
mon
|
可以在安全模式与非安全模式之间进行转换
|
说明1:CPU为什么要设计多种工作模式?
① CPU是硬件,OS是软件。软件的设计要依赖硬件的特性,硬件的设计要考虑软件的需求,以便于实现软件特性。
② 操作系统有安全级别要求,因此CPU设计多种模式是为了方便操作系统的多种安全等级需要。
说明2:除用户模式外的其他7 种处理器模式称为
特权模式(Privilege Modes)
,在特权模式下程序
可以访问所有系统资源
,也可以
任意地进行处理器模式切换
。
说明3:FIQ、IRQ、Supervisor、Abort、Undefined 五种模式又被称为
异常模式
。
说明4:
处理器模式可以通过软件控制进行切换,也可以通过外部中断或异常导致切换
。
说明5:对user模式的限制
① 只能通过产生异常(SWI异常)切换到其他模式(此处指主动要求切换模式)
② memory system和协处理器可以限制user mode对memory和协处理器的访问
不同模式的关键:操作权限与访问资源的不同!!!
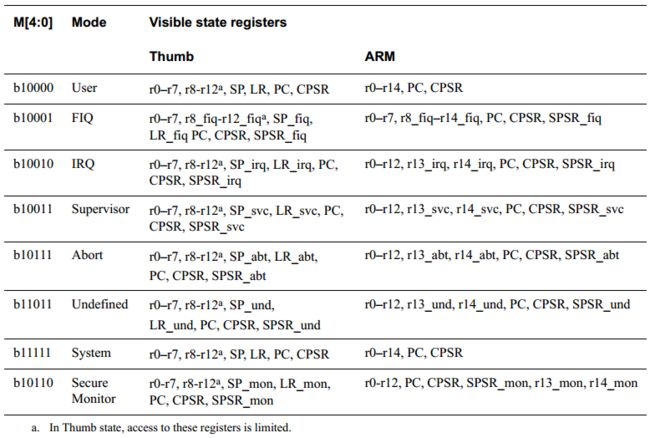
2)寄存器组织

说明1:System模式使用和User模式相同的寄存器集,但System是特权模式
说明2:Cortex-A8处理器共有40个32位寄存器,其中
① 32个通用寄存器
② 7个状态寄存器:1个CPSR(Current Program Status Register,当前程序状态寄存器),6个SPSR(Saved Program Status Register,备份程序状态寄存器)。当特定异常/中断发生时,对应模式的SPSR负责存放CPSR的内容;当异常处理程序返回时,再将其内容恢复到CPSR中。
③ 1个PC(Program Counter,程序计数器)
说明3:r13和r14的通常用法
r13:用作栈指针SP(Stack Pointer),指向不同模式的栈区。
异常处理程序负责初始化自己的r13,使其指向该异常模式专用的栈区
。
在异常处理程序的入口会将用到的其他寄存器的值保存在栈区,返回时重新将这些值加载到寄存器中
。通过这种保护程序现场的方法,通常不会破坏被中断的程序现场。
future point:根据《ARM architecture reference manual》A2.4 General-purpose registers,ARM v6之后推荐新的sp使用方法:
并非初始化所有banked sp register,而是预先规划好使用的栈,然后调用
SRS指令
使用栈(即
可以规定不同的exception使用指定的栈
)
r14:用作链接寄存器LR(Link Register),该寄存器在ARM体系结构中有下面两种特殊用途:
①
每一种处理器模式用自己的r14存放当前子程序的返回地址
。当通过
BL
或
BLX
指令调用子程序时,r14被设置成该子程序的返回地址。从子程序返回时,一般有如下两种场景:
a. 仅返回子程序调用点(BX可附带切换指令集)
MOV PC, LR
---------------
BX LR
b. 在子程序入口使用下面的指令将LR保存到栈中
STMFD SP!, {,LR}
在程序返回时使用相应的指令返回
LDMFD SP!, {,PC}
②
当异常/中断发生时,该异常模式的r14 被设置成该异常模式的返回地址
。
特别注意:
某些模式的r14 值可能与返回地址有一个常数的偏移量
(这点将在中断处理部分说明)。
个人:产生这个偏移量的根源是异常发生的时机!!!
补充:嵌套中断(nested exception)对LR的影响
① 当允许嵌套中断时,如果在IRQ handler中开中断,并且正好有中断发生。那么之前LR_irq中保存的中断返回地址会被覆盖
② 解决方案
进入IRQ handler后切换到另一个模式(手册推荐System mode),然后再开中断
说明4:程序状态寄存器详解

A. 条件标志位
N(Negative)、Z(Zero)、C(Carry)、V(overFlow)为条件标志位,这些标志位会
根据程序中的算术指令或逻辑指令的执行结果进行修改
,而且这些标志位可
作为指令条件执行的依据
。
① N位:设置为当前指令运行结果的bit[31]的值。当有符号数补码运算时,N=1 表示结果为负数,N=0 表示结果为正数或零。
② Z位:Z=1 表示运算结果为0,Z=1 表示运算结果不为零。
③ C位:设置方法有如下四种
a. 在加法指令中(包括比较指令CMN),当结果产生了进位,则C = 1,表示无符号数运算发生上溢出;其他情况C = 0。
b. 在减法指令中(包括比较指令CMP),当运算中发生借位,即无符号数运算发生下溢出,则C = 0;其他情况C = 1。
c. 对于在操作数中包括移位操作的运算指令(非加/减指令),C被设置成被移位寄存器最后移出去的位。
d. 其他非加/减运算指令,C的值通常不受影响。
④V位:设置方法有如下两种
a. 对于加/减运算指令,当操作数和运算结果都是以
二进制补码表示的带符号数
,且运算结果超出了有符号数运算的范围时发生溢出。V=1 表示有符号数运算溢出。
b. 对于非加/减运算指令,通常不改变V 的值。
B. 控制位
① 中断
禁止
位
I=1,IRQ被禁止
F=1,FIQ被禁止
② 处理器状态控制位
T=0,处理器处于ARM状态(执行32位ARM指令)
T=1,处理器处于Thumb状态(执行16位Thumb指令)
注1:T位仅在T系列ARM处理器上才有效,在非T系列中,T始终被置为0
注2:不能通过直接修改CPSR的T位来改变处理器的状态,因为直接修改CPSR的T位的结果不可预知,必须通过BX、BLX指令来修改。
③模式控制位
3. GNU ARM汇编语法格式
GNU ARM汇编程序中,每行的语法格式如下:
[
说明1:如果语句太长,可以将一条语句分几行来书写,在行末用\ 表示换行(即下一行与本行为同一句),\ 后不能有任何字符,包括空格和制表符
说明2:同一行中,ARM指令、伪指令、伪操作、寄存器名称等要么大写、要么小写,不可以大小写混合
各字段详解如下:
lable:为标号,可选。
① 可以使用字母、数字、下划线,除了
局部标号
外,必须以字母或下划线开头。
② 标号必须以:(冒号)结尾
③ GNU ARM中对标号的大小写敏感
instruction | directive | pseudo-instruction:可选项,为指令、伪指令、伪操作三者之一。
instruction:ARM
汇编指令
,如mov r0, r1
pseudo-instruction:ARM
伪指令
,伪指令不是真正的ARM指令,
汇编阶段汇编器会将其转化成一条或多条ARM指令
,如ldr r0, =label
directive:GNU ARM
伪操作
,伪操作只在汇编阶段起作用,其
不会被转换成ARM指令
,只是用来控制汇编、链接器的动作。
@comment:可选项,GNU ARM 汇编语言注释语句,@为注释标识符
4. ARM指令的条件执行
ARM指令32位指令码的高4位为条件域

4位条件域有16种条件码,每个条件码根据CPSR中的条件标志位N、Z、C、V 来条件执行,具体条件码如下图:

说明1:无符号数使用higher/lower/same;有符号数使用greater/less/equal
说明2:用条件执行代替分支跳转可以大大提高程序效率,因为每次跳转都会清空流水线并重新装载指令。
5. ARM指令集概要
参考资料:
1)ARM指令集分类
① 数据处理类指令:完成CPU内部的计算(仅涉及寄存器)
② Load/Store指令:完成CPU与
内存/IO外设
之间的数据传输
③ 跳转指令:完成程序的跳转
④ 程序状态寄存器处理指令:完成CPSR的管理
⑤ 协处理器指令:完成CPU扩展功能的实现·
⑥ 异常产生指令:用户程序触发异常
说明:ARM汇编的寻址方式根据指令类型不同进行分类,即使是相同的寻址方式其编码方式也会有所不同(e.g. 允许的移位操作/立即数移位值的宽度),具体可查阅《ARM Architecture Reference Manual》A5. ARM Addressing Modes(P455)
2)分支跳转指令
A. B/BL/BX/BLX是一种
相对跳转(即地址无关操作)
,以PC寄存器的值作为跳转指令的基地址值。在指令执行过程中,会
从跳转的目标地址中减去跳转基地址,生成字节偏移量
。
B. B/BL/BX/BLX 的跳转范围为±32MB
解释:在B/BL/BX/BLX 指令编码中有24位有符号数用于存储跳转地址,照理24位只能寻址16MB,但ARM指令为32位定长,按4 字节对齐后两位为0,所以24位可以表示26位的范围,也即±32MB
C. BL/BLX 会将下一条指令的地址拷贝到r14寄存器中
小结:地址无关跳转更灵活,但跳转范围有限制;地址相关跳转可实现4GB跳转,但要求运行地址和链接地址一致。
补充:对于non-leaf 函数(非叶子函数),LR必须压栈保存

3)数据处理指令
A. 基本语法格式和寻址方式
关键是
第二操作数(shifter_operand)的多种寻址方式

关于立即数的说明:每个立即数由一个8位的常数循环右移偶数位得到,其中循环右移的位数由4 位二进制数的两倍表示(即2、4、6 ... 30)。
B. MOVS/MVNS 如何影响CPSR?
① 如果指令中的目标寄存器不是PC,根据指令传送的数值设置CPSR中的N位和Z位,并根据移位器的进位设置CPSR的C位;标志位V 和其他位不受影响。
② 如果指令中的目标寄存器是PC,则将当前处理器模式对应的SPSR的值复制到CPSR中,对于用户模式和系统模式,由于没有相应的SPSR,指令执行的结果不可预知。
指令MOVS PC, LR 可以实现从某些异常/中断中返回。
注:其余数据操作指令(ADD、ADC等等)的S位均涉及上述用法(但比较和测试指令默认影响CPSR中的标志位),关键就是当目标寄存器位PC时,可实现SPSR到CPSR的拷贝。
4)加载存储指令
A. 3 种Load/Store指令
① 单寄存器Load/Store指令(Single Register)
在ARM寄存器和存储器之间提供灵活的单数据项传送,数据项可以是字节、16位半字或32位字
② 多寄存器Load/Store内存访问指令
这些指令的灵活性比单寄存器传送指令差(只能传递32位字),但可以使大量的数据有效传递。一般用于进程的进入和退出、保存和恢复工作寄存器以及拷贝存储器中的一块数据。
③ 单寄存器交换指令(Single Register Swap)
这些指令允许寄存器和存储器中的数值进行交换,在一条指令中完成Load/Store操作,一般用于实现信号量(Semaphores)。
B. LDR Rd, lable
label 为程序标号,lable必须在当前指令
±4KB范围内
注意和伪指令 LDR Rd, =label 区别开来!!!
特别说明:ldr 指令、ldr 伪指令及adr 伪指令辨析
代码如下:

反汇编内容如下:

首先要明确的是,
标号在汇编中表示一个地址(是一个32位无符号常数),所以标号也称为符号地址。特注特注!!! 标号表示的就是链接地址!!!
① ldr r0, _start:向r0中装载的是_start标号表达的地址中的内容,因为ldr 指令本质上用于将存储器中的值加载到寄存器中。
②adr r0, _start:adr伪指令将标签所表示的地址加载到寄存器中,执行时将基于PC相对偏移的地址值读取到寄存器中。因为是基于PC的,所以ADR读取到的地址值为位置无关地址。
③ldr r0, =_start:是伪指令,通过文本池向r0中装载的是_start表示的地址值,需要特别说明的是,
此处装载的是链接地址
(即0x2000800c)。这也说明对于这种
地址相关操作
,在哪里链接就要在哪里执行,否则会出错。比如即使将这部分代码加载到内存0x20000000处执行,ldr r0, =_start向r0中装载的仍为0x2000800c。
补充:经我在Keil上仿真实验,上述结论是正确滴~~~
C. 有符号的字节/半字数据传送指令仅适用于Load操作
有符号的字节/半字数据传送指令仅适用于Load操作,即只有LDRSB和LDRSH。因为
只有读入字节或半字到寄存器时涉及零扩展还是符号扩展(因为寄存器都是32位)
,而写入内存时不存在这一问题。
D. 单寄存器Load/Store寻址方式

说明:此处的移位值只能是立即数形式,这也就是我前面说的,即使是相同的shift operand产生类型,编码方式也可能不同。
E. 多寄存器内存字数据传送指令(LDM/STM)
① 多寄存器传输时只能传输字,而不能是字节或半字
② 传输数据的对应关系:
编号低的寄存器对应于内存中的低地址单元,编号高的寄存器对应于内存中的高地址单元
。
③ ldmfd sp!, {r0-r7, pc}
^
若LDM指令在寄存器列表中包含PC且使用^ 后缀,那么除了正常的多寄存器传送外,还可将SPSR复制到CPSR,从而
实现从异常处理中返回
。
^ 后缀不允许在用户模式和系统下使用,因为这两个模式没有SPSR寄存器。
补充:如果使用^ 后缀但寄存器列表中不包含PC,则表示加载/存储的是用户模式寄存器,而不是当前模式寄存器。(还没见过实例~~)
④ 注意多寄存器数据传送指令中寻址方式的配套使用(块数据传输、堆栈操作)


在操作堆栈时要尽量使用配对的堆栈操作地址模式,这样只要主要使用相同的栈类型即可。
F. 交换指令(SWP/SWPB)
交换指令(SWP/SWPB)是Load/Store指令的一种特殊形式,该指令将一个存储器单元内容与指定的寄存器内容相交换。交换指令为进程间同步提供了一种方便的解决途径,该指令
生产一对原子Load/Store操作,该操作发生在一个连续的总线操作中
,在操作期间阻止其他任何指令对该存储单元的读写。
future point:ARM v7版本中不推荐使用swap指令实现信号量,而是推荐使用
互斥的LDR/STR指令
(load and store register exclusive),即LDREX/STREX指令。这2条指令在操作过程中不会锁住所有系统资源。
5)程序状态寄存器访问指令
A. 状态寄存器的修改原则
① 不修改和使用状态寄存器中未定义的位
②
通常要遵循 读取---> 修改---> 写回
的原则,这样可以保证不影响其他未修改的位
B. MRS的使用场景
① 当需要保存或修改当前模式下CPSR或SPSR的内容时,首先必须将这些内容传递到通用寄存器中,对选择的位进行修改,然后将数据写回到状态寄存器。
②
当异常中断允许嵌套时
,需要在进入异常处理程序之后,嵌套中断发生之前保存当前处理器模式的SPSR。这时需要先通过MRS指令读出SPSR的值,再用其他指令(如压栈指令)将SPSR的值保存起来。
③ 在进程切换时也需要保存当前程序状态寄存器的值。
C. MSR指令总结
① 只有在
特权模式下
才能修改状态寄存器
② 语法格式:

说明1:可以将通用寄存器或立即数(
此处立即数为8位,范围从0x00到0xff
)传送到程序状态寄存器
说明2:有C(控制)、X(扩展)、S(状态)、F(标志),使用时可以是其中一个,也可以是他们的组合。

C(控制):bit[0] ~ bit[7]
X(扩展):bit[8] ~ bit[15]
S(状态):bit[16] ~ bit[23]
F(标志):bit[24] ~ bit[31]
6)异常产生指令
A. SWI指令功能
SWI 指令用于产生软中断,实现从用户模式切换到管理模式,CPSR保存到管理模式的SPSR,执行转移到SWI异常向量;在其他模式下使用SWI指令,处理器同样切换到管理模式。
B. SWI指令语法格式
ARM处理器对指令中的24位立即数不进行处理,其作用是提供给操作系统,从而判断用户程序请求的服务类型
。
C. SWI指令参数传递方式
① 指令中24位立即数指定了用户请求的类型,中断服务程序的参数通过寄存器传递
MOV R0,#34 @设置功能号为34
SWI 12 @产生软中断,中断号为12
② 指令中的24位立即数被忽略,用户请求的服务类型由寄存器r0的值决定,参数通过其他寄存器传递
MOV R0,#12 @设置12号软中断
MOV R1,#34 @设置子功能号为34
SWI 0
D. SWI Handler
① 确定引起软中断的SWI 指令是ARM指令还是Thumb指令,这可以通过对SPSR的访问得到
② 确定该SWI指定的地址,这可以通过访问LR寄存器得到
③ 读出指令,分解立即数
7)协处理器指令
A. ARM协处理器概述
①
ARM协处理器具有自己专门的寄存器组
,他们的状态由控制ARM状态指令的镜像指令来控制。
② 程序的
控制流指令由ARM处理器来处理
,
所有协处理器指令只能同数据处理和数据传送有关
。按照RISC的Load/Store体系原则,数据的处理和传送指令是被严格分开的,因此他们有不同的指令格式。
③ ARM处理器支持最多16个协处理器,在程序执行过程中,
每个协处理器忽略ARM和其他协处理器的指令
。
当一个协处理器硬件不能执行属于他的协处理器指令时,将产生一个未定义指令异常中断
,在该异常中断处理过程中,
可以通过软件仿真该硬件操作
。假设一个系统中不包含向量浮点运算器,则可以选择浮点运算软件包来支持向量浮点运算。

B. ARM协处理器指令分类
① 协处理器
数据操作
指令
说明:协处理器数据操作完全在协处理器内部操作,他完成协处理器寄存器的状态改变。如浮点运算,在浮点协处理器中将两个寄存器相加,结果放在第三个寄存器中。
示例:CDP
② 协处理器
数据传送
指令
说明:这类指令可实现从存储器读取数据装入协处理器寄存器,或将协处理器寄存器的数据装入存储器。因为协处理器可以支持自己的数据类型,所以每个寄存器传送的字数与协处理器有关。因此存储器地址由ARM处理器产生,但传送的字节由协处理器控制。
示例:LDC、STC
③协处理器
寄存器传送
指令(最常用)
说明:这类指令可实现
ARM处理器的寄存器
与
协处理器的寄存器
之间的数据交换
示例:MCR、MRC
C.MCR/MRC指令格式
MCR/MRC{} , , , , {, }
说明:具体的使用实例可参考对应的ARM核手册
6. ARM汇编伪指令
1)关于伪指令
A.
伪指令是为汇编器服务的,不同的汇编器有不同的伪指令
B. 伪指令分类
① GNU 汇编器支持的ARM 伪指令
② GNU 汇编器支持的平台无关伪指令(也叫伪操作)
2)GNU汇编器支持的ARM伪指令
A. 概述
ARM伪指令在汇编阶段会被编译成ARM或者Thumb 指令(或指令序列)
B. ADR 伪指令
语法:ADR
功能:ADR 为
小范围地址读取
伪指令,ADR伪指令将
基于PC 的相对偏移地址
读取到寄存器中。当地址值字节对齐时,取值范围为-255~255;当地址值字对齐时,取值范围为-1020~1020;当地址值16字节对齐(即双字对齐)时,取值范围更大。
因为ADR伪指令中的地址是基于PC的,所以
ADR读取到的地址为位置无关地址(取到的地址是基于运行地址的)
。当ADR伪指令中的地址基于PC时,该地址与ADR伪指令必须在同一代码段中。
使用说明:
ADR被汇编器汇编为一条指令
,汇编器通常使用ADD 或SUB 指令来实现该伪指令的地址装在功能;
如果不能用一条指令来实现ADR 伪指令的功能,汇编器将报告错误终止汇编
。
示例:
start:MOV R0,#10
ADR R4,start @本ADR伪指令将被汇编为SUB R4,PC,#0xc
C. ADRL 伪指令
语法:ADRL
功能:ADRL为
中等范围
地址读取伪指令,ADRL也是将基于PC的相对偏移地址读到寄存器中。他比ADR伪指令读取的范围更大,当地址值字节对齐时,取值范围为-64KB~64KB;当地址值字对齐时,取值范围为-256KB~256KB;当地址值双字对齐时,取值范围更大。
使用说明:在实现上,
ADRL被汇编器汇编为两条指令
,即使一条指令可以完成该操作,汇编器也将产生两条指令,其中一条为多余指令。
如果汇编器不能再两条指令内完成操作,将报告错误终止汇编
。
D. LDR 伪指令
语法:LDR register, =expr @expr为32位常量表达式
功能:LDR伪指令用于装载一个
32位常数
或一个
地址
到寄存器,使用LDR伪指令装载地址是一种
位置相关
操作(
取到的地址是基于链接地址的
)。
使用说明:汇编器根据expr的取值情况做如下处理:
① 当expr 表示的地址值没有超过MOV或MVN指令的地址取值范围时,汇编器用一条MOV和MVN指令代替LDR伪指令
② 当expr 表示的地址值超过MOV或MVN指令的地址取值范围时,汇编器将常数放入数据缓存池,同时用一条基于PC的LDR装载指令读取该常数。
特别注意:缓存池所在地址与LDR伪指令处的PC值之间的偏移量是有限制的,ARM指令中为±4KB,Thumb指令中为0~1KB。
E. NOP伪指令
功能:NOP伪指令执行一条空操作,多用于延时。
使用说明:该指令一般被替换为MOV R0,R0
3)GNU汇编器支持的平台无关伪指令
A. 简介
① GNU 汇编器支持的平台无关伪指令
没有对应的机器码
,他是用于
告诉汇编程序如何进行汇编
的指令。他既不控制机器的操作,也不被汇编成机器代码,只能为汇编程序所识别并指导汇编如何进行。
② 此处的汇编伪指令的名称都以"
.
"开始,余下的是字母,通常是小写字母
B. 符号定义伪指令
① 全局标号定义伪指令 .global 和.globl(.globl 是为了兼容其他汇编器)
说明:.global 使得符号对链接器(ld)可见,变为整个工程可用的
全局变量
;由于将符号定义为全局变量,因此在整个工程范围内符号
必须唯一
。
语法:.global symbol
补充:.global 是定义一个全局标号,如果要声明一个外部符号,使用.extern label
② 局部标号定义伪指令 .local
说明:这个指令表示定义的符号名称作为一个局部的符号,这样他对外部就是不可见的,作用域在定义他的文件内(GNU汇编中标号默认具备局部属性)。
语法:.local symbol
③ 宏替换伪指令 .equ
说明:.equ 类似于C 语言中的宏定义,用于声明一个符号常量
关键:汇编器
不为.equ 声明的符号常量分配内存空间
,只是在汇编时将其替换(和C语言中不带参数宏定义相同)
语法:.equ symbol, expr
示例:.equ num, 0x40
mov r1,
#
num
@注意此处仍然需要井号,因为num是一个符号常量,本质上仍是常量
补充:.set 与.equ 语法、作用一样
C. 数据定义伪指令
注意:下面定义中的label是为方便程序员引用而设,即使没有也不影响内存单元的分配。(只是如果没有这个label,程序将很难访问分配的内存单元)
说明:数据定义伪指令一般用于为特定的数据
分配存储单元
,同时可完成已分配存储单元的初始化。
伪指令列表:
① label:
.byte
expr
功能:在存储器中分配
一个
字节,并用指定的数据对存储单元进行初始化
expr 范围:-128 ~ 255,也可以是字符
② label:
.short
expr
功能:在存储器中分配
两个
个字节,并用指定的数据对存储单元进行初始化
expr 范围:-32768 ~ 65535
③ label:
.word
expr @
.long
的功能与.word 相同
功能:在存储器中分配
四个
个字节,并用指定的数据对存储单元进行初始化
expr 范围:-2^31 ~ 2^32
④ label:
.quad
expr
功能:在存储器中分配
八个
个字节,并用指定的数据对存储单元进行初始化
expr 范围:-2^63 ~ 2^64
⑤ label:
.float
expr
功能:在存储器中分配
四个
字节,并用指定的浮点数据对存储单元进行初始化
expr 范围:4字节范围内的浮点数值
⑥ label: .space size, expr
label: .skip size, expr
功能:分配
一片连续的存储区域
并初始化为指定的值,如果后面的填充值省略则在后面填充为0。该伪指令类似于在C语言中定义数组。
示例:a: .space 8, 0x1 @相当于在C语言中定义char a[8],并将每个成员初始为为1
补充1:.zero size @分配size 个字节的数据空间,并用0 填充内存。
补充2:.fill
.fill repeat {,size} {,value}
repeat:重复填充的次数
size:每次填充的字节数,省略时默认为1 字节
value:对每次申请空间的填充值,省略时默认填充0
即每次分配repeat * size 个字节
示例:.fill 1024,2,0xffff
辨析:.space/.skip 都是以字节为单位分配内存,并可以初始化;而.fill 功能最强,可以指定每次分配的字节数;.zero 相当于.space/.skip 的简化版本,将申请的字节均初始化为0。
⑦ 定义字符串伪指令
.string
、
.ascii
、
.ascize
示例:lable: .string "str"
辨析:.ascii 伪操作定义的字符串需要自行添加结尾字符'\0'
⑧.rept count
功能:重复执行后面的指令,以.rept开始,以.endr结束
示例:
.rept 3
.long 0
.endr
上述指令相当于.long伪指令被执行3次
D. 汇编控制伪指令(.if、.else、.elseif.、.endif、.ifdef)
功能:汇编控制伪指令用于
控制汇编程序的执行流程
,类似C语言中的
条件编译
。
使用说明:if、.else、.elseif.、.endif 伪指令能根据条件的成立与否决定是否执行某个指令序列。
示例:
.if logical-expression
instructions
.elseif logical-expression
instructions
.else
instructions
.endif
可见此处的使用和C语言中的条件编译非常相似。
E. 宏定义伪指令(.macro、.endm、.exitm)
功能:.macro、.endm伪指令可以将一段代码定义为一个整体,称为宏指令。然后就可以在程序中通过宏指令多次调用该段代码,而.exitm 指令用来退出当前的宏指令。
说明1:宏操作可以使用一个或多个参数,当宏操作被展开时,这些参数被相应的值替换。
说明2:宏操作的使用方式和功能与子程序有些相似,子程序可以提供模块化的程序设计、节省存储空间并提高运行速度。但在使用子程序结构时需要保护现场,这就增加了系统的开销。因此在代码较短且需要传递的参数较多时,可以使用宏操作代替子程序。
语法:
.macro 宏名 参数列表 @伪操作.macro定义一个宏
; codes @宏体
.endm @.endm 表示宏结束
① 在宏定义的第一行应声明宏的原型(包括宏明和所需参数)
② 包含在.macro和.endm之间的称为宏体
③ 如果宏使用参数,那么在宏体中使用该参数时需要添加
前缀\
,
宏定义的参数还可以使用默认值
。
④ 在汇编程序中可以通过宏名来调用该指令序列,在源程序被汇编时,汇编器将宏调用展开,用宏定义的指令序列代替程序中的宏调用,并将实际参数传递给宏定义中的形式参数。
示例:
.macro SHIFTLEFT a, b
.if \b < 0
mov \a, \a, asr #-\b
.exitm
.endif
mov \a, \a, lsl #\b
.endm
F. 杂项操作伪指令
①
.align
功能:通过填充字节的方式使当前位置满足一定的
对齐
方式
语法:.align abs-expr
abs-expr:对齐表达式,此处表示的对齐方式为2 的abs-expr次幂,即align 2 表示4 字节对齐
②
.section
功能:用于定义一个段。
语法:.section sectionname @如 .section .text,但在实际使用中一般可省略.section
补充内容:.section 完整语法格式
.section section_name [, "flags"[, %type[,flag_specific_arguments]]]
用户可以通过.section 伪操作来自定义一个段,每一个段以段名开始,以下一个段名或者文件结尾结束。这些段都有缺省的标志(flags),链接器可以识别这些标志。ELF格式允许的段标志有:
a:可加载段
w:可写段
x:执行段
在定义段时,可以使用预定义段,.text、.data、.bss,他们将汇编系统预定义的段名编译到相应的代码段、数据段和bss段。需要注意的是,源程序中.bss 段应该在.text之前。
③
.data
功能:定义一个数据段
语法:.data subsectionname
④
.text
功能:定义一个代码段
语法:.text subsectionname
⑤
.include
功能:包含一个文件
语法:.include "s5pc100.h" @类似于C语言中的#include功能
⑥
.arm
功能:用于指定以下代码使用ARM指令集汇编,等价于 .code32
⑦
.thumb
功能:用于指定以下代码使用Thumb指令集汇编,等价于 .code16
⑧
.extern
功能:用于声明一个外部符号
语法:.extern symbol
⑨
.weak
功能:用于声明一个弱符号,即如果该符号没有定义,汇编时会被忽略而不会报错
语法:.weak symbol
⑩
.end
功能:代表汇编程序的结束,如果.end 后还有代码,不会被编译到执行文件中
语法:.end
7. ARM汇编语言程序结构
.section .data
初始化的数据
.section .bss
未初始化的数据
.section .text
.global
_start
_start:
汇编代码 @GNU汇编语言中注释以@开始
补充:当程序较长时,可以将其分割为多个代码段和数据段,多个段在程序编译链接时最终形成一个可执行的映像文件。
8. 过程调用标准AAPCS/ATPCS
1)概要
A. AAPCS:Procedure Call Standard for the ARM Architecture,
为了使不同编译器编译的程序可以相互调用
,必须为子程序间的调用制定一定的规则。
B. 纯汇编代码可以不遵循该标准,但只有遵循ATPCS标准才可以和编译器编译的C 语言代码相互调用(因为编译器编译的C 代码一定遵循ATPCS标准)。
C. 为了解决C和汇编相互调用,需要考虑3个方面:
① 规定
寄存器
使用
说明:硬件上并不区分寄存器的使用,但ATPCS标准对使用作了要求
② 规定
函数传参
方式(包括如何传递返回值)
③ 规定
栈
使用方法(满递减栈,FD)
2)寄存器使用规则

① 子程序间通过寄存器
R0、R1、R2、R3来传递参数
,如果参数多于4 个(
准确地说是传参需要使用的寄存器超过4个,比如传2 个double
),则
多出的部分用栈传递
,被调用的子程序在返回前无需恢复寄存器R0~R3的内容。
②
在子程序中,使用寄存器R4~R11来保存局部变量
。如果在子程序中用到R4~R11中的某些寄存器,子程序进入时必须保存这些寄存器的值,在返回前必须恢复这些寄存器的值;对于子程序中没有用到的寄存器则不必进行这些操作。(在Thumb中通常只能用R4~R7来保存局部变量)。
③ 寄存器
R12
用作子程序间的
栈帧寄存器
,记作ip,类似于X86下的EBP寄存器。
联系之前的内容,如果当前汇编函数是非叶子函数,lr 也必须在进入汇编函数时保存。
修正:R12并不是栈帧寄存器,而是内部过程调用寄存器;R11为栈帧寄存器。
R12用作过程调用时的临时寄存器(用于保存SP,在函数返回时使用该寄存器出栈),记作ip。在子程序间的连接代码段中常有这种使用规则。

参考资料:
http://blog.csdn.net/tianxiawuzhei/article/details/7422592
http://blog.csdn.net/songcdut/article/details/40654151
④ 寄存器R13用作
栈指针
,记作
sp
。子程序中不能将R13用作其他用途,R13的值在进入子程序和退出子程序时必须相等。
⑤ 寄存器R14用作
链接寄存器
,记作
lr
。用于保存子程序的返回地址,如果在子程序中保存了返回地址,R14可用作其他用途。
⑥ 寄存器R15用作
程序计数器
,记作
pc
。他不能用于其他用途。
⑦ CPSR标志位可被函数调用破坏
3)参数传递

4)栈的使用

9. 汇编语言和C语言混合编程
1)C调用汇编
设汇编中有程序段asm_add
asm_add:
add r0, r0, r1
mov pc, lr
C代码中:
声明:int asm_add(int, int);
调用:int sum = asm_add(a, b);
汇编代码中:
声明:
.global asm_add
@使该标号对整个工程可见
参数:r0 ==> a
r1 ==> b
返回值:用r0带回
2)汇编调用C
特别注意:在用汇编代码调用C函数之前一定要设置好相应模式的栈!!!
设C中有函数int c_add(int, int);
C代码中:
供汇编代码调用的函数不能用static修饰,即该函数要对整个工程可见
汇编代码中:
调用:bl c_add @如果使用位置相关操作就是 ldr pc, =c_add
参数:r0和r1
返回值:在r0中
缺点:这种方式下,C语言只能调用以函数形式存在的汇编语言,所以还需要一个.S文件;而内嵌汇编就不需要。
3)内嵌汇编
A. 使用场景
① 程序中使用饱和算出运算(Saturating Arithmetic),如SSAT16和USAT16指令
② 程序中需要对
协处理器
进行操作
③ 程序中需要对
程序状态寄存器
进行操作
B. 语法格式(GNU风格)

① C 内嵌汇编以关键字__asm__(注意是两个下划线)或asm 开始,下辖四个部分。各部分之间使用":"分开,第一部分是必须写的,后面三个部分可以省略,但":"不能省略。但如果没有破坏描述部分,该字段的":"必须省略。
② 汇编语句部分:
a. 汇编语句的集合,可以包含多条汇编语句,每条语句之间需要用转义换行符\n 隔开。
b. 无论汇编语句有多长,对C 语言都只是一条语句。
c. 汇编语句字符串内除了放置汇编指令,还可以放置标签、变量、循环和宏等,总之和直接写汇编文件一样。
d. 编译器不会检查汇编语句的内容是否合法,而是直接将其交给汇编器
③ 输出部分:在汇编中被修改的C 变量列表(ASM ---> C)
__asm__ __volatiole__ (
"asm code"
: "constraint"(variable)
);
a. constraint 定义了variable 的存储位置,constraint 可以是:
r:使用任何可用的通用寄存器
m:使用变量的内存地址
b. output 修饰符
+:可读可写
=:只写
&:该输出操作数不能使用输入部分使用过的寄存器,只能用+& 或=& 的方式使用
示例:

说明1:%0 为占位符,按序号就是输出时使用的参数
说明2:最后的"memory"用于指出本段汇编代码修改了内存
④ 输入部分:作为参数输入到汇编中的变量列表(C ---> ASM)
__asm__ __volatiole__ (
"asm code"
:
: "constraint"(variable/immediate)
);
constraint 定义了variable/immediate 的存储位置
r:使用任何可用的通用寄存器(变量和立即数都可以)
m:使用变量的内存地址(不能用立即数)
i:使用立即数(不能用变量)
注:当输入部分为立即数时,立即数前不用加#
示例:

⑤ 破坏描述部分:执行汇编指令会破坏的寄存器描述
⑥ volatile告诉编译器,不要对接下来的代码进行优化,如果想优化可以不加
⑦ 使用占位符

说明1:占位符的顺序:
序号的排列根据output部分和input部分参数出现的顺序确定
,上例中0 就代表变量old;1 就代表变量temp
说明2:使用占位符时在序号前加% 即可
⑧ 引用占位符(注意区别于使用占位符)
int num = 100;
__asm__ __volatile__ (
"add %0, %1, #100"
: "=r"(num)
: "0"(num) @此时%1会和%0使用同一个寄存器
);
input 部分的0 即代表%0,引用时不可以加% ,且
只能input 引用output
;引用是为了分清输出、输入部分
特别注意:内嵌汇编部分圆括号后的;不能遗漏!!!