Hive安装、使用及运行参数配置说明
一、Hive安装
1. 官网下载hive安装包并解压;
2. 修改环境变量
vim ~/.bash_profile
export HIVE_HOME=
export PATH=$PATH:$HIVE_HOME/bin
source ~/.bash_profile3. 执行hive --version

4. 配置hive-env.sh
cp $HIVE_HOME/conf/hive-env.sh.template ./hive-env.sh
vim hive-env.sh
#配置HADOOP地址
# Set HADOOP_HOME to point to a specific hadoop install directory
# HADOOP_HOME=${bin}/../../hadoop
export HADOOP_HOME=5. 配置hive-site.xml
cp $HIVE_HOME/conf/hive-default.xml.template ./hive-site.xml
vim hive-site.xml
# 在文件开始插入一下内容,主要是数据库的连接信息
javax.jdo.option.ConnectionUserName 用户名(这是新添加的,记住删除配置文件原有的哦!)
root
javax.jdo.option.ConnectionPassword 密码
123456
javax.jdo.option.ConnectionURL mysql
jdbc:mysql://192.168.1.1:3306/hive
javax.jdo.option.ConnectionDriverName mysql驱动程序
com.mysql.jdbc.Driver
6. 复制mysql的驱动程序到 $HIVE_HOME/lib下面
mysql-connector-java-5.1.39-bin.jar

7. 确保hive-site.xml中配置的数据库连接信息已经创建好
8. 测试
报错:Failed with exception java.io.IOException:java.lang.IllegalArgumentException: java.net.URISyntaxException: Relative path in absolute URI: ${system:user.name}
解决方案:https://blog.csdn.net/u011817217/article/details/88814757
二、Hive命令行
输入$HIVE_HOME/bin/hive –H 或者 –help 可以显示帮助选项:
说明:
1、 -i 初始化 HQL 文件。
2、 -e 从命令行执行指定的 HQL
3、 -f 执行 HQL 脚本
4、 -v 输出执行的 HQL 语句到控制台
5、 -p
6、 -hiveconf x=y Use this to set hive/hadoop configuration variables.
$HIVE_HOME/bin/hive -e 'show databases'
#执行本地HQL脚本文件
$HIVE_HOME/bin/hive -f /home/my/hive-script.sql
#执行hdfs上HQL脚本文件
$HIVE_HOME/bin/hive -f hdfs://:/hive-script.sql
#初始化HQL
$HIVE_HOME/bin/hive -i /home/my/hive-init.sql
$HIVE_HOME/bin/hive -e 'select a.col from tab1 a'
--hiveconf hive.exec.compress.output=true
--hiveconf mapred.reduce.tasks=32
三、Hive参数配置
开发 Hive 应用时,不可避免地需要设定 Hive 的参数。设定 Hive 的参数可以调优 HQL 代码的执行效率,或帮助定位问题。
然而实践中经常遇到的一个问题是,为什么设定的参数没有起作用?这通常是错误的设定方式导致的。
根据Hive参数配置的生效作用域,可以分为三类:
1. 全局有效(配置文件:hive-site.xml)
用户自定义配置文件:$HIVE_HOME/conf/hive-site.xml
默认配置文件:$HIVE_HOME/conf/hive-default.xml
用户自定义配置会覆盖默认配置。
另外,Hive 也会读入 Hadoop 的配置,因为 Hive 是作为 Hadoop 的客户端启动的,Hive 的配置会覆盖 Hadoop 的配置。
配置文件的设定对本机启动的所有 Hive 进程都有效。(hive-en.sh中配置了HADOOP_HOME)
2. Hive启动实例有效(命令行参数)
1)启动 Hive(客户端或 Server 方式)时,可以在命令行添加-hiveconf 来设定参数
例如:bin/hive -hiveconf hive.root.logger=INFO,console
2)设定对本次启动的 Session(对于 Server 方式启动,则是所有请求的 Sessions)有效。
3. Hive的连接Session有效(参数声明)
可以在 HQL 中使用 SET 关键字设定参数,这一设定的作用域也是 session 级的。
比如:
set hive.exec.reducers.bytes.per.reducer= 每个 reduce task 的平均负载数据量
set hive.exec.reducers.max= 设置 reduce task 数量的上限
set mapreduce.job.reduces= 指定固定的 reduce task 数量 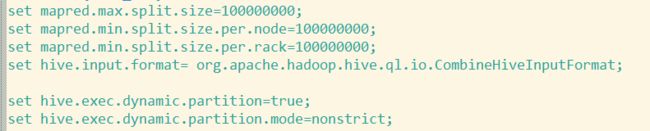
说明:上述三种设定方式的优先级依次递增。即参数声明覆盖命令行参数,命令行参数覆盖配置文件设定。