本文是对HDFS技术的一个初步学习的总结,包括如下章节的内容:
- 概述
- 架构
- 命令行接口
- 常见HDFS命令
- 远程访问
参考资料:
1、本文介绍的内容依赖hadoop环境,关于hadoop运行环境的搭建可参见《Hadoop运行环境搭建》。
一、概述
HDFS是一种适合运行在商用硬件(commodity hardware)上的分布式文件系统。和其他的分布式文件系统相比较,它有如下特点:
1、适合存储超大文件
2、适合一次写入,多次读取
3、是一个高度容错性的系统,适合部署在廉价的机器上
但是当前的HDFS系统,对如下的一些应用场景不太适合:
1、低时延的数据访问
2、大量的小文件
3、多用户写入,任意修改文件
二、体系结构
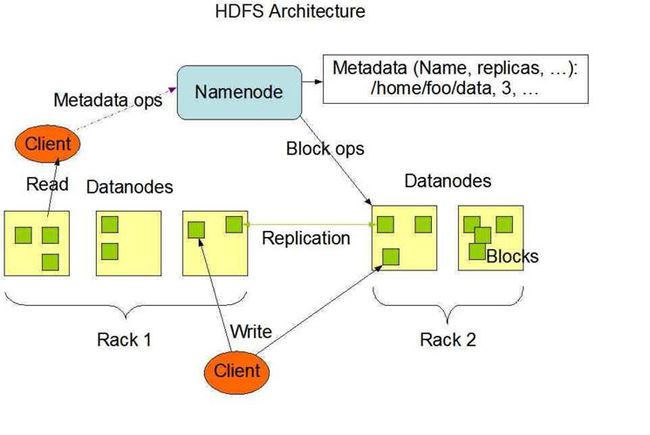
一个HDFS集群系统,包含两类节点,以管理节点-工作节点(master-slave)模式运行,即一个namenode(管理节点)和多个datanode(工作节点)。NameNode管理文件系统的元数据,DataNode存储实际的数据。客户端通过同NameNode和DataNodes的交互访问文件系统。客户端联系NameNode以获取文件的元数据,而真正的文件I/O操作是直接和DataNode进行交互的。
需要说明的是,从hadoop2.x开始,增加了联邦HDFS特性,可以允许有多个namenode节点。
下面详细介绍HDFS系统中的几个重要概念。
(一)数据块(block)
每个磁盘都有默认的数据块大小,这是磁盘进行数据读/写的最小单位。构建于本地磁盘之上的文件系统(如windows,linux文件系统)也有文件系统块的概念,一般其块的大小是磁盘块的整数倍。文件系统块一般为几千字节,磁盘块一般为512字节。当然,这些信息对进行文件操作的用户来说是透明的。
HDFS作为一个分布式文件系统,其数据是存储在多台机器上的,同样也有块(block)的概念。但是HDFS的块非常大,默认为128MB。HDFS上的文件被按照块大小划分为多个块,每个块是一个独立的存储单元。不过,如果HDFS文件大小小于1个块的大小,其实际占用空间不会占据整个块大小(如128MB)空间,而是按实际文件大小占用空间。
HDFS采用块进行设计带来很多好处,比如,一个文件的大小可以非常大,可超过任意一台单独机器上的磁盘容量,文件的块可以分开存储在集群上的多态机器上。另外,这给HDFS的容错和高可用性的设计业带来方便,HDFS会将同一个数据块复制到物理上独立的几台机器上(默认为3个),这样如果一台机器出现问题,系统可以从其它机器上获取数据,而且这个过程对用户来说是透明的。
(一)namenode、datanode、client
NameNode是HDFS系统中的管理者,主要负责管理文件系统的命名空间、集群配置信息和存储块的复制信息等。NameNode会将文件系统的Meta-data存储在内存中,这些信息主要包括了文件信息、每一个文件对应的文件块的信息和每一个文件块在DataNode的信息等。
DataNode是文件存储的基本单元,它将Block存储在本地文件系统中,保存了Block的Meta-data,同时周期性地将所有存在的Block信息发送给NameNode。
Client是HDFS文件系统的客户端,与Namenode、Datanode交互,进行实际的文件读写。最终用户是使用client来完成对HDFS系统的操作。
下图是一个简单的对HDFS系统架构的一个示意图:
三、命令行接口
从最终用户的角度看HDFS文件系统,类似linux下的文件系统,HDFS也是采用树形层次结构来组织目录和文件,只不过与本地Linux文件系统不同,其文件数据是分布存储在集群上的各个机器上的。从使用的角度看,我们不用关心这点,就把HDFS当作一个传统的文件系统看即可。
既然是一个文件系统,HDFS也提供了多种客户端方式让用户可以进行文件系统的相关操作,如读取文件、新建目录、上传文件、移动文件、删除数据等。我们可以通过HDFS提供的命令行接口来访问HDFS系统,也可以通过HDFS提供的编程API(如JAVA API)编写程序来访问HDFS系统。
使用命令行接口访问HDFS系统是最基本和最简单的操作HDFS系统的方式。HDFS命令行接口的基本语法格式是:
hadoop fs 命令选项 文件路径
其中hadoop是一个可执行的程序,位于hadoop安装目录的bin目录下,一般在搭建环境时该bin目录已经加入环境变量,所以我们可以在任意当前目录下执行hadoop程序。
最基本的如 hadoop fs -help 可以显示HDFS命令行接口的各种帮助信息。
下面章节我们来详细介绍HDFS提供的一些常见命令。
四、常见HDFS命令
下面介绍几个常用的HDFS命令,大多数的HDFS的命令与linux下的文件系统命令很相似。
先说明下,下面的例子要求运行命令行的控制台所在的机器与namenode节点在一台机器上。
- ls查看文件系统
举例:
hadoop fs -ls /
上面命令的含义是,列出HDFS系统根目录下所有的文件和目录。
hadoop fs -ls /hello
上面命令的含义是,查看/hello目录下的内容。
hadoop fs -ls /hello/test.txt
上面命令的含义是,查看/hello/test.txt文件的内容。
- mkdir创建目录
举例:
hadoop fs -mkdir /data
上面命令的含义是,在根目录下创建data目录。
hadoop fs -mkdir /data/tmp
上面命令的含义是,在/data目录下创建 tmp目录。
- copyFromLocal 拷贝本地文件或目录到HDFS系统
举例:
hadoop fs -copyFromLocal test.txt /data
上面命令的含义是,将本地当前目录下的test.txt文件拷贝到HDFS系统上的/data目录下,结果/data目录下多了一个test.txt文件。
hadoop fs -copyFromLocal test.txt /data/good.txt
上面命令的含义是,将本地当前目录下的test.txt文件拷贝到HDFS系统上的/data目录下,并且命名为good.txt,结果/data目录下多了一个good.txt文件。
hadoop fs -copyFromLocal data /users
上面命令的含义是,将本地当前目录下的data目录及其下的所有内容拷贝到HDFS系统下的/users目录下。
hadoop fs -copyFromLocal data /users/xxx
上面命令的含义是,将本地当前目录下的data目录及其下的所有内容拷贝到HDFS系统下的/users目录下,并且拷贝后的目录名为xxx。
- put 上传本地文件到HDFS系统上
该命令的功能类似 copyFromLocal 命令,但命令名更简洁
- copyToLocal 拷贝HDFS系统上的文件或目录到本地
该命令与copyFromLocal 类似,不过copyToLocal 是将HDFS系统上的文件或目录拷贝到本地,而copyFromLocal 是将本地文件或目录拷贝到HDFS系统上。
举例:
hadoop fs -copyToLocal /data/test.txt .
上面命令的含义是, 将HDFS系统上/data目录下的test.txt文件拷贝到本地当前目录下。注意最后的 . 代表本地当前目录。
hadoop fs -copyToLocal /data /home/hadoop
上面命令的含义是, 将HDFS系统上/data目录及其下面的所有内容拷贝到本地目录/home/hadoop下。
- get 从HDFS上拷贝文件到本地
该命令的功能类似 coptToLocal命令,但命令名更简洁
- rm删除文件或目录
举例:
hadoop fs -rm /users/data/test.txt
上面命令的含义是, 删除HDFS系统上 /users/data目录下的test.txt文件。
hadoop fs -rm -r /users/xxx
加上-r参数,上述命令删除/users/xxx目录及目录下的所有内容
- cp 拷贝文件或目录
举例:
hadoop fs -cp /data/test1.txt /data/test.txt /data/examples
上面命令的含义是,将 /data/test1.txt 文件 和 /data/test.txt文件拷贝到/data/examples目录下。
hadoop fs -cp /data /users
上述命令的含义是,将/data目录及目录下所有内容拷贝到 /user目录下。
- mv 移动、重命名文件或目录
举例:
hadoop fs -mv /data/test.txt /data/info
上述命令的含义是,将/data/test.txt 文件移动到 /data/info目录下。注意,如果info目录不存在,则是重命名操作,即将test.txt的文件名改为info名。
hadoop fs -mv /data/test1.txt /data/info/test1.txt.back
上述命令的含义是,将/data/test1.txt 文件移动到 /data/info目录下,并改名为test1.txt.back
hadoop fs -mv /data/examples /data/info
上述命令的含义是,将/data/examples目录及目录下面所有内容移到/data/info目录下
- cat 查看文件的内容
举例:
hadoop fs -cat /users/data/test1.txt
上述命令会在控制台上显示test1.txt文件的内容
五、远程访问
从上面的一些例子中可以看出,站在使用的角度,利用命令行接口访问HDFS,与linux下的文件操作很类似。
需要提出来的是,我们前面例子中所有指定的文件和目录都是以根节点 / 开始,实际上对于HDFS系统,完整的路径是一个URI,完整的路径应该这样操作:
hadoop fs -ls hdfs://localhost:8020/data
只是因为我们操作的命令行所在的机器就是namenode运行的机器上(如果是单机部署,所有服务都在一台机器上),而且namenode的默认运行在8020端口上。所以我们可以省去前面协议部分,如下面的命令了:
hadoop fs -ls /data
这样还有一个问题是,如果我们想在另外一台机器上远程访问HDFS文件系统,该怎么处理呢?这需要如下的处理:
1、首先远程的客户端(运行hadoop fs命令的机器)上已经搭建好hadoop环境,可以正常执行hadoop命令。我们可以在独立模式下测试是否正常。
2、被访问的HDFS系统,其core-site.xml配置文件中的fs.defaultFS属性值不能设置为localhost,需要设置为该机器的实际ip地址。如:
fs.defaultFS
HDFS://192.168.12.3/
注意,如果修改core-site.xml文件后,需要重启服务。具体可参加《Hadoop运行环境搭建》一文。
3、客户端机器与服务器(运行hadoop的服务器)网络上是可连接的,然后执行命令时带完整的协议头部分。如:
hadoop fs -ls hdfs://192.168.12.3/data
上面的192.168.12.3就是hadoop服务器namenode运行机器的ip地址,因为端口采用默认的8020端口,所以可以省略端口号。