一、hadoop的部署安装
1、安装JDK:下载jdk,解压,配置环境变量
2、安装hadoop:下载安装包,解压
利用tar -zxvf把hadoop的jar包放到指定的目录下。
tar -zxvf /home/software/hadoop-2.4.1.tar.gz
-z:以gz结尾的文件就是用gzip压缩的结果。与gzip相对的就是gunzip,这个参数的作用就是用来调用gzip。
-x:--extract,--get解压文件
-v:显示操作过程,这个参数很常用
-f:使用文档名,注意,在f之后要立即接文档名,不要再加其他参数
二、修改hadoop配置文件,为启动hadoop做准备
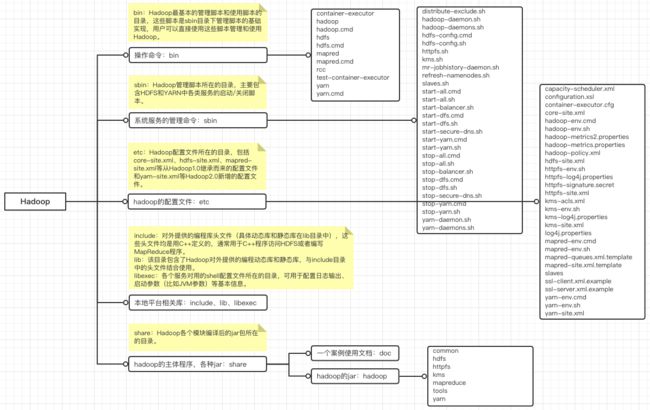
1、先熟悉下hadoop整个的目录结构
1)bin:Hadoop最基本的管理脚本和使用脚本的目录,这些脚本是sbin目录下管理脚本的基础实现,用户可以直接使用这些脚本管理和使用Hadoop。
2)sbin:Hadoop管理脚本所在的目录,主要包含HDFS和YARN中各类服务的启动/关闭脚本。
3)etc:Hadoop配置文件所在的目录,包括core-site.xml、hdfs-site.xml、mapred-site.xml等从Hadoop1.0继承而来的配置文件和yarn-site.xml等Hadoop2.0新增的配置文件。
4)本地平台相关库(include、lib、libexec),include:对外提供的编程库头文件(具体动态库和静态库在lib目录中),这些头文件均是用C++定义的,通常用于C++程序访问HDFS或者编写MapReduce程序。lib:该目录包含了Hadoop对外提供的编程动态库和静态库,与include目录中的头文件结合使用。libexec:各个服务对用的shell配置文件所在的目录,可用于配置日志输出、启动参数(比如JVM参数)等基本信息。
5)share:Hadoop各个模块编译后的jar包所在的目录。
2、hadoop重点目录介绍及修改
1)etc/hadoop/hadoop-env.sh
配置etc/hadoop/hadoop-env.sh文件,修改为你的jdk的安装位置。
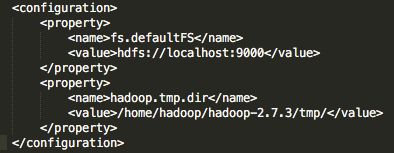
2)etc/hadoop/core-site.xml
编辑文件etc/hadoop/core-site.xml文件,指定默认文件系统和工作空间(现在该路径下还没有tmp文件夹,执行完hdfs格式化后便可看到相关文件)。
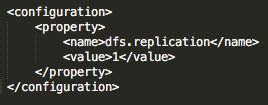
3)etc/hadoop/hdfs-site.xml
编辑文件etc/hadoop/hdfs-site.xml文件,设置文件副本数,也就是文件分割成块后,要复制块个数(由于此处就本机一个节点,伪分布式,所以就配置为1,文件本身,不需要副本)。
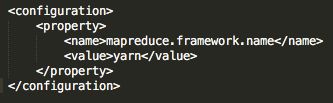
4)etc/hadoop/mapred-site.xml
编辑文件etc/hadoop/mapred-site.xml文件,此文件其实不存在,是把存在的mapred-site.xml.template修改为mapred-site.xml(mv mapred-site.xml.template mapred-site.xml),用于指定资源调度框架。
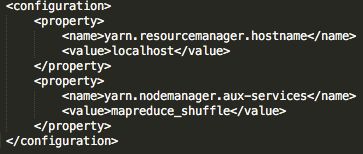
5)etc/hadoop/yarn-site.xml
编辑文件etc/hadoop/yarn-site.xml文件,yarn也是分布式管理的,所以配置一个主服务器,然后还要配置中间数据调度的机制。
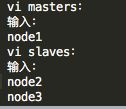
6)配置masters和slaves主从结点
配置/masters和/slaves来设置主从结点,注意最好使用主机名,并且保证机器之间通过主机名可以互相访问,每个主机名一行。
总结:配置结束,把配置好的hadoop文件夹拷贝到其他集群的机器中,并且保证上面的配置对于其他机器而言正确,例如:如果其他机器的Java安装路径不一样,要修改etc/hadoop/hadoop-env.sh。
三、启动hadoop
1)格式化hdfs
在bin/hadoop中执行 ./hadoop namenode -format,或如下图直接执行。
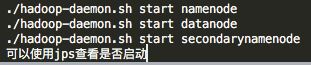
2)启动hdfs
mapreduce不是服务,只是一个库,所以不需要启动。hdfs和yarn是相互独立的服务,可以单独启动,也可以使用hadoop的脚本自动化启动。
(1)方法一:分别启动
启动hdfs的脚本在sbin/hadoop-daemon.sh中,手动启动方式如下:
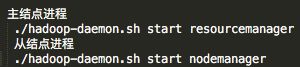
启动yarn的脚本在sbin/yarn-daemon.sh中,手动启动方式如下:
(2)方法二:自动化启动
启动hdfs,sbin/start-dfs.sh
启动yarn,sbin/start-yarn.sh
(3)方法三:
同时启动hdfs和yarn,sbin/start-all.sh