这篇文章主要介绍了一个名为Aluminum通信库,在这个库中主要针对Allreduce做了一些关于计算通信重叠以及针对延迟的优化,以加速分布式深度学习训练过程。
分布式训练的通信需求
通信何时发生
一般来说,神经网络的训练过程分为三步:前向传播、反向传播以及参数优化。在使用数据并行进行分布式训练的情况下,通信主要发生在反向传播之后与参数优化之前,在此阶段各个计算节点需要进行梯度的同步。广义上来讲,梯度的同步过程符合Allreduce语义。从实现上来说,我们既可以通过中心化的参数服务器架构来实现梯度同步,也可以通过去中心化的MPI_Allreduce接口实现梯度同步。本文主要关注的是去中心化的Allreduce实现。
神经网络本身是一个层次性的架构,在反向传播的过程中,梯度是从从后向前依次计算的。换句话说,靠近输出层的梯度先于靠近输入层的梯度被计算出来。那么,通信需求就依赖于梯度同步的粒度。在极端情况下,我们可以把所有层的梯度都放到一个buffer中去做Allreduce(一般也没人这么做吧,顶多针对某些层做Tensor Fusion)。另一方面,我们可以针对每一层的梯度做Allreduce,只要该层的梯度被计算出来,我们就对它进行同步。本文所实现的方法属于第二类,神经网络的每一层都有自己的buffer。对于某些需要学习参数的层如BN,本文的实现会为相应的参数申请单独的buffer。
通信量有多少
在数据并行分布式训练过程中,每一次迭代的通信量一般只取决于神经网络的模型结构,与其他的因素无关(当然也有例外,比如Embedding层的通信量会受batch size的影响。但Embedding一般只用在CTR和NLP模型,对于CV的模型,batch size一般不会影响整体通信量)。
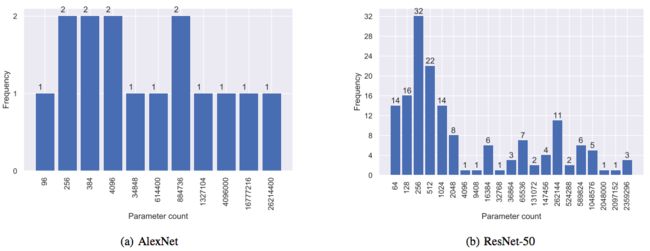
上图展示了AlexNet和ResNet-50参数量的直方图。可以看到,AlexNet是一个比较浅的网络,它包含5个卷积层以及3个较大的全连接层,这3个全连接层包含了模型大部分参数。在AlexNet中,除了最后一层,每一层都有一个偏置项,因此它包含许多small buffer。ResNet-50是一个更现代的CNN模型,它包含更多的卷积层和较少的全连接层,以及一些BN层。ResNet-50不包含偏置项,但由于BN层的存在,它依然包含许多small buffer。显然,对于AlexNet和ResNet-50来说,我们需要对许多small buffer进行Allreduce操作。除此之外,模型中也存在很多large buffer需要通信,这就导致单一的Allreduce算法并不能在所有的buffer size达到最优的通信效率。
计算和通信开销
本小节作者主要比较了ResNet-50在训练过程中的“计算”和“通信”开销。为什么这里给计算和通信打引号呢,是因为作者统计的并不是真正的计算和通信的开销,而是计算和通信各自的主要开销。对于计算时间,作者使用cuDNN统计了ResNet-50所有卷积层的计算开销;而对于通信时间,作者使用NCCL统计了Allreduce过程的通信开销。由此可知,作者所统计的计算和通信开销并不是完整训练过程中的开销,只是真正开销的一部分。
在讨论计算和通信开销时,作者分了两种情况进行讨论:强可扩展和弱可扩展下的计算通信开销比例。关于强可扩展和弱可扩展的定义,可以参考HPC Wiki:
In case of strong scaling, the number of processors is increased while the problem size remains constant. This also results in a reduced workload per processor.
In case of weak scaling, both the number of processors and the problem size are increased. This also results in a constant workload per processor.
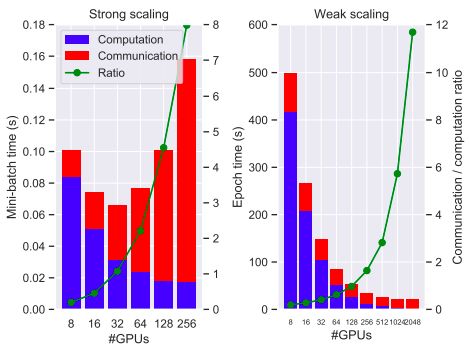
上图展示了强可扩展(左)和弱可扩展(右)两种情况下计算和通信时间各自所占的比例。在强可扩展的情况下,随着GPU数量的增加,总的batch size保持不变。这样一来,分到每块GPU上的训练样本数就会减少,每块GPU的计算开销也会相应降低。由于总的batch size不变,所以总的迭代次数也不会变化,那么随着GPU的增加,节点间的通信开销也会增加。在弱可扩展的情况下,随着GPU数量的增加,每块GPU所处理的训练样本数保持不变,总的batch size会随着GPU数量的增加而增加。这就表明训练的迭代次数会减少,也意味着通信发生的频次会降低。在这种情况下,计算是线性扩展的,但是通信的占比还是会随着GPU数量的增加而增加。从图上可以看出,当GPU数量达到2048时,通信开销大概是计算开销的12倍。
无论是强可扩展还是弱可扩展的情况下,随着GPU数量的增加,节点间的通信开销所占的比例会越来越大,这就会抵消掉分布式训练带来的收益。
优化方法
在这一节,作者介绍了两种通信优化方法:计算——通信重叠以及latency-efficient Allreduce算法。这两个优化方法都不是由作者首次提出,但是作者在他们的通信库Alumunium中实现了这些优化算法。
计算——通信重叠的思路非常简单,就是尽可能地让Allreduce操作和反向传播、参数优化等操作并行执行。如果某一层的梯度被计算出来,那么直接在相应的buffer上异步地去执行Allreduce操作。其它层的反向传播可以按照相同的方式执行,并在该层的优化阶段开始时完成Allreduce。这样一来,所有的Allreduce都可以被相关层中的反向传播以及剩余层中的计算所隐藏。然而,反向传播与参数优化之类的操作一般会放在GPU上去执行,而节点间的通信一般由MPI完成,我们并不希望CUDA操作阻塞MPI通信,反之亦然。因此,我们需要一些额外的编码工作来实现相应的功能。
如果我们能够让Allreduce算法跑的更快,那么通信操作会更容易地被隐藏到计算中。目前,许多深度学习框架都采用Ring Allreduce算法实现梯度同步,Ring Allreduce是一种带宽最优的算法,它在共享内存系统以及小型的分布式内存系统中表现良好。但是Ring Allreduce并不是延迟最优的,如果进行Reduce的buffer size比较小,那么Ring Allreduce的性能就会下降。基于树形结构的Allreduce算法能够针对延迟进行优化,Recursive-Doubling和Recursive-Halving/Recursive-Doubling算法在传输小消息上表现更好。假设\(\alpha\)是网络延迟,\(\beta\)是带宽的倒数,\(p\)是处理器数量,\(n\)是buffer的大小,那么不同Allreduce算法的通信时间如下表所示:
| 拓扑结构 | 算法名称 | 通信时间 |
|---|---|---|
| 环形 | Ring | \(2(p-1)\alpha+2\frac{p-1}{p}n\beta\) |
| 树形 | Recursive-Doubling | \(\log_p(\alpha+n\beta)\) |
| 树形 | Recursive-Halving/Recursive-Doubling | \(2\log_p \alpha + 2\frac{p-1}{p}n\beta\) |
可以看到,Recursive-Halving/Recursive-Doubling相比于Ring Allreduce,二者的带宽项是相同的,而Recursive-Halving/Recursive-Doubling具有更小的延迟。本文作者开发的Aluminium通信库,把基于树形拓扑的Allreduce算法集成到NCCL中,并根据缓冲区大小和处理器数量动态选择最优的Allreduce算法。
实现思路
当前的MPI分发版本已经针对各种类型的通信配置做了优化,它会根据缓冲区大小以及处理器数量选择合适的算法。此外,一些MPI版本同样支持CUDA,它们可以接受GPU缓冲区的指针并在该缓冲区上进行通信操作。那么我们为什么不直接使用这些CUDA-aware MPI中实现的Allreduce算法呢?这是因为,MPI不了解由用户定义的CUDA流,因此MPI和CUDA编程模型之间会出现语义不匹配的情况,这会产生不必要的同步操作,从而导致额外的通信和计算开销。
用户定义的CUDA执行流对MPI Runtime来说是透明的,因此,当用户把一个GPU缓冲区传给MPI程序时,MPI Runtime无法确定将要写入该缓冲区的流上是否有待处理的计算。为了保证kernel函数写入GPU缓冲区的正确性,用户必须手动地同步CUDA流,这就导致我们无法重叠计算和通信操作。同样,MPI Runtime对于CUDA流来说也是透明的,CUDA流无法确定是否应该等待某些阻塞操作的完成。显然,这种频繁的同步阻塞会严重影响网络和GPU的利用率。此外,作者还指出,当前版本的CUDA-aware MPI不能在多线程环境下正确地处理GPU缓冲区上的操作。
既然当前版本的CUDA-aware MPI有以上种种问题,那么作者就提出了几种解决方案。第一种方案是把同步操作放到MPI中去执行,这样能够保证正确性。但是,MPI Runtime并不知道哪一个CUDA流会操作GPU缓冲区,因此每次同步操作都要阻塞GPU上的所有流。显然,这种方案并没有解决上述性能问题。第二种方案是把MPI通信操作当做kernel函数放到CUDA流中执行。NCCL就是采用这种方案,其中的每个通信操作都会接收一个CUDA流,把通信操作放到该流中执行。这种方法不会阻塞CPU,但是会阻塞GPU上的CUDA流。不幸的是,MPI中的通信操作并不能接收CUDA流作为参数。在第三种方案中,作者发现把某个CUDA流单独绑定到MPI通信器上是可行的,所有使用MPI通信器和GPU缓冲区的操作都可以假定该缓冲区由该流中的某个kernel函数写入,并且MPI Runtime仅对该流执行适当的同步。在MPI中,这种关系可以被实现为绑定在通信器上的某个属性。
Aluminum通信库
Aluminum是作者开发的一个开源通信库,它以MPI和NCCL等为后端,提供了泛化的通信API。相比于MPI和NCCL,Aluminum更像是一个接口层,只需要简单的改动,它就能跑在不同的硬件上。
特性介绍
Aluminum基于C++11实现,API类似于MPI中的接口,通过模板技术实现了在不同后端之间的切换。下表展示了Aluminum支持的后端以及各个后端的一些特性。
| 后端 | 算法支持 | 特性 |
|---|---|---|
| MPI | Ring、Recursive-Doubling、Recursive-Halving/Recursive-Doubling | Ubiquitous, optimized |
| NCCL | Ring | GDR, optimized for GPUs |
| MPI-CUDA | Ring、Recursive-Doubling、Recursive-Halving/Recursive-Doubling | Host-Transfer Allreduce |
实现细节
通信引擎
在Aluminum中,所有在Host端进行且不阻塞主线程通信的操作都会被放到后台线程中执行,这个线程被称为通信引擎。这个后台线程由通信库绑定到CPU的某个核上,并且采用某种启发式的方法避免与其他线程产生冲突。所有的异步操作都通过一个state对象提交到通信引擎中,这些state对象被放在一个无锁的生产者——消费者队列中等待执行。通过调用state对象的step方法,相应的操作就会被非阻塞式地执行。当操作执行完成后,通信引擎可以通过在request对象中自动设置一个标志,以指示其他线程该操作已完成。Aluminium的MPI后端利用通信引擎在Host端提供异步调用以实现某些自定义算法,并通过MPI_Test轮询提供非阻塞式MPI操作。
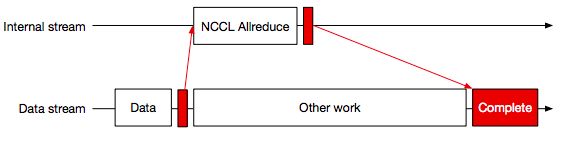
Aluminum主要关注的是对GPU缓冲区的非阻塞式通信。对于NCCL后端来说,非阻塞式的Allreduce会自动地运行在CUDA流中,整个过程如上图所示。通过调用Al::Wait,Aluminum就可以等待通信操作完成,这就允许Host端在GPU通信时进行其他操作。
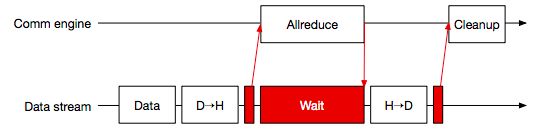
对于延迟是瓶颈的工作流来说,Aluminum基于MPI的树形Allreduce实现了一种阻塞式的Allreduce算法。这种实现相对来说比较简单直观:把GPU缓冲区拷贝到Host内存中,然后执行Allreduce,最后把结果拷贝回GPU缓冲区。为了避免Host端被阻塞,该操作相关的kernel函数以及事件都会被放入绑定在通信器的CUDA流中,然后委托给通信引擎执行。在数据从GPU拷贝到CPU内存的过程中,Aluminum会轮询CUDA流以判断相应的GPU缓冲区是否已经写入完成,这样可以有效地防止数据竞争。阻塞式Allreduce的实现如上图所示。

上图阐述了非阻塞式Allreduce的实现,可以看到它与阻塞式类似,只不过数据拷贝以及同步等待都被转移到绑定在MPI通信器的CUDA流上。
除了Allreduce,Aluminum还实现了Send和Recv操作。对于Send操作来说,Aluminum首先把数据从GPU显存拷贝到CPU内存中,然后再调用MPI_Isend;对于Recv操作来说,先调用MPI_Irecv接收数据,然后再把数据拷贝到GPU显存中。
实验测试
计算——通信重叠
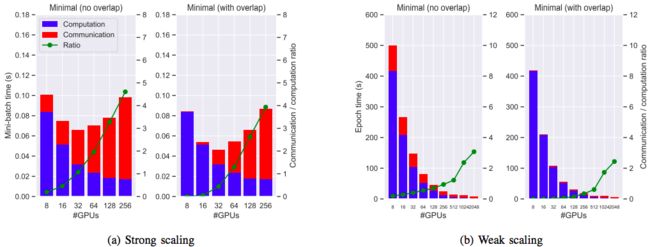
按照前面章节的配置,重新使用Aluminum(NCCL作为后端)跑了一遍ResNet-50,分别比较强可扩展(左)和弱可扩展(右)下的计算和通信占比。

从图上可以看到,在节点规模较小时,Aluminum基本上可以把通信全部重叠到计算中。在强可扩展的情况下,如果使用32块GPU,那么整体训练速度大概能加快1.4倍;如果GPU数量超过32块,那么我们就没有足够的计算量来隐藏通信,加速效果就不太明显。在弱可扩展的情况下,如果使用不超过256块GPU,那么通信就可以被隐藏到计算中;但是当节点规模更大,使用1024或者2048块GPU时,通信开销依然很大。
延迟
为了比较NCCL和host-transfer Allreduce算法的延迟,作者比较了不同节点数量(规模为2个节点到512个节点,每个节点上4块GPU)以及不同缓冲区大小下的传输延迟。下图是不同节点规模测试得到的性能结果。
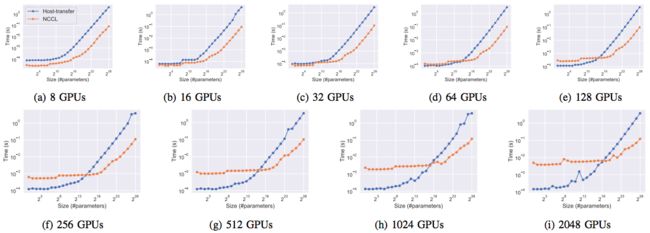
可以看到,NCCL在节点规模很小的时候性能比较好,这是因为节点规模较小时节点间的延迟也比较小,无法体现Ring-based Allreduce和Tree-based Allredcue的差距。当节点规模增加到16时,host-transfer Allreduce的优势就体现出来了。当使用32个节点时,它比NCCL快了2倍;使用512个节点时则快了20倍。注意到在小于8个节点(32块GPU)的规模下,NCCL传输小消息的延迟都比较低,这是因为NCCL内部用了GPUDriect RDMA以及GPU拓扑信息来减少通信开销和延迟。下面这幅图展示了给定GPU数量和缓冲区大小的情况下,使用哪种Allreduce算法的延迟比较低。其中绿色的点表示这种配置下,host-transfer Allreduce要比NCCL快。
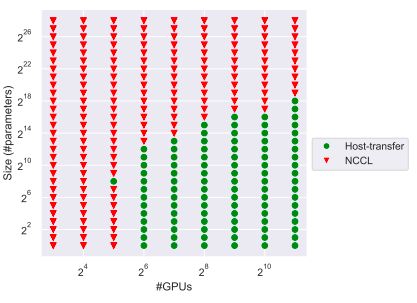
此外,作者还提出了一种名为minimal的动态选择算法,它会针对缓冲区大小和处理器数量在非阻塞式host-transfer Allreduce算法和NCCL Allreduce中选择合适的算法,选择的依据就是之前跑的benchmark。根据图中的实验结果可以看出,这种动态选择算法在弱可扩展的情形下作用比较大。