隐马尔可夫模型HMM与维特比Veterbi算法(一)
隐马尔可夫模型HMM与维特比Veterbi算法(一)
主要内容:
1、一个简单的例子
2、生成模式(Generating Patterns)
3、隐藏模式(Hidden Patterns)
4、隐马尔可夫模型(Hidden Markov Model)
一、一个简单的例子
考虑一个简单的例子,有人试图通过一片海藻推断天气——民间传说告诉我们‘湿透的’海藻意味着潮湿阴雨,而‘干燥的’海藻则意味着阳光灿烂。如果它处于一个中间状态(‘有湿气’),我们就无法确定天气如何。然而,天气的状态并没有受限于海藻的状态,所以我们可以在观察的基础上预测天气是雨天或晴天的可能性。另一个有用的线索是前一天的天气状态(或者,至少是它的可能状态)——通过综合昨天的天气及相应观察到的海藻状态,我们有可能更好的预测今天的天气。
对于上述例子,我们想知道:
1. 给出一个星期每天的海藻观察状态,之后的天气将会是什么?
2. 给定一个海藻的观察状态序列,预测一下此时是冬季还是夏季?直观地,如果一段时间内海藻都是干燥的,那么这段时间很可能是夏季,反之,如果一段时间内海藻都是潮湿的,那么这段时间可能是冬季。
下面通过建立一个典型的系统模型,来一步一步揭晓答案。
二、生成模式(Generating Patterns)
1、确定性模式(Deterministic Patterns)
考虑一套交通信号灯,灯的颜色变化序列依次是红色-红色/黄色-绿色-黄色-红色。这个序列可以作为一个状态机器,交通信号灯的不同状态都紧跟着上一个状态。
注意每一个状态都是唯一的依赖于前一个状态,所以,如果交通灯为绿色,那么下一个颜色状态将始终是黄色——也就是说,该系统是确定性的。确定性系统相对比较容易理解和分析,因为状态间的转移是完全已知的。
2、非确定性模式(Non-deterministic patterns)
为了使天气那个例子更符合实际,加入第三个状态——多云。与交通信号灯例子不同,我们并不期望这三个天气状态之间的变化是确定性的,但是我们依然希望对这个系统建模以便生成一个天气变化模式(规律)。
一种做法是假设模型的当前状态仅仅依赖于前面的几个状态,这被称为马尔科夫假设,它极大地简化了问题。显然,这可能是一种粗糙的假设,并且因此可能将一些非常重要的信息丢失。
当考虑天气问题时,马尔科夫假设假定今天的天气只能通过过去几天已知的天气情况进行预测——而对于其他因素,譬如风力、气压等则没有考虑。在这个例子以及其他相似的例子中,这样的假设显然是不现实的。然而,由于这样经过简化的系统可以用来分析,我们常常接受这样的知识假设,虽然它产生的某些信息不完全准确。
一个马尔科夫过程是状态间的转移仅依赖于前n个状态的过程。这个过程被称之为n阶马尔可夫模型,其中n是影响下一个状态选择的(前)n个状态。最简单的马尔可夫过程是一阶模型,它的状态选择仅与前一个状态有关。这里要注意它与确定性系统并不相同,因为下一个状态的选择由相应的概率决定,并不是确定性的。
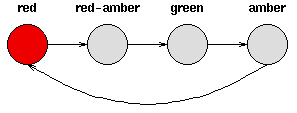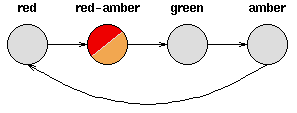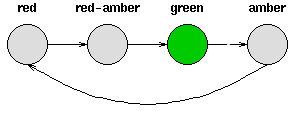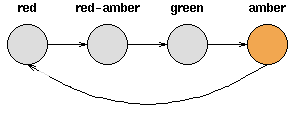
下图是天气例子中状态间所有可能的一阶状态转移情况:
对于有M个状态的一阶马尔可夫模型,共有M^2个状态转移,因为任何一个状态都有可能是所有状态的下一个转移状态。每一个状态转移都有一个概率值,称为状态转移概率——这是从一个状态转移到另一个状态的概率。所有的M^2个概率可以用一个状态转移矩阵表示。注意这些概率并不随时间变化而不同——这是一个非常重要(但常常不符合实际)的假设。
下面的状态转移矩阵显示的是天气例子中可能的状态转移概率:
也就是说,如果昨天是晴天,那么今天是晴天的概率为0.5,是多云的概率为0.375。注意,每一行的概率之和为1。
要初始化这样一个系统,我们需要确定起始日天气的(或可能的)情况,定义其为一个初始概率向量,称为pi向量。






也就是说,第一天为晴天的概率为1。
现在我们定义一个一阶马尔可夫过程如下:
状态:三个状态——晴天,多云,雨天。
pi向量:定义系统初始化时每一个状态的概率。
状态转移矩阵:给定前一天天气情况下的当前天气概率。
任何一个可以用这种方式描述的系统都是一个马尔可夫过程。
3、总结
我们尝试识别时间变化中的模式,并且为了达到这个目的我们试图对这个过程建模以便产生这样的模式。我们使用了离散时间点、离散状态以及做了马尔可夫假设。在采用了这些假设之后,系统产生了这个被描述为马尔可夫过程的模式,它包含了一个pi向量(初始概率)和一个状态转移矩阵。关于假设,重要的一点是状态转移矩阵并不随时间的改变而改变——这个矩阵在整个系统的生命周期中是固定不变的。
三、隐藏模式(Hidden Patterns)
1、马尔可夫过程的局限性
在某些情况下,我们希望找到的模式用马尔可夫过程描述还显得不充分。回顾一下天气那个例子,一个隐士也许不能够直接获取到天气的观察情况,但是他有一些水藻。民间传说告诉我们水藻的状态与天气状态有一定的概率关系——天气和水藻的状态是紧密相关的。在这个例子中我们有两组状态,观察的状态(水藻的状态)和隐藏的状态(天气的状态)。我们希望为隐士设计一种算法,在不能够直接观察天气的情况下,通过水藻和马尔可夫假设来预测天气。
一个更实际的问题是语音识别,我们听到的声音是来自于声带、喉咙大小、舌头位置以及其他一些东西的组合结果。所有这些因素相互作用产生一个单词的声音,一套语音识别系统检测的声音就是来自于个人发音时身体内部物理变化所引起的不断改变的声音。
一些语音识别装置工作的原理是将内部的语音产出看作是隐藏的状态,而将声音结果作为一系列观察的状态,这些由语音过程生成并且最好的近似了实际(隐藏)的状态。在这两个例子中,需要着重指出的是,隐藏状态的数目与观察状态的数目可以是不同的。一个包含三个状态的天气系统(晴天、多云、雨天)中,可以观察到4个等级的海藻湿润情况(干、稍干、潮湿、湿润);纯粹的语音可以由80个音素描述,而身体的发音系统会产生出不同数目的声音,或者比80多,或者比80少。
在这种情况下,观察到的状态序列与隐藏过程有一定的概率关系。我们使用隐马尔可夫模型对这样的过程建模,这个模型包含了一个底层隐藏的随时间改变的马尔可夫过程,以及一个与隐藏状态某种程度相关的可观察到的状态集合。
2、隐马尔可夫模型(Hidden Markov Models)
下图显示的是天气例子中的隐藏状态和观察状态。假设隐藏状态(实际的天气)由一个简单的一阶马尔可夫过程描述,那么它们之间都相互连接。
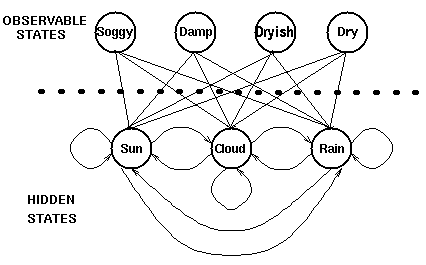
隐藏状态和观察状态之间的连接表示:在给定的马尔可夫过程中,一个特定的隐藏状态生成特定的观察状态的概率。这很清晰的表示了‘进入’一个观察状态的所有概率之和为1,在上面这个例子中就是Pr(Obs|Sun), Pr(Obs|Cloud) 及 Pr(Obs|Rain)之和。
除了定义了马尔可夫过程的概率关系,我们还有另一个矩阵,定义为混淆矩阵(confusion matrix),它包含了给定一个隐藏状态后得到的观察状态的概率。对于天气例子,混淆矩阵是:
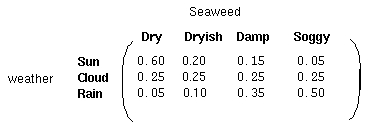
注意矩阵的每一行之和是1。
3、总结(Summary)
我们已经看到在一些过程中一个观察序列与一个底层马尔可夫过程是概率相关的。在这些例子中,观察状态的数目可以和隐藏状态的数码不同。
我们使用一个隐马尔可夫模型(HMM)对这些例子建模。这个模型包含两组状态集合和三组概率集合:
* 隐藏状态:一个系统的(真实)状态,可以由一个马尔可夫过程进行描述(例如,天气)。
* 观察状态:在这个过程中‘可视’的状态(例如,海藻的湿度)。
* pi向量:包含了(隐)模型在时间t=1时一个特殊的隐藏状态的概率(初始概率)。
* 状态转移矩阵:包含了一个隐藏状态到另一个隐藏状态的概率
* 混淆矩阵:包含了给定隐马尔可夫模型的某一个特殊的隐藏状态,观察到的某个观察状态的概率。
因此一个隐马尔可夫模型是在一个标准的马尔可夫过程中引入一组观察状态,以及其与隐藏状态间的一些概率关系。
四、隐马尔可夫模型
1、定义(Definition of a hidden Markov model)
一个隐马尔可夫模型是一个三元组(pi, A, B)。
初始化概率向量:
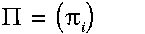
状态转移矩阵:;
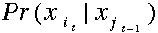
混淆矩阵:;
在状态转移矩阵及混淆矩阵中的每一个概率都是时间无关的——也就是说,当系统演化时这些矩阵并不随时间改变。实际上,这是马尔可夫模型关于真实世界最不现实的一个假设。
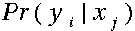
2、应用(Uses associated with HMMs)
一旦一个系统可以作为HMM被描述,就可以用来解决三个基本问题。其中前两个是模式识别的问题:给定HMM求一个观察序列的概率(评估);搜索最有可能生成一个观察序列的隐藏状态序列(解码)。第三个问题是给定观察序列生成一个HMM(学习)。
a) 评估(Evaluation)
考虑这样的问题,我们有一些描述不同系统的隐马尔可夫模型(也就是一些( pi,A,B)三元组的集合)及一个观察序列。我们想知道哪一个HMM最有可能产生了这个给定的观察序列。例如,对于海藻来说,我们也许会有一个“夏季”模型和一个“冬季”模型,因为不同季节之间的情况是不同的——我们也许想根据海藻湿度的观察序列来确定当前的季节。
我们使用前向算法(forward algorithm)来计算给定隐马尔可夫模型(HMM)后的一个观察序列的概率,并因此选择最合适的隐马尔可夫模型(HMM)。
在语音识别中这种类型的问题发生在当一大堆数目的马尔可夫模型被使用,并且每一个模型都对一个特殊的单词进行建模时。一个观察序列从一个发音单词中形成,并且通过寻找对于此观察序列最有可能的隐马尔可夫模型(HMM)识别这个单词。
b) 解码( Decoding)
给定观察序列搜索最可能的隐藏状态序列。
另一个相关问题,也是最感兴趣的一个,就是搜索生成输出序列的隐藏状态序列。在许多情况下我们对于模型中的隐藏状态更感兴趣,因为它们代表了一些更有价值的东西,而这些东西通常不能直接观察到。
考虑海藻和天气这个例子,一个盲人隐士只能感觉到海藻的状态,但是他更想知道天气的情况,天气状态在这里就是隐藏状态。
我们使用Viterbi 算法(Viterbi algorithm)确定(搜索)已知观察序列及HMM下最可能的隐藏状态序列。
Viterbi算法(Viterbi algorithm)的另一广泛应用是自然语言处理中的词性标注。在词性标注中,句子中的单词是观察状态,词性(语法类别)是隐藏状态(注意对于许多单词,如wind,fish拥有不止一个词性)。对于每句话中的单词,通过搜索其最可能的隐藏状态,我们就可以在给定的上下文中找到每个单词最可能的词性标注。
c)学习(Learning)
根据观察序列生成隐马尔可夫模型。
第三个问题,也是与HMM相关的问题中最难的,根据一个观察序列(来自于已知的集合),以及与其有关的一个隐藏状态集,估计一个最合适的隐马尔可夫模型(HMM),也就是确定对已知序列描述的最合适的(pi,A,B)三元组。
当矩阵A和B不能够直接被(估计)测量时,前向-后向算法(forward-backward algorithm)被用来进行学习(参数估计),这也是实际应用中常见的情况。
3、总结(Summary)
由一个向量和两个矩阵(pi,A,B)描述的隐马尔可夫模型对于实际系统有着巨大的价值,虽然经常只是一种近似,但它们却是经得起分析的。隐马尔可夫模型通常解决的问题包括:
1. 对于一个观察序列匹配最可能的系统——评估,使用前向算法(forward algorithm)解决;
2. 对于已生成的一个观察序列,确定最可能的隐藏状态序列——解码,使用Viterbi 算法(Viterbi algorithm)解决;
3. 对于已生成的观察序列,决定最可能的模型参数——学习,使用前向-后向算法(forward-backward algorithm)解决。
五、参考文献
http://www.52nlp.cn/hmm-learn-best-practices-one-introduction
http://www.52nlp.cn/hmm-learn-best-practices-two-generating-patterns
http://www.52nlp.cn/hmm-learn-best-practices-three-hidden-patterns
http://www.52nlp.cn/hmm-learn-best-practices-four-hidden-markov-models