双曲知识嵌入:如何将知识“融合”带入新空间?
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
知识图谱作为人类知识的结构化数据,是构建人工智能的基石。然而目前的知识图谱都是不完备的,所以需要将多个知识图谱融合以获得更完备的知识库。基于表示学习的知识关联作为知识图谱融合的新方法受到了许多关注。但知识关联模型面临着参数多、复杂性高、知识图谱维数不一致等问题。如何解决这些问题呢?
本期AI TIME PhD直播间,我们邀请到了南京大学计算机系博士研究生孙泽群分享他的观点。他提出将知识图谱的表示空间从欧式空间转换为双曲空间,提出了基于双曲空间的知识关联方法。

孙泽群:南京大学计算机系博士研究生,导师是瞿裕忠教授和胡伟副教授。主要研究方向为知识图谱表示学习及其应用,如实体对齐、链接预测和类型推断等。目前在相关领域的国际会议如VLDB、ICML、AAAI、IJCAI、EMNLP、ISWC等发表多篇论文。

一、背景
1. 什么是知识图谱?
知识图谱通过多关系图的结构来存储和表示现实世界的事实或知识。如图1所示,图的节点代表实体或概念,而节点之间的有向边带有标签来说明边的具体类型(也称为关系)。知识图谱分为实体知识图谱和概念知识图谱(本体)。实体图谱存储不同实体(或者叫实例)之间的关系,下图右边展示了一个例子,即实体Bob对实体蒙娜丽莎很感兴趣。而概念图谱则刻画了不同概念之间的关系,比如歌手属于艺术家。
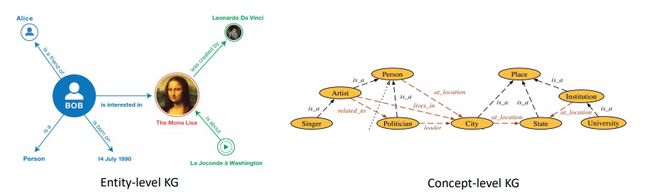
图1:实体图谱和概念图谱
2. 为何要做知识关联?
知识图谱大多由人工构建,或者是对非结构化和半结构化数据进行信息抽取而构建的,由于数据来源的不完备性,知识图谱也是不完备的。比如,百度百科和维基百科会有重合的部分,也会有互补的部分,二者融合起来可以提供更加全面的知识。通过挖掘知识图谱之间的一些关联信息,将多个知识图谱融合在一起,就是知识关联。
3. 如何实现知识关联?
知识关联包括两个任务,即实体对齐(entity alignment)和类型推断(type inference)。实体对齐旨在将两个实体图谱中共指的实体连接起来(图2中双虚线)。类型推断则是关联实体图谱和概念图谱,挖掘实体到其所属概念之间的关联(图2中虚线)。
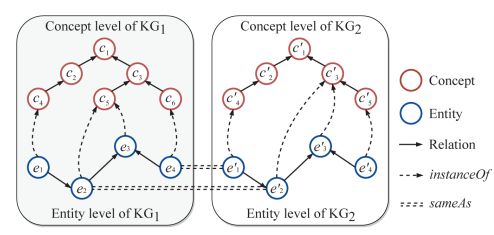
图2:实体对齐和类型推断
二、知识关联模型
如图3所示,为了实现知识关联,首先需要进行表示学习(embedding learning),将知识图谱嵌入到向量空间中,之后再进行关联学习(association learning),实现上面提到的实体对齐或类型推断任务。
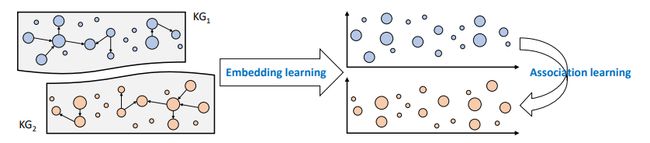
图3:嵌入学习和关联学习
1.表示学习(Embedding learning)
Embedding方法的关键就是表示学习,将每个实体用低维向量表示。知识图谱表示学习大致可以分为两大类方法,一类基于图结构和关系,另一类还会利用一些额外信息,如实体属性等。TransE作为一个经典的知识图谱嵌入模型,其核心思想就是让有相同关系的实体对的向量偏移尽可能相同。比如,要表示中国首都是北京,那么需要让“中国”向量加上“首都”向量近似等于“北京”向量。

图4:TransE模型
图神经网络由于其强大的表示学习能力,近些年被广泛使用。GCN是一个比较经典的图神经网络模型。GCN有两部分操作,首先进行邻居聚合(neighborhood aggregation),将节点i的邻居进行聚合得到邻居表示。之后再将邻居表示和节点i自身的表示组合起来,得到节点i在这一层的最终表示。但是GCN没有考虑图中边的方向与类型,只要两个节点之间有边,那么它们就是邻居,而不区分中心节点与邻居的具体关系。R-GCN针对这个问题做了改进,R-GCN考虑节点之间的关系,对于每一个关系做一个邻居聚合,最后把这些邻居表示再组合起来。比如一个知识图谱图有k个关系,R-GCN的聚合方式类似于把这个图谱按照关系拆成了 k个无向的或者说是不带类型的图,分别聚合,最后再组合起来,但是这样做复杂度很高。
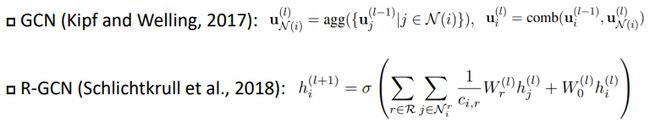
图5:图神经网络模型
2.关联学习(Association learning)
关联学习的方法则是通过监督学习或半监督学习完成的。监督学习需要已知部分关联数据比如部分实体对齐数据作为training data,目标是找出剩下的关联部分。但在现实场景中,关联学习中的监督数据却很少,有相关工作做过统计,在跨语言的维基百科中,只有10%~20%的共指页面有link。由于监督数据太少,半监督学习被引入来解决这个问题。
关联学习首先要度量节点之间的距离,比如实体x与实体y的距离。余弦相似度和欧式距离等都可以用来度量节点之间距离。之后如果要做实体对齐(类型关联同理),一个比较简单的方法就是最小化x和y间的距离。学习的时候为了区分对齐的正样本和不对齐的负样本,可以使用marginal rank loss或者limit-based loss。Marginal rank loss主要是让正样本和负样本之间有一定的距离,却无法控制距离的取值范围。而limit-based loss则可以控制距离的取值范围。

图6:关联学习
3.面临的挑战
有些知识图谱,尤其是概念图谱,具有很多层次化结构。在进行表示学习的时候,为了捕捉复杂或很深的层级结构,往往需要一个更大的空间和更高的维度来表示节点。此外,与实体对齐不同,类型推断处理的对象是实体图谱与概念图谱,由于实体数量远大于概念数量,这两个知识图谱的向量表示维数往往相差较大,基于距离最小化的方法不能适用于这种情况。

图7:面临的挑战
三、基于双曲空间的知识关联
面对上述挑战,讲者提出在双曲空间进行知识图谱表示学习。首先,双曲空间具有表达层次结构的能力,有利于表示知识图谱尤其是本体中的层次化结构。其次,双曲空间的容量要远远大于欧式空间,所以在双曲空间可以利用更少的维度来实现具有高维欧式空间同等表现力的模型。双曲空间的特性使我们能够使用很小的维数来捕捉知识图谱的结构,并且特别适合有层次结构的知识图谱。此外,现有的欧式空间模型都可以通过一些基本算子的转换变为双曲空间下表示的模型。

图8:双曲空间特性
知识关联方法包括表示学习和关联学习两个部分。其中表示学习结合了TransE与GCN的思想,先在输入层用双曲TransE做一个关系转换,即头实体+关系等于尾实体,之后再用双曲GCN在输入层上做邻居聚合得到实体表示。这样比起R-GCN就简单了很多,不需要根据不同的关系进行单独聚合。

图9:HyperKA模型的嵌入学习
得到知识图谱的双曲表示后,将其作为知识关联的输入。在做关联时,尤其是类型推断,两个知识图谱可能结构不同或者维度不同,不能强行最小化距离来拟合。所以就使用投影的方法,将节点从源空间映射到目标空间,去匹配对应的实体或者概念。

图10:HyperKA模型的关联学习
四、实验结果
1. 实体对齐(Entity Alignment)
使用DBP15K数据集,以H@K和MRR为评价标准,实验结果如下表:
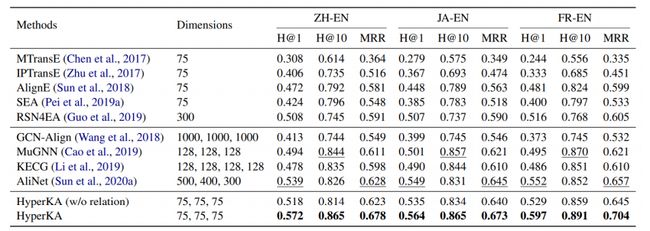
表1:实体对齐实验结果
实验中,所提出的双曲知识关联模型HyperKA的维数为75,是所有模型中最小的。实验结果显示,尽管HyperKA维数小,但它在三个数据集上的表现都优于基线模型。
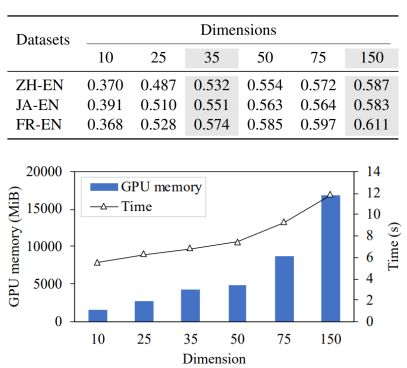
图11:维数分析
从上图可以看出HyperKA只需要35维就能超过所有基线模型。随着维数的减小,所需GPU的内存开销和训练时间都会减小。所以HyperKA模型能在有限的GPU内存开销下取得良好表现。
为了验证双曲空间带来的优化,将HyperKA模型退回到欧氏空间中,得到HyperKA(Euc.)模型。从下表的实验结果可以看出,在欧式空间下需要高维度(如300)才能达到在双曲空间下75维的表现。使用双曲空间带来了更小的内存消耗和更少的模型参数。
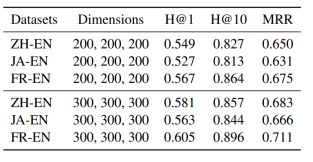
表2:HyperKA (Euc.)模型实验结果
2. 类型推断(type inference)
使用YAGO26K-906和DB111K-174数据集,以H@K和MRR为评价标准,实验结果如下表:
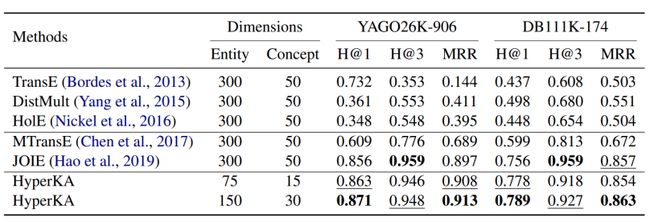
表3:类型推断实验结果
实验结果表明在H@1和MRR的评价标准下,HyperKA(150,30)优于其他模型。
HyperKA模型在实体关联和类型推断任务上都比绝大多数基线模型表现好,并且减少了模型的内存开销也减短了训练时间。
Reference:
相关代码及数据集:https://github.com/nju-websoft/HyperKA
论文:https://arxiv.org/pdf/2010.02162.pdf
Q&A环节

R-GCN 如果有k个关系时需要k个邻接矩阵表示。HyperKA怎么压缩这个关系信息?这一块没有听懂。

我们没有follow R-GCN。我们用input embeddings做一个类似TransE的学习模型,然后GCN在这个input embeddings做聚合,得到最后的表示。
等同于translational embeddings是GCN的input features,这个translational embeddings和最后的association learning是联合训练的。
那也就是在hyperbolic空间中,表示出了关系对吗?
是的
e m t
往期精彩
AI i

整理:蒋予捷
排版:岳白雪
审稿:孙泽群
AI TIME欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你!
请将简历等信息发至[email protected]!
微信联系:AITIME_HY
AI TIME是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。

更多资讯请扫码关注

(直播回放:https://b23.tv/3rU4cI)
(点击“阅读原文”下载本次报告ppt)