Python爬取全网文字并词云分析(全程一键化!)
前景引入
最近Python很火,确实很火,好像一直都比较火,哈哈哈哈。如果你也觉得很火,那么就请看完这篇文章吧,看看Python的热度到底能不能使我这篇文章火起来。
那么作为后起之秀的编程语言——Python,它到底能够做些什么了,网上一直在“炒作”Python:一键化办公,学好Python薪资翻一番,让你的生活多一点money,让你的老板对你刮目相看,让你从此找到自信!这不是吹捧,也不是浮夸。从云计算、大数据到人工智能,Python无处不在,百度、阿里巴巴、腾讯等一系列大公司都在使用Python完成各种任务,让Python越来越接地气了,它的功能也不用我说了,它的优势和特点我也不再赘述了,毕竟本篇是一个技术文章,话不多说,开干!
如果你是科研党,请看完文章!文末有惊喜哟!
项目简介
近期收到CSDN上的小粉私信,说之前一篇文章Python爬取网站小说并可视化分析,那个网站比较的好,说想要这个网站的所有书籍,自己拿去好好地研读。出于对粉丝的关心,再加上我个人也是比较喜欢文学作品的,无聊闲暇之余,看一本书陶冶一下自己的情操也不是不可的,哈哈哈。收到请求之后,我马上就开始架构思路了,我通过观察网页结构发现了它的特点,最后我加上自己的设计思路,增加词云分析这个功能,多次测试,最终达到了一键化!!!!!!!
项目思路与功能介绍
1.用户输入该网站里面的任何一本书籍的网页链接,输入储存路径回车即可,后台及运行爬虫,之后再去运行智能分词,最后利用强大的pyecharts库,来展示词云图。
2.这么多的书籍,够你看了吧,如果你不想看,想知道这本书主要讲的是什么,出现哪些高频词,最终也会帮助你理解和了解这篇文章的主要内容。
3.本期项目依靠数据分析库和Python原生态的库,进行文本分词,智能切割,智能词云算法和智能爬虫算法,有反爬技术的书写,也有数据分析的亮点。
项目实现
1.首先你必须要安装好这几个库
不会的请看这篇文章,有详细的介绍,要是看不懂我给你安装!绝对可以安装好的~
2.实现爬虫算法
提前定义好全局变量
from pyecharts import options as opts
from pyecharts.charts import WordCloud
from pyecharts.globals import SymbolType
import jieba # jieba用于分词,中文字典及其强大
from fake_useragent import UserAgent
import requests
from lxml import etree
import time
ll = []
lg = []
lk = []
lj = []
lp = []
li = []
d = {
} # 定义好相应的存储变量
def get_data(title,page,url,num):#title代表文件路径 page代表爬取的章节数 url为修订后网址 num为标签页数
with open(r"{}.txt".format(title), "w", encoding="utf-8") as file:
ua = UserAgent() # 解决了我们平时自己设置伪装头的繁琐,此库自动为我们弹出一个可用的模拟浏览器
def get_page(url):
headers = {
"User-Agent": ua.random}
res = requests.get(url=url, headers=headers)
res.encoding = 'GBK'
html = res.text
html_ = etree.HTML(html)
text = html_.xpath('//div[@class="panel-body content-body content-ext"]//text()')
num = len(text)
for s in range(num):
file.write(text[s] + '\n')
for i in range(page):
# time.sleep(2)
file.write("第{}章".format(i + 1))#写入文本数据
get_page(url+"{}.html".format(num + i))#爬虫标签页移动,数据输出爬取过程
print("正在爬取第{}章!".format(i + 1))
print("爬取完毕!!!!")
3.实现智能分词
我自己写了一个智能词云算法,包括各种小功能的实现,设计不易,拒绝白嫖哟,有需要的可以私信我或者自己下载!!!
4.主函数
def main():
try:
print("\t\t本小程序只针对:项目实现
1.输入网址和保存路径,以及爬取的章节数
 2.智能爬虫开启运行
2.智能爬虫开启运行


3.智能算法开启


4.效果展示
桌面自动出现,点击网页HTML即可展示词云,还可以自己下载,这就是pyecharts库的特点



看起来还不错吧,我也觉得效果还可以,主要是这个一键化太让我省心了,以后还可以做知网上面的,帮助科研人员做科研方面的研究,还有各个电商网站的评论,来解决老板对商品的评估,这样的一键化可以帮助我们减少浪费的时间,当然老板也会喜欢的。
源码私信我!!!!设计着实不易!!!
项目拓展
我还自己设计另一个国家社科基金数据库的词云一键化分析
科研宝宝的最爱,有需要的可以直接私信我哟,把握好大家的研究方向才是开始最正确的选择
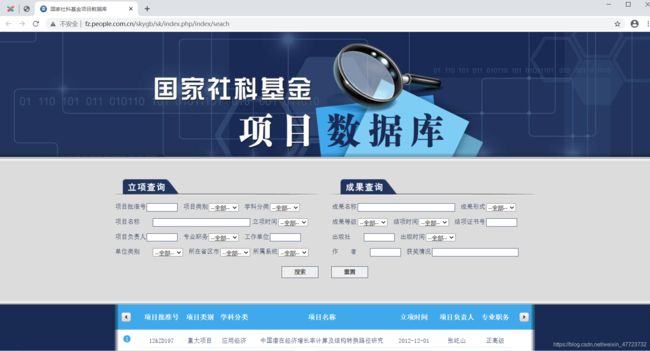 这个程序涉及到一个网页解码和转码的功能
这个程序涉及到一个网页解码和转码的功能




里面的输入类别都可以自己设计的,所有的输入框都可以自己设置筛选条件!!!!
如果你是科研党,不要它可惜了,哈哈哈哈!!!!!!
每文一语
无法预测的未来,才会充满期待