⭐ 李宏毅2020机器学习作业3-CNN:食物图片分类
更多作业,请查看⭐ 李宏毅2020机器学习资料汇总
文章目录
- 0 作业链接
- 1 作业说明
-
- 环境
- 任务说明
- 任务要求
- 数据说明
- 作业概述
- 2 原始代码
-
- 导入需要的库
- 读取图片
- 定义Dataset
- 定义模型
- 训练
- 测试
- 3 修改代码
-
- 修改1:残差神经网络
- 修改2:残差神经网络+dropout
0 作业链接
直接在李宏毅课程主页可以找到作业:
- 李宏毅的课程网页:点击此处跳转
如果你打不开colab,下方是搬运的jupyter notebook文件和助教的说明ppt:
- 2020版课后作业范例和作业说明:点击此处跳转
- 链接: https://pan.baidu.com/s/1pIdkSjvtkek8_OGUtD7zMA 提取码: v5rb
1 作业说明
环境
- jupyter notebook
- python3
- pytorch-gpu
任务说明
通过卷积神经网络(Convolutional Neural Networks, CNN)对食物图片进行分类。
数据集中的食物图采集于网上,总共11类:Bread, Dairy product, Dessert, Egg, Fried food, Meat, Noodles/Pasta, Rice, Seafood, Soup, Vegetable/Fruit. 每一类用一个数字表示。比如:0表示Bread.
任务要求
- 必须使用 CNN
- 不能使用额外的数据 (禁止使用其他图片数据集或预训练的模型)
- 不能上网寻找label
数据说明
从百度网盘下载food-11.zip文件(约1.16GB),解压后得到三个文件夹,分别是training、validation、testing
文件目录树如下:
│ hw3_CNN.ipynb
│
└─food-11
├─testing
├─training
└─validation
数据集规模:
- Training set: 9866张
- Validation set: 3430张
- Testing set: 3347张
打开一个数据集文件夹,可以看到里面的图片的命名格式、大小等。
training、validation文件夹中图片的命名格式是:[类别]_[编号].jpg,图片大小不一样。

testing文件夹中图片的命名格式是:[编号].jpg,图片大小不一样。

最终,预测结果的保存形式为:第一行是表头,第二行开始是预测结果。每一行有两列,第一列是Id,第二列是Category(类别),用逗号隔开。kaggle的评价指标是准确值(accuracy).
作业概述
输入:一张食物的图片
输出:图片中食物所属的类别(0、1、2、……、10)
模型: 卷积神经网络CNN
2 原始代码
导入需要的库
导入python库。这里的torch即pytroch,有独立显卡的建议安装gpu版本(+cuda+cudnn)。
cv2的安装:pip install opencv-python
import os
import numpy as np
import cv2
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import pandas as pd
from torch.utils.data import DataLoader, Dataset
import time
读取图片
用opencv(cv2)读取图片并存放在numpy中。
#定义一个读取图片的函数readfile()
def readfile(path, label):
# label 是一个布尔值,代表需不需要返回 y 值
image_dir = sorted(os.listdir(path))
# x存储图片,每张彩色图片都是128(高)*128(宽)*3(彩色三通道)
x = np.zeros((len(image_dir), 128, 128, 3), dtype=np.uint8)
# y存储标签,每个y大小为1
y = np.zeros((len(image_dir)), dtype=np.uint8)
for i, file in enumerate(image_dir):
img = cv2.imread(os.path.join(path, file))
# 利用cv2.resize()函数将不同大小的图片统一为128(高)*128(宽)
x[i, :, :] = cv2.resize(img,(128, 128))
if label:
y[i] = int(file.split("_")[0])
if label:
return x, y
else:
return x
#分别将 training set、validation set、testing set 用函数 readfile() 读进来
workspace_dir = './food-11'
print("Reading data")
train_x, train_y = readfile(os.path.join(workspace_dir, "training"), True)
print("Size of training data = {}".format(len(train_x)))
val_x, val_y = readfile(os.path.join(workspace_dir, "validation"), True)
print("Size of validation data = {}".format(len(val_x)))
test_x = readfile(os.path.join(workspace_dir, "testing"), False)
print("Size of Testing data = {}".format(len(test_x)))
Out:
Reading data
Size of training data = 9866
Size of validation data = 3430
Size of Testing data = 3347
定义Dataset
在 Pytorch 中,我们可以利用 torch.utils.data 的 Dataset 及 DataLoader 来"包装" data,使后续的 training 和 testing 更方便。
Dataset 需要 overload 两个函数:__len__ 及 __getitem__
- __len__ 必须要传回 dataset 的大小
- __getitem__ 则定义了当函数利用 [ ] 取值时,dataset 应该要怎么传回数据。
实际上,在我们的代码中并不会直接使用到这两个函数,但是当 DataLoader 在 enumerate Dataset 时会使用到,如果没有这样做,程序运行阶段会报错。
这里还对图片进行了数据增强。transforms表示对图片的预处理方式。
- 关于Dataset,更多详情参见:[PyTorch] dataloader使用教程
- 关于transforms,可以参考我写的这篇可视化理解pytorch中transforms的具体作用
#training 时,通过随机旋转、水平翻转图片来进行数据增强(data augmentation)
train_transform = transforms.Compose([
transforms.ToPILImage(),
transforms.RandomHorizontalFlip(), #随机翻转图片
transforms.RandomRotation(15), #随机旋转图片
transforms.ToTensor(), #将图片变成 Tensor,并且把数值normalize到[0,1]
])
#testing 时,不需要进行数据增强(data augmentation)
test_transform = transforms.Compose([
transforms.ToPILImage(),
transforms.ToTensor(),
])
class ImgDataset(Dataset):
def __init__(self, x, y=None, transform=None):
self.x = x
# label 需要是 LongTensor 型
self.y = y
if y is not None:
self.y = torch.LongTensor(y)
self.transform = transform
def __len__(self):
return len(self.x)
def __getitem__(self, index):
X = self.x[index]
if self.transform is not None:
X = self.transform(X)
if self.y is not None:
Y = self.y[index]
return X, Y
else:
return X
batch_size = 128
train_set = ImgDataset(train_x, train_y, train_transform)
val_set = ImgDataset(val_x, val_y, test_transform)
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_set, batch_size=batch_size, shuffle=False)
定义模型
先是一个卷积神经网络,再是一个全连接的前向传播神经网络。
卷积神经网络的一级卷积层由卷积层cov+批标准化batchnorm+激活函数ReLU+最大池化MaxPool构成。
class Classifier(nn.Module):
def __init__(self):
super(Classifier, self).__init__()
#torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
#torch.nn.MaxPool2d(kernel_size, stride, padding)
#input 维度 [3, 128, 128]
self.cnn = nn.Sequential(
nn.Conv2d(3, 64, 3, 1, 1), # 输出[64, 128, 128]
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # 输出[64, 64, 64]
nn.Conv2d(64, 128, 3, 1, 1), # 输出[128, 64, 64]
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # 输出[128, 32, 32]
nn.Conv2d(128, 256, 3, 1, 1), # 输出[256, 32, 32]
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # 输出[256, 16, 16]
nn.Conv2d(256, 512, 3, 1, 1), # 输出[512, 16, 16]
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # 输出[512, 8, 8]
nn.Conv2d(512, 512, 3, 1, 1), # 输出[512, 8, 8]
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # 输出[512, 4, 4]
)
# 全连接的前向传播神经网络
self.fc = nn.Sequential(
nn.Linear(512*4*4, 1024),
nn.ReLU(),
nn.Linear(1024, 512),
nn.ReLU(),
nn.Linear(512, 11) # 最后是11个分类
)
def forward(self, x):
out = self.cnn(x)
out = out.view(out.size()[0], -1) # 摊平成1维
return self.fc(out)
训练
使用训练集training set进行训练,并使用验证集validation set来选择最好的参数。
如果遇到out of memory的报错,应该调小上面的batch_size = 128。
model = Classifier().cuda() #用cuda加速
loss = nn.CrossEntropyLoss() # 因为是分类任务,所以使用交叉熵损失
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # 使用Adam优化器
num_epoch = 30 #迭代次数
for epoch in range(num_epoch):
epoch_start_time = time.time()
train_acc = 0.0
train_loss = 0.0
val_acc = 0.0
val_loss = 0.0
model.train() # 确保 model 是在 训练 model (开启 Dropout 等...)
for i, data in enumerate(train_loader):
optimizer.zero_grad() # 用 optimizer 将模型参数的梯度 gradient 归零
train_pred = model(data[0].cuda()) # 利用 model 得到预测的概率分布,这边实际上是调用模型的 forward 函数
batch_loss = loss(train_pred, data[1].cuda()) # 计算 loss (注意 prediction 跟 label 必须同时在 CPU 或是 GPU 上)
batch_loss.backward() # 利用 back propagation 算出每个参数的 gradient
optimizer.step() # 以 optimizer 用 gradient 更新参数
train_acc += np.sum(np.argmax(train_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
train_loss += batch_loss.item()
#验证集val
model.eval()
with torch.no_grad():
for i, data in enumerate(val_loader):
val_pred = model(data[0].cuda())
batch_loss = loss(val_pred, data[1].cuda())
val_acc += np.sum(np.argmax(val_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
val_loss += batch_loss.item()
#将结果 print 出來
print('[%03d/%03d] %2.2f sec(s) Train Acc: %3.6f Loss: %3.6f | Val Acc: %3.6f loss: %3.6f' % \
(epoch + 1, num_epoch, time.time()-epoch_start_time, \
train_acc/train_set.__len__(), train_loss/train_set.__len__(), val_acc/val_set.__len__(), val_loss/val_set.__len__()))
Out:
[001/030] 30.54 sec(s) Train Acc: 0.219542 Loss: 0.018593 | Val Acc: 0.223032 loss: 0.017266
[002/030] 30.32 sec(s) Train Acc: 0.323333 Loss: 0.015177 | Val Acc: 0.309621 loss: 0.015568
[003/030] 30.32 sec(s) Train Acc: 0.387188 Loss: 0.013808 | Val Acc: 0.377843 loss: 0.014594
[004/030] 30.36 sec(s) Train Acc: 0.443037 Loss: 0.012711 | Val Acc: 0.431778 loss: 0.012918
[005/030] 30.42 sec(s) Train Acc: 0.472431 Loss: 0.012017 | Val Acc: 0.211953 loss: 0.022984
[006/030] 30.44 sec(s) Train Acc: 0.502331 Loss: 0.011441 | Val Acc: 0.432945 loss: 0.013718
[007/030] 30.51 sec(s) Train Acc: 0.519562 Loss: 0.010774 | Val Acc: 0.358892 loss: 0.016559
[008/030] 30.51 sec(s) Train Acc: 0.550172 Loss: 0.010292 | Val Acc: 0.449271 loss: 0.013144
[009/030] 30.52 sec(s) Train Acc: 0.577336 Loss: 0.009582 | Val Acc: 0.427697 loss: 0.013619
[010/030] 30.57 sec(s) Train Acc: 0.597405 Loss: 0.009059 | Val Acc: 0.484548 loss: 0.012584
[011/030] 30.60 sec(s) Train Acc: 0.621224 Loss: 0.008519 | Val Acc: 0.505831 loss: 0.012606
[012/030] 30.59 sec(s) Train Acc: 0.647983 Loss: 0.007928 | Val Acc: 0.262974 loss: 0.028745
[013/030] 30.61 sec(s) Train Acc: 0.654875 Loss: 0.007988 | Val Acc: 0.560350 loss: 0.010429
[014/030] 30.62 sec(s) Train Acc: 0.667241 Loss: 0.007576 | Val Acc: 0.466472 loss: 0.013659
[015/030] 30.67 sec(s) Train Acc: 0.692581 Loss: 0.006917 | Val Acc: 0.568222 loss: 0.010538
[016/030] 30.69 sec(s) Train Acc: 0.701196 Loss: 0.006740 | Val Acc: 0.468805 loss: 0.014866
[017/030] 30.70 sec(s) Train Acc: 0.717920 Loss: 0.006458 | Val Acc: 0.495044 loss: 0.014071
[018/030] 30.70 sec(s) Train Acc: 0.733732 Loss: 0.006045 | Val Acc: 0.610787 loss: 0.009511
[019/030] 30.66 sec(s) Train Acc: 0.742347 Loss: 0.005843 | Val Acc: 0.611370 loss: 0.009757
[020/030] 30.65 sec(s) Train Acc: 0.741942 Loss: 0.005834 | Val Acc: 0.619534 loss: 0.009403
[021/030] 30.76 sec(s) Train Acc: 0.757653 Loss: 0.005436 | Val Acc: 0.648980 loss: 0.009385
[022/030] 30.75 sec(s) Train Acc: 0.777721 Loss: 0.005044 | Val Acc: 0.602915 loss: 0.010735
[023/030] 30.70 sec(s) Train Acc: 0.787046 Loss: 0.004846 | Val Acc: 0.633236 loss: 0.009841
[024/030] 30.67 sec(s) Train Acc: 0.785830 Loss: 0.004880 | Val Acc: 0.518950 loss: 0.014643
[025/030] 30.65 sec(s) Train Acc: 0.792621 Loss: 0.004609 | Val Acc: 0.644898 loss: 0.009813
[026/030] 30.71 sec(s) Train Acc: 0.816136 Loss: 0.004233 | Val Acc: 0.616327 loss: 0.011062
[027/030] 30.71 sec(s) Train Acc: 0.826373 Loss: 0.003974 | Val Acc: 0.593878 loss: 0.012730
[028/030] 30.66 sec(s) Train Acc: 0.819785 Loss: 0.004078 | Val Acc: 0.647813 loss: 0.009875
[029/030] 30.71 sec(s) Train Acc: 0.847456 Loss: 0.003512 | Val Acc: 0.596501 loss: 0.013376
[030/030] 30.64 sec(s) Train Acc: 0.849078 Loss: 0.003442 | Val Acc: 0.613703 loss: 0.010566
得到好的参数后,我们使用training set和validation set共同训练(数据量变多,模型效果更好)
train_val_x = np.concatenate((train_x, val_x), axis=0) # 将train_x和val_x拼接起来
train_val_y = np.concatenate((train_y, val_y), axis=0) # 将train_y和val_y拼接起来
train_val_set = ImgDataset(train_val_x, train_val_y, train_transform)
train_val_loader = DataLoader(train_val_set, batch_size=batch_size, shuffle=True)
model_best = Classifier().cuda() # cuda加速
loss = nn.CrossEntropyLoss() # 因为是分类任务,所以使用交叉熵损失
optimizer = torch.optim.Adam(model_best.parameters(), lr=0.001) # optimizer 使用 Adam
num_epoch = 30
for epoch in range(num_epoch):
epoch_start_time = time.time()
train_acc = 0.0
train_loss = 0.0
model_best.train()
for i, data in enumerate(train_val_loader):
optimizer.zero_grad()
train_pred = model_best(data[0].cuda())
batch_loss = loss(train_pred, data[1].cuda())
batch_loss.backward()
optimizer.step()
train_acc += np.sum(np.argmax(train_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
train_loss += batch_loss.item()
#将结果 print 出來
print('[%03d/%03d] %2.2f sec(s) Train Acc: %3.6f Loss: %3.6f' % \
(epoch + 1, num_epoch, time.time()-epoch_start_time, \
train_acc/train_val_set.__len__(), train_loss/train_val_set.__len__()))
Out:
[001/030] 36.50 sec(s) Train Acc: 0.244961 Loss: 0.017617
[002/030] 36.56 sec(s) Train Acc: 0.352136 Loss: 0.014405
[003/030] 36.65 sec(s) Train Acc: 0.418697 Loss: 0.012998
[004/030] 36.70 sec(s) Train Acc: 0.465403 Loss: 0.011988
[005/030] 36.73 sec(s) Train Acc: 0.503836 Loss: 0.011090
[006/030] 36.61 sec(s) Train Acc: 0.543096 Loss: 0.010332
[007/030] 36.70 sec(s) Train Acc: 0.574985 Loss: 0.009589
[008/030] 36.66 sec(s) Train Acc: 0.600632 Loss: 0.008945
[009/030] 36.74 sec(s) Train Acc: 0.626203 Loss: 0.008440
[010/030] 36.66 sec(s) Train Acc: 0.654934 Loss: 0.007876
[011/030] 36.73 sec(s) Train Acc: 0.667795 Loss: 0.007432
[012/030] 36.69 sec(s) Train Acc: 0.688327 Loss: 0.006982
[013/030] 36.76 sec(s) Train Acc: 0.701489 Loss: 0.006671
[014/030] 36.78 sec(s) Train Acc: 0.722473 Loss: 0.006285
[015/030] 36.72 sec(s) Train Acc: 0.740147 Loss: 0.005876
[016/030] 36.68 sec(s) Train Acc: 0.749323 Loss: 0.005666
[017/030] 36.66 sec(s) Train Acc: 0.764591 Loss: 0.005263
[018/030] 36.71 sec(s) Train Acc: 0.780310 Loss: 0.004988
[019/030] 36.69 sec(s) Train Acc: 0.795578 Loss: 0.004540
[020/030] 36.71 sec(s) Train Acc: 0.807536 Loss: 0.004302
[021/030] 36.66 sec(s) Train Acc: 0.823029 Loss: 0.003945
[022/030] 36.67 sec(s) Train Acc: 0.834311 Loss: 0.003793
[023/030] 36.66 sec(s) Train Acc: 0.842283 Loss: 0.003520
[024/030] 36.67 sec(s) Train Acc: 0.848827 Loss: 0.003342
[025/030] 36.64 sec(s) Train Acc: 0.862966 Loss: 0.003062
[026/030] 36.72 sec(s) Train Acc: 0.877933 Loss: 0.002741
[027/030] 36.67 sec(s) Train Acc: 0.874925 Loss: 0.002796
[028/030] 36.66 sec(s) Train Acc: 0.883123 Loss: 0.002496
[029/030] 36.66 sec(s) Train Acc: 0.897037 Loss: 0.002285
[030/030] 36.68 sec(s) Train Acc: 0.900346 Loss: 0.002199
测试
用刚才训练好的模型,在test set上进行测试。
Pytorch中的 model.train() 和 model.eval() 模式
- model.train() :启用 BatchNormalization 和 Dropout
- model.eval() :不启用 BatchNormalization 和 Dropout
test_set = ImgDataset(test_x, transform=test_transform)
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False)
model_best.eval()
prediction = []
with torch.no_grad():
for i, data in enumerate(test_loader):
test_pred = model_best(data.cuda())
# 预测值中概率最大的下标即为模型预测的食物标签
test_label = np.argmax(test_pred.cpu().data.numpy(), axis=1)
for y in test_label:
prediction.append(y)
#将预测结果写入 csv
with open("predict.csv", 'w') as f:
f.write('Id,Category\n')
for i, y in enumerate(prediction):
f.write('{},{}\n'.format(i, y))
导出文件是predict.csv,提交至kaggle平台进行测试。

说明:本文提交的时候,未到作业ddl,所以暂时没有Private Score。
Public Score为0.71249,是baseline的分数。
接下来,需要修改模型,提高Public Score分数。
3 修改代码
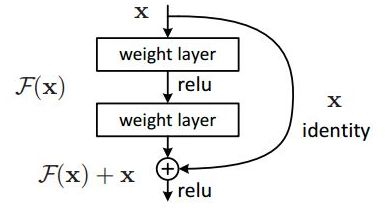
修改1:残差神经网络
将原来的Classifier()这个简单的卷积神经网络改成残差神经网络的结构,定义了一个残差块Residual_Block()和一个残差神经网络ResNet()。
一个残差块的结构如下 :
训练的num_epoch改为60次。
完整代码如下:
import os
import numpy as np
import cv2
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import pandas as pd
from torch.utils.data import DataLoader, Dataset
import time
import random
import matplotlib.pyplot as plt #画图
#定义一个读取图片的函数readfile()
def readfile(path, label):
# label 是一个布尔值,代表需不需要返回 y 值
image_dir = sorted(os.listdir(path))
# x存储图片,每张彩色图片都是128(高)*128(宽)*3(彩色三通道)
x = np.zeros((len(image_dir), 128, 128, 3), dtype=np.uint8)
# y存储标签,每个y大小为1
y = np.zeros((len(image_dir)), dtype=np.uint8)
for i, file in enumerate(image_dir):
img = cv2.imread(os.path.join(path, file))
# 利用cv2.resize()函数将不同大小的图片统一为128(高)*128(宽)
x[i, :, :] = cv2.resize(img,(128, 128))
if label:
y[i] = int(file.split("_")[0])
if label:
return x, y
else:
return x
#分别将 training set、validation set、testing set 用函数 readfile() 读进来
workspace_dir = './food-11'
print("Reading data")
train_x, train_y = readfile(os.path.join(workspace_dir, "training"), True)
print("Size of training data = {}".format(len(train_x)))
val_x, val_y = readfile(os.path.join(workspace_dir, "validation"), True)
print("Size of validation data = {}".format(len(val_x)))
test_x = readfile(os.path.join(workspace_dir, "testing"), False)
print("Size of Testing data = {}".format(len(test_x)))
#training 时,通过随机旋转、水平翻转图片来进行数据增强(data augmentation)
train_transform = transforms.Compose([
transforms.ToPILImage(),
transforms.RandomHorizontalFlip(), #随机翻转图片
transforms.RandomRotation(15), #随机旋转图片
transforms.ToTensor(), #将图片变成 Tensor,并且把数值normalize到[0,1]
])
#testing 时,不需要进行数据增强(data augmentation)
test_transform = transforms.Compose([
transforms.ToPILImage(),
transforms.ToTensor(),
])
class ImgDataset(Dataset):
def __init__(self, x, y=None, transform=None):
self.x = x
# label 需要是 LongTensor 型
self.y = y
if y is not None:
self.y = torch.LongTensor(y)
self.transform = transform
def __len__(self):
return len(self.x)
def __getitem__(self, index):
X = self.x[index]
if self.transform is not None:
X = self.transform(X)
if self.y is not None:
Y = self.y[index]
return X, Y
else:
return X
#定义残差块
class Residual_Block(nn.Module):
def __init__(self, i_channel, o_channel, stride=1, down_sample=None):
super(Residual_Block, self).__init__()
self.conv1 = nn.Conv2d(in_channels=i_channel,
out_channels=o_channel,
kernel_size=3,
stride=stride,
padding=1,
bias=False)
# BatchNorm2d()对小批量3d数据组成的4d输入进行批标准化操作
# 主要为了防止神经网络退化
self.bn1 = nn.BatchNorm2d(o_channel)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(in_channels=o_channel,
out_channels=o_channel,
kernel_size=3,
stride=1,
padding=1,
bias=False)
self.bn2 = nn.BatchNorm2d(o_channel)
self.down_sample = down_sample
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
# 将单元的输入直接与单元输出加在一起
if self.down_sample:
residual = self.down_sample(x) # 下采样
out += residual
out = self.relu(out)
return out
# 定义残差神经网络
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=11):
super(ResNet, self).__init__()
self.conv = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=1, padding=1, bias=False)
self.in_channels = 16
self.bn = nn.BatchNorm2d(16)
self.relu = nn.ReLU(inplace=True)
self.layer1 = self.make_layer(block, 16, layers[0])
self.layer2 = self.make_layer(block, 32, layers[0], 2)
self.layer3 = self.make_layer(block, 64, layers[1], 2)
self.avg_pool = nn.AvgPool2d(8)
self.fc = nn.Linear(1024, num_classes)
def make_layer(self, block, out_channels, blocks, stride=1):
# blocks=layers,残差模块的数量
down_sample = None
# 判断是否in_channels(输入)与(输出)是否在同一维度
# 即输入的3d数据的长宽高与输出的数据的长宽高是否一样
if (stride != 1) or (self.in_channels != out_channels):
# 如果不一样就转换一下维度
down_sample = nn.Sequential(
nn.Conv2d(self.in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_channels)
)
layers = []
layers.append(block(self.in_channels, out_channels, stride, down_sample))
self.in_channels = out_channels
for i in range(1, blocks):
layers.append(block(out_channels, out_channels))
return nn.Sequential(*layers) # 添加所有残差块
def forward(self, x):
out = self.conv(x)
out = self.bn(out)
out = self.relu(out)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.avg_pool(out)
out = out.view(out.size()[0], -1)
out = self.fc(out)
return out
#更新学习率
def update_lr(optimizer,lr):
for param_group in optimizer.param_groups:
param_group['lr']=lr
# 固定随机种子
random.seed(1)
# 超参数设定
batch_size = 64
learning_rate=1e-3
#加载训练集、验证集
train_set = ImgDataset(train_x, train_y, train_transform)
val_set = ImgDataset(val_x, val_y, test_transform)
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_set, batch_size=batch_size, shuffle=False)
# 定义模型
model = ResNet(Residual_Block, [2, 2, 2, 2]).cuda()
loss = nn.CrossEntropyLoss() # 因为是分类任务,所以使用交叉熵损失
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) # 使用Adam优化器
num_epoch = 60 #迭代次数
# 保存每个iteration的loss和accuracy,以便后续画图
plt_train_loss = []
plt_val_loss = []
plt_train_acc = []
plt_val_acc = []
# 用测试集训练模型model(),用验证集作为测试集来验证
curr_lr=learning_rate
for epoch in range(num_epoch):
epoch_start_time = time.time()
train_acc = 0.0
train_loss = 0.0
val_acc = 0.0
val_loss = 0.0
model.train() # 确保 model 是在 训练 model (开启 Dropout 等...)
for i, data in enumerate(train_loader):
optimizer.zero_grad() # 用 optimizer 将模型参数的梯度 gradient 归零
train_pred = model(data[0].cuda()) # 利用 model 得到预测的概率分布,这边实际上是调用模型的 forward 函数
batch_loss = loss(train_pred, data[1].cuda()) # 计算 loss (注意 prediction 跟 label 必须同时在 CPU 或是 GPU 上)
batch_loss.backward() # 利用 back propagation 算出每个参数的 gradient
optimizer.step() # 以 optimizer 用 gradient 更新参数
train_acc += np.sum(np.argmax(train_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
train_loss += batch_loss.item()
#验证集val
model.eval()
with torch.no_grad():
for i, data in enumerate(val_loader):
val_pred = model(data[0].cuda())
batch_loss = loss(val_pred, data[1].cuda())
val_acc += np.sum(np.argmax(val_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
val_loss += batch_loss.item()
#保存用于画图
plt_train_acc.append(train_acc/train_set.__len__())
plt_train_loss.append(train_loss/train_set.__len__())
plt_val_acc.append(val_acc/val_set.__len__())
plt_val_loss.append(val_loss/val_set.__len__())
#将结果 print 出來
print('[%03d/%03d] %2.2f sec(s) Train Acc: %3.6f Loss: %3.6f | Val Acc: %3.6f loss: %3.6f' % \
(epoch + 1, num_epoch, time.time()-epoch_start_time, \
plt_train_acc[-1], plt_train_loss[-1], plt_val_acc[-1], plt_val_loss[-1]))
# Loss曲线
plt.plot(plt_train_loss)
plt.plot(plt_val_loss)
plt.title('Loss')
plt.legend(['train', 'val'])
plt.savefig('loss.png')
plt.show()
# Accuracy曲线
plt.plot(plt_train_acc)
plt.plot(plt_val_acc)
plt.title('Accuracy')
plt.legend(['train', 'val'])
plt.savefig('acc.png')
plt.show()
# 将训练集和验证集一起拿来训练模型model_best()
random.seed(1)
train_val_x = np.concatenate((train_x, val_x), axis=0) # 将train_x和val_x拼接起来
train_val_y = np.concatenate((train_y, val_y), axis=0) # 将train_y和val_y拼接起来
train_val_set = ImgDataset(train_val_x, train_val_y, train_transform)
train_val_loader = DataLoader(train_val_set, batch_size=batch_size, shuffle=True)
model_best = ResNet(Residual_Block, [2, 2, 2, 2]).cuda()
loss = nn.CrossEntropyLoss() # 因为是分类任务,所以使用交叉熵损失
optimizer = torch.optim.Adam(model_best.parameters(), lr=learning_rate) # 使用Adam优化器
num_epoch = 60 #迭代次数
for epoch in range(num_epoch):
epoch_start_time = time.time()
train_acc = 0.0
train_loss = 0.0
model_best.train()
for i, data in enumerate(train_val_loader):
optimizer.zero_grad()
train_pred = model_best(data[0].cuda())
batch_loss = loss(train_pred, data[1].cuda())
batch_loss.backward()
optimizer.step()
train_acc += np.sum(np.argmax(train_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
train_loss += batch_loss.item()
#将结果 print 出來
print('[%03d/%03d] %2.2f sec(s) Train Acc: %3.6f Loss: %3.6f' % \
(epoch + 1, num_epoch, time.time()-epoch_start_time, \
train_acc/train_val_set.__len__(), train_loss/train_val_set.__len__()))
test_set = ImgDataset(test_x, transform=test_transform)
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False)
model_best.eval()
prediction = []
with torch.no_grad():
for i, data in enumerate(test_loader):
test_pred = model_best(data.cuda())
# 预测值中概率最大的下标即为模型预测的食物标签
test_label = np.argmax(test_pred.cpu().data.numpy(), axis=1)
for y in test_label:
prediction.append(y)
#将预测结果写入 csv
with open("predict.csv", 'w') as f:
f.write('Id,Category\n')
for i, y in enumerate(prediction):
f.write('{},{}\n'.format(i, y))
model(只拿train_set训练)的结果是:Public Score=0.77525
model_best(拿train_set和val_set一起训练)的结果是:Public Score=0.82307
修改2:残差神经网络+dropout
dropout层可以有效控制过拟合问题。
在上一个残差神经网络的基础上,加入dropout层。训练的num_epoch改为100次。
import os
import numpy as np
import cv2
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import pandas as pd
from torch.utils.data import DataLoader, Dataset
import time
import random
import matplotlib.pyplot as plt #画图
#定义一个读取图片的函数readfile()
def readfile(path, label):
# label 是一个布尔值,代表需不需要返回 y 值
image_dir = sorted(os.listdir(path))
# x存储图片,每张彩色图片都是128(高)*128(宽)*3(彩色三通道)
x = np.zeros((len(image_dir), 128, 128, 3), dtype=np.uint8)
# y存储标签,每个y大小为1
y = np.zeros((len(image_dir)), dtype=np.uint8)
for i, file in enumerate(image_dir):
img = cv2.imread(os.path.join(path, file))
# 利用cv2.resize()函数将不同大小的图片统一为128(高)*128(宽)
x[i, :, :] = cv2.resize(img,(128, 128))
if label:
y[i] = int(file.split("_")[0])
if label:
return x, y
else:
return x
#分别将 training set、validation set、testing set 用函数 readfile() 读进来
workspace_dir = './food-11'
print("Reading data")
train_x, train_y = readfile(os.path.join(workspace_dir, "training"), True)
print("Size of training data = {}".format(len(train_x)))
val_x, val_y = readfile(os.path.join(workspace_dir, "validation"), True)
print("Size of validation data = {}".format(len(val_x)))
test_x = readfile(os.path.join(workspace_dir, "testing"), False)
print("Size of Testing data = {}".format(len(test_x)))
#training 时,通过随机旋转、水平翻转图片来进行数据增强(data augmentation)
train_transform = transforms.Compose([
transforms.ToPILImage(),
transforms.RandomHorizontalFlip(), #随机翻转图片
transforms.RandomRotation(15), #随机旋转图片
transforms.ToTensor(), #将图片变成 Tensor,并且把数值normalize到[0,1]
])
#testing 时,不需要进行数据增强(data augmentation)
test_transform = transforms.Compose([
transforms.ToPILImage(),
transforms.ToTensor(),
])
class ImgDataset(Dataset):
def __init__(self, x, y=None, transform=None):
self.x = x
# label 需要是 LongTensor 型
self.y = y
if y is not None:
self.y = torch.LongTensor(y)
self.transform = transform
def __len__(self):
return len(self.x)
def __getitem__(self, index):
X = self.x[index]
if self.transform is not None:
X = self.transform(X)
if self.y is not None:
Y = self.y[index]
return X, Y
else:
return X
#定义残差块
class Residual_Block(nn.Module):
def __init__(self, i_channel, o_channel, stride=1, down_sample=None):
super(Residual_Block, self).__init__()
self.conv1 = nn.Conv2d(in_channels=i_channel,
out_channels=o_channel,
kernel_size=3,
stride=stride,
padding=1,
bias=False)
# BatchNorm2d()对小批量3d数据组成的4d输入进行批标准化操作
# 主要为了防止神经网络退化
self.bn1 = nn.BatchNorm2d(o_channel)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(in_channels=o_channel,
out_channels=o_channel,
kernel_size=3,
stride=1,
padding=1,
bias=False)
self.bn2 = nn.BatchNorm2d(o_channel)
self.down_sample = down_sample
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
# 将单元的输入直接与单元输出加在一起
if self.down_sample:
residual = self.down_sample(x) # 下采样
out += residual
out = self.relu(out)
return out
# 定义残差神经网络
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=11):
super(ResNet, self).__init__()
self.conv = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=1, padding=1, bias=False)
self.in_channels = 16
self.bn = nn.BatchNorm2d(16)
self.relu = nn.ReLU(inplace=True)
self.layer1 = self.make_layer(block, 16, layers[0])
self.layer2 = self.make_layer(block, 32, layers[0], 2)
self.layer3 = self.make_layer(block, 64, layers[1], 2)
self.avg_pool = nn.AvgPool2d(8)
self.fc = nn.Linear(1024, num_classes)
self.dropout = nn.Dropout(p=0.5) # dropout
def make_layer(self, block, out_channels, blocks, stride=1):
# blocks=layers,残差模块的数量
down_sample = None
# 判断是否in_channels(输入)与(输出)是否在同一维度
# 即输入的3d数据的长宽高与输出的数据的长宽高是否一样
if (stride != 1) or (self.in_channels != out_channels):
# 如果不一样就转换一下维度
down_sample = nn.Sequential(
nn.Conv2d(self.in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_channels)
)
layers = []
layers.append(block(self.in_channels, out_channels, stride, down_sample))
self.in_channels = out_channels
for i in range(1, blocks):
layers.append(block(out_channels, out_channels))
return nn.Sequential(*layers) # 添加所有残差块
def forward(self, x):
out = self.conv(x)
out = self.bn(out)
out = self.relu(out)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.avg_pool(out)
out = self.dropout(out) # dropout
out = out.view(out.size()[0], -1)
out = self.fc(out)
return out
#更新学习率
def update_lr(optimizer,lr):
for param_group in optimizer.param_groups:
param_group['lr']=lr
# 固定随机种子
random.seed(1)
# 超参数设定
batch_size = 64
learning_rate=1e-3
#加载训练集、验证集
train_set = ImgDataset(train_x, train_y, train_transform)
val_set = ImgDataset(val_x, val_y, test_transform)
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_set, batch_size=batch_size, shuffle=False)
model = ResNet(Residual_Block, [2, 2, 2, 2]).cuda()
loss = nn.CrossEntropyLoss() # 因为是分类任务,所以使用交叉熵损失
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) # 使用Adam优化器
num_epoch = 100 #迭代次数
# 保存每个iteration的loss和accuracy,以便后续画图
plt_train_loss = []
plt_val_loss = []
plt_train_acc = []
plt_val_acc = []
# 用测试集训练模型model(),用验证集作为测试集来验证
curr_lr=learning_rate
for epoch in range(num_epoch):
epoch_start_time = time.time()
train_acc = 0.0
train_loss = 0.0
val_acc = 0.0
val_loss = 0.0
model.train() # 确保 model 是在 训练 model (开启 Dropout 等...)
for i, data in enumerate(train_loader):
optimizer.zero_grad() # 用 optimizer 将模型参数的梯度 gradient 归零
train_pred = model(data[0].cuda()) # 利用 model 得到预测的概率分布,这边实际上是调用模型的 forward 函数
batch_loss = loss(train_pred, data[1].cuda()) # 计算 loss (注意 prediction 跟 label 必须同时在 CPU 或是 GPU 上)
batch_loss.backward() # 利用 back propagation 算出每个参数的 gradient
optimizer.step() # 以 optimizer 用 gradient 更新参数
train_acc += np.sum(np.argmax(train_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
train_loss += batch_loss.item()
#验证集val
model.eval()
with torch.no_grad():
for i, data in enumerate(val_loader):
val_pred = model(data[0].cuda())
batch_loss = loss(val_pred, data[1].cuda())
val_acc += np.sum(np.argmax(val_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
val_loss += batch_loss.item()
#保存用于画图
plt_train_acc.append(train_acc/train_set.__len__())
plt_train_loss.append(train_loss/train_set.__len__())
plt_val_acc.append(val_acc/val_set.__len__())
plt_val_loss.append(val_loss/val_set.__len__())
#将结果 print 出來
print('[%03d/%03d] %2.2f sec(s) Train Acc: %3.6f Loss: %3.6f | Val Acc: %3.6f loss: %3.6f' % \
(epoch + 1, num_epoch, time.time()-epoch_start_time, \
plt_train_acc[-1], plt_train_loss[-1], plt_val_acc[-1], plt_val_loss[-1]))
# Loss曲线
plt.plot(plt_train_loss)
plt.plot(plt_val_loss)
plt.title('Loss')
plt.legend(['train', 'val'])
plt.savefig('loss.png')
plt.show()
# Accuracy曲线
plt.plot(plt_train_acc)
plt.plot(plt_val_acc)
plt.title('Accuracy')
plt.legend(['train', 'val'])
plt.savefig('acc.png')
plt.show()
# 将训练集和验证集一起拿来训练模型model_best()
random.seed(1)
train_val_x = np.concatenate((train_x, val_x), axis=0) # 将train_x和val_x拼接起来
train_val_y = np.concatenate((train_y, val_y), axis=0) # 将train_y和val_y拼接起来
train_val_set = ImgDataset(train_val_x, train_val_y, train_transform)
train_val_loader = DataLoader(train_val_set, batch_size=batch_size, shuffle=True)
model_best = ResNet(Residual_Block, [2, 2, 2, 2]).cuda()
loss = nn.CrossEntropyLoss() # 因为是分类任务,所以使用交叉熵损失
optimizer = torch.optim.Adam(model_best.parameters(), lr=learning_rate) # 使用Adam优化器
num_epoch = 100 #迭代次数
for epoch in range(num_epoch):
epoch_start_time = time.time()
train_acc = 0.0
train_loss = 0.0
model_best.train()
for i, data in enumerate(train_val_loader):
optimizer.zero_grad()
train_pred = model_best(data[0].cuda())
batch_loss = loss(train_pred, data[1].cuda())
batch_loss.backward()
optimizer.step()
train_acc += np.sum(np.argmax(train_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
train_loss += batch_loss.item()
#将结果 print 出來
print('[%03d/%03d] %2.2f sec(s) Train Acc: %3.6f Loss: %3.6f' % \
(epoch + 1, num_epoch, time.time()-epoch_start_time, \
train_acc/train_val_set.__len__(), train_loss/train_val_set.__len__()))
test_set = ImgDataset(test_x, transform=test_transform)
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False)
model_best.eval()
prediction = []
with torch.no_grad():
for i, data in enumerate(test_loader):
test_pred = model_best(data.cuda())
# 预测值中概率最大的下标即为模型预测的食物标签
test_label = np.argmax(test_pred.cpu().data.numpy(), axis=1)
for y in test_label:
prediction.append(y)
#将预测结果写入 csv
with open("predict.csv", 'w') as f:
f.write('Id,Category\n')
for i, y in enumerate(prediction):
f.write('{},{}\n'.format(i, y))
model(只拿train_set训练)的结果是:Public Score = 0.81350
model_best(拿train_set和val_set一起训练)的结果是:Public Score=0.82946