Pytorch_模型转Caffe(三)pytorch转caffemodel
文章目录
- Pytorch_模型转Caffe(三)pytorch转caffemodel
-
- 1. Pytorch下生成模型
- 2. pth转换成caffemodel和prototxt
- 3. `pytorch_to_caffe_alexNet.py`剖析
- 4. 用转换后的模型进行推理
- 5. `prototxt`注意问题
Pytorch_模型转Caffe(三)pytorch转caffemodel
- 模型转换基于GitHub上xxradon的代码进行优化,在此对作者表示感谢。GitHub地址:https://github.com/xxradon/PytorchToCaffe
- 本文基于AlexNet网络对MNIST手写字体分类生成的模型*.pth进行转换
1. Pytorch下生成模型
- 调用
torchvision.models.alexnet下的alexnet网络 - 修改网络输入层数 1 ,输出类别数量 10
classifier下的dropout位置需要调整
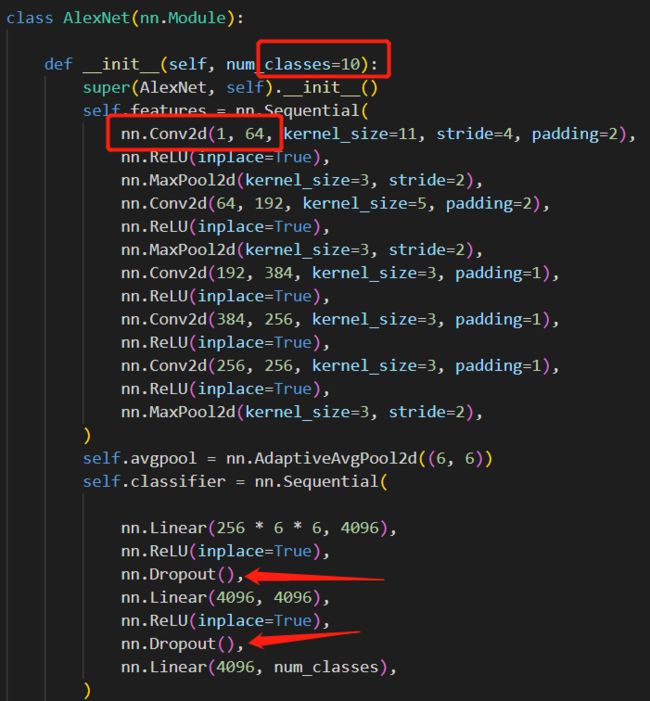
- 通过一下代码训练手写数字识别,最终生成模型
mnist_alexnet_model.pth(这里保存了整个网络和权重)
import time
import torch
from torch import nn, optim
import torchvision
import pytorch_deep as pyd
from torchvision.models.alexnet import alexnet
net = alexnet(False)
device = torch.device('cuda' if torch.cuda.is_available() else'cpu')
def load_data_fashion_mnist(batch_size = 256,resize=None,num_workers = 0):
trans = []
if resize:
trans.append(torchvision.transforms.Resize(size=resize))
trans.append(torchvision.transforms.ToTensor())
transform = torchvision.transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(root='./MNIST', train=True, download=True,
transform=transform)
mnist_test = torchvision.datasets.FashionMNIST(root='./MNIST', train=False, download=True,
transform=transform)
train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=num_workers)
test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False, num_workers=num_workers)
return train_iter,test_iter
batch_size = 128
# 如出现“out of memory”的报错信息,可减⼩batch_size或resize
train_iter, test_iter = load_data_fashion_mnist(batch_size,resize=224)
lr, num_epochs = 0.001, 5
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
pyd.train_ch5(net, train_iter, test_iter, batch_size, optimizer,device, num_epochs)
2. pth转换成caffemodel和prototxt
git clone下载GitHub源码,进入example下的Alexnet实例- 主要用到以下两个文件,一个是加载网络模型,一个是进行prototxt和caffemodel的转换
- 先看
alexnet_pytorch_to_caffe.py
import sys
sys.path.insert(0,'.')
import torch
from torch.autograd import Variable
from torchvision.models.alexnet import alexnet
import pytorch_to_caffe_alexNet
import cv2
if __name__=='__main__':
name='alexnet'
pth_path = '***/mnist_alexnet_model.pth'
net = torch.load(pth_path)
net.eval()
input=Variable(torch.FloatTensor(torch.ones([1,1,224,224])))
input = input.cuda()
pytorch_to_caffe_alexNet.save_prototxt('{}.prototxt'.format(name))
pytorch_to_caffe_alexNet.save_caffemodel('{}.caffemodel'.format(name))
- 如果直接运行发现会报错,我这里的错误出现在
dropout层转化的位置,修改其bottom和top传参 - 修改完
dropout,运行正常,能够生产caffemodel和prototxt,但prototxt网络结构有问题,还是前后层衔接不对 - 参照原版deploy.prototxt进行layer的修改,最终输出了正确的结果

3. pytorch_to_caffe_alexNet.py剖析
- 该文件就是对pth文件进行解析,获得layer的名称和每层的权重偏差,并以caffe的格式进行存储
- 修改了pytorch Function中的函数,让其在前向传播的时候自动将该层的参数保存到caffe
- 很多层的前后衔接不对,都需要强制进行修改
- 下面是修改的部分函数
def _dropout(raw,input,p=0.5, training=False, inplace=False):
x=raw(input,p, training, False)
layer_name=log.add_layer(name='dropout')
log.add_blobs([x],name='dropout_blob')
bottom_top_name = 'fc_blob' + layer_name[-1]
layer=caffe_net.Layer_param(name=layer_name,type='Dropout',
bottom=[bottom_top_name],top=[bottom_top_name])
layer.param.dropout_param.dropout_ratio = p
log.cnet.add_layer(layer)
return x
def _linear(raw,input, weight, bias=None):
x=raw(input,weight,bias)
layer_name=log.add_layer(name='fc')
top_blobs=log.add_blobs([x],name='fc_blob')
bottom_name = 'ave_pool_blob1' if top_blobs[-1][-1] =='1' else 'fc_blob'+str(int(top_blobs[-1][-1])-1)
layer=caffe_net.Layer_param(name=layer_name,type='InnerProduct',
bottom=[bottom_name],top=top_blobs)
layer.fc_param(x.size()[1],has_bias=bias is not None)
if bias is not None:
layer.add_data(weight.cpu().data.numpy(),bias.cpu().data.numpy())
else:
layer.add_data(weight.cpu().data.numpy())
log.cnet.add_layer(layer)
return x

4. 用转换后的模型进行推理
- 在caffe 下进行测试 test_alexnet.sh
#!/bin/bash
set -e
./build/examples/cpp_classification/classification.bin \
/home/****/alexnet.prototxt \
/home/****/alexnet.caffemodel \
examples/mnist/mnist_mean.binaryproto \
examples/mnist/mnist_label.txt \
data/mnist/1.png;
目前推理结果不太准,但整个过程都已经跑通

5. prototxt注意问题
-
推理过程发现每次的结果都不一样,发现prototxt中每个卷积层下都有初始化权重的偏差,将其统统删除

-
池化层下的
ceil_mode: false也是多余项,删除即可

至此已完成Pytorch到caffemodle的转换
这只是初步尝试通过,接下来要进行YOLOv4的转换,应该会遇到更多的问题,加油!