Hive进阶之执行计划(4)
执行计划explain
执行计划这个东西无论是在hive里还是数据库管理系统中都是很重要的,因为它可以帮助我们理解SQL的执行,从而更好的去优化SQL,而不是一味的凭经验去做一些操作,使其看起来像神学。hive 也通过explain 提供了如何让用户去获得一个查询语句的执行计划
一般情况下一个SQL执行计划有两个部分:stage dependencies描述了各个stage之间的依赖性,stage plan描述了各个stage的执行细节,每个Stage 的执行计划几乎是由两部分组成的Map Operator Tree 和Reduce Operator Tree,Map Operator Tree MAP端的执行计划,Reduce Operator Tree Reduce端的执行计划。
执行计划的组成
explain select * from ods_temperature order by year limit 2
一个stage并不一定是一个MR,有可能是Fetch Operator,也有可能是Move或者是Rename甚至是和metastore 做交互,例如我们下面的图中的Stage-0

STAGE DEPENDENCIES
描述了各个stage之间的依赖性,本身的话构成一个有向无环图

STAGE PLANS
里面包含了多个stage,然后详细描述了各个stage的执行细节,这些描述信息主要依次描述了里面的Operator的信息,就像FilterOperator的过滤表达式,selectOperator的select 表达式, FileSinkOperator的输出文件名
每个Stage 的执行计划几乎是由两部分组成的Map Operator Tree 和Reduce Operator Tree,Map Operator Tree MAP端的执行计划,Reduce Operator Tree Reduce端的执行计划,有时候会因为没有reduce 操作,导致没有执行计划没有Reduce Operator Tree,像下面这个就没有Reduce Operator Tree

explain 可用参数
Explain 有几个很好用的参数,有时候可以帮助我们解决很多问题,EXPLAIN [EXTENDED|CBO|AST|DEPENDENCY|AUTHORIZATION|LOCKS|VECTORIZATION|ANALYZE] query
但是需要注意的是,你的当前版本可能不是支持上面所有的参数AUTHORIZATION 是从0.14版本开始支持的,VECTORIZATION 是从2.3.0 版本开始支持的,LOCKS 是从3.2 版本开始支持的,CBO 是从4.0 版本开始支持的,ANALYZE 是从2.2.0 开始支持的
其实为了学习和使用你可以尝试在电脑上装多个版本的,没什么太大的影响
DEPENDENCY
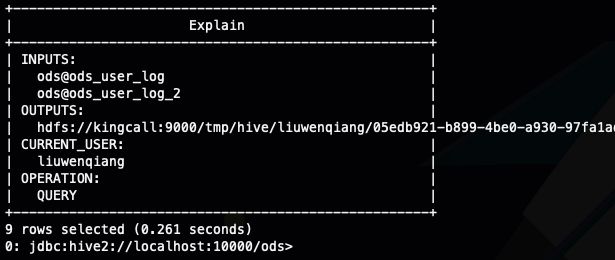
这个参数可以给你输出一个JSON 字符串,是你执行的SQL 依赖的表,会自动帮你过滤掉你的tmp 表
explain DEPENDENCY
select
*
from(
select
a.*
from
ods_user_log a
inner join
ods_user_log_2 b
on
a.id=b.id
)tmp
;
下面是输出结果,看到这个解析还是很准确的,有时候我们就想要个这样的信息发现还需要去写代码解析SQL ,其实这个工具就可以很好的满足我们的需求了
{
"input_tables":[
{
"tablename":"ods@ods_user_log",
"tabletype":"MANAGED_TABLE"
},
{
"tablename":"ods@ods_user_log_2",
"tabletype":"MANAGED_TABLE"
}
],
"input_partitions":[
]
}
EXTENDED
输出更加详细的执行计划,由于太长了我就不贴出来了,很典型的就是它会输出一些物理的文件地址信息
explain AUTHORIZATION
select
*
from(
select
a.*
from
ods_user_log a
inner join
ods_user_log_2 b
on
a.id=b.id
)tmp
;
AUTHORIZATION
你可以看到输入输出以及当前执行的用户等信息
explain AUTHORIZATION
select
*
from(
select
a.*
from
ods_user_log a
inner join
ods_user_log_2 b
on
a.id=b.id
)tmp
;
算子(operator)
前面我们说到HiveSQL 翻译成MR 的过程其实是将SQL解析成操作其实就是将SQL 解析成AST,然后将AST转化成QueryBlock,从而生成Operator Tree,然后将Operator Tree翻译成MR,Hive最终生成的MapReduce任务,Map阶段和Reduce阶段均由OperatorTree( Map Operator Tree 和Reduce Operator Tree )组成。需要注意的是不是所有的Operator的命名格式都是XXXOperator
Operator在Map Reduce阶段之间的数据传递都是一个流式的过程。每一个Operator对一行数据完成操作后之后将数据传递给childOperator计算。child 的关系是通过输出的层级关系展示的,Hive每一行数据经过一个Operator处理之后,会对字段重新编号,colExprMap记录每个表达式经过当前Operator处理前后的名称对应关系,在下一个阶段逻辑优化阶段用来回溯字段名
Operator对象有很多的属性和方法,例如 expressions,outputColumnNames,Statistics,aggregations
由于Hive的MapReduce程序是一个动态的程序,即不确定一个MapReduce Job会进行什么运算,可能是Join,也可能是GroupBy,所以Operator将所有运行时需要的参数保存在OperatorDesc中,OperatorDesc在提交任务前序列化到HDFS上,在MapReduce任务执行前从HDFS读取并反序列化。Map阶段OperatorTree在HDFS上的位置在Job.getConf(“hive.exec.plan”) + “/map.xml”
常见的operator
TableScanOperator 为MapReduce框架的Map接口输入表的数据,控制扫描表的数据行数,标记是从原表中取数据
SelectOperator 从表中获取哪些字段,对应着的是select 操作
FilterOperator 完成过滤操作
JoinOperator 完成Join操作
GroupByOperator 对应group by 操作,同时会出现在Map Operator Tree和Reduce Operator Tree 中
ReduceOutputOperator 将Map端的字段组合序列化为Reduce Key/value, Partition Key,只可能出现在Map阶段,同时也标志着Hive生成的MapReduce程序中Map阶段的结束。
####例子
下面我们介绍一些常见的Operator,我们主要是从下面这个SQL 的执行结果进行分析
explain
select
year,sum(temper) as sumtemper
from
ods_temperature
group by
year
order by
sumtemper desc
limit 2
;
Stage-1 Map Operator Tree
-
TableScan 读取数据,如果是从表中读取数据就会有alias这个属性

-
Select Operator 选取操作

-
Group By Operator 分组聚合, 常见的属性 aggregations、mode , 当没有keys属性时只有一个分组。

-
Reduce Output Operator 输出结果给Reduce , 常见的属性 sort order

sort order 用于Reduce Output Operator中
+ 正序排序
不排序
++按两列正序排序,如果有两列
+- 正反排序,如果有两列
-反向排序
如此类推
Stage-1 Reduce Operator Tree
-
Group By Operator 分组聚合完成,Map Operator Tree 的Group By Operator只是在select 中获取Group By结果

aggregations 用在Group By Operator中,例如count()计数 sum 求和
mode 用在Group By Operator中
hash 待定
mergepartial 合并部分聚合结果
final
-
File Output Operator 输出reduce 的计算结果

Stage-2 Map Operator Tree
- TableScan 不是从表中读取树的所以没有alias属性

-
Reduce Output Operator 因为是读取上一个reduce 的数据输出所以是Reduce Output Operator(上一个stage的 Map Operator Tree 中)

Stage-2 Reduce Operator Tree
-
Select Operator

-
Limit
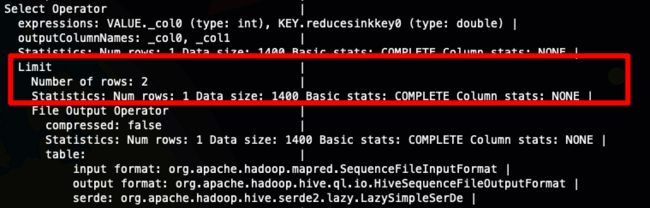
-
File Output Operator 输出结果

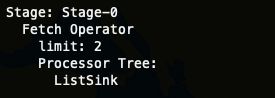
Stage-0
-
Fetch Operator 客户端获取数据 , 常见属性 limit
总结
这一节我们介绍了执行计划相关的一些基础的知识,学习执行计划可以更好的帮助我们理解SQL的执行流程,从而可以让我们以其作为参考,去优化我们的SQL,而不是盲目的或者是完全凭借所谓的经验去优化
下一节我们会准备一些例子,然后尝试着将SQL和执行计划结合起来去理解SQL执行的每一步,执行计划本身不难,主要还是要结合实际的例子尝试去理解
参考资料