【零散知识】CatBoost的简单了解
前言:
{
之前把《机器学习》上面的集成学习部分过了一遍,之后就想去做编程习题,但是经过搜索发现了很多新模型。上次介绍的是xgboos,而这次介绍CatBoost。
实际除此之外,我还试了lgbm、xgboost和sklearn(sklearn之后可能会单独介绍),但是在同一个数据集上,这3个模型很快(加起来才几分钟)就出结果了,而CatBoost跑了差不多8个小时(英特尔I7),后来换成GPU(英伟达860)还是跑了大概2小时,它也因此成功吸引了我的注意。
[1]是论文原文地址,[2]是官方说明文档。
}
正文:
{
第一部分:
部分现有方法:
首先,作者介绍了目前的集成学习方法的特点:它们都会把类别特征转换为数值(比如对性别来说,“男”被转换成0,“女”被转换成1),然而类别特征并没有大小之分。
有一种方法会使得特征与标签更为相关,即使用样本标签来缩放类别特征值:设![]() 为样本的m个特征的特征向量,
为样本的m个特征的特征向量,![]() 为标签值,则使用
为标签值,则使用![]() 来代替
来代替![]() (其中[·]代表Iverson bracket[3],[3=6]即Python里的3==6)。虽然我认为,其好处就是使得类别特征值和标签值更有关联,但论文中说这样做会导致过拟合,因为这种转换是建立在已有数据集上的,如果已有数据集中的某一个类别特征值只对应一个样本,那么这个样本的新类别特征值就会等于其标签值,如果要降低过拟合的话可能就需要把训练集划分出一部分来专门做统计。
(其中[·]代表Iverson bracket[3],[3=6]即Python里的3==6)。虽然我认为,其好处就是使得类别特征值和标签值更有关联,但论文中说这样做会导致过拟合,因为这种转换是建立在已有数据集上的,如果已有数据集中的某一个类别特征值只对应一个样本,那么这个样本的新类别特征值就会等于其标签值,如果要降低过拟合的话可能就需要把训练集划分出一部分来专门做统计。
CatBoost的新方法:
在此,作者引入了一种新的方法,其是上述方法的改进,见式(1)。

式(1)中a>0为一个参数;P为(标签)先验值,在回归任务中一般为数据集标签的平均值。(这里说到了随机排序,不过式(1)貌似和顺序没关系)
第二部分:
作者之后介绍了特征组合,我认为这便是CatBoost——categorical boosting的核心。结合[4]和[5],我大概对作者的意思有了些了解。
CatBoost中使用的是对称完全二叉树,每一次之划分出两条路径,划分的顺序是随机的,特征划分后特征维数并没有减少,但是用来划分的特征会与另一个类别特征相结合以形成新特征,结合的方式为贪心法,即从所有可能的组合中选择出最好的,因此也比较耗时。
第三部分:
结合[6],我理解的训练过程是CatBoost会按照上述多个随机顺序的样本序列进行多次训练,值得一提的是,每个样本序列的训练会抛弃最后一个样本(因为顺序是随机的,所以最后一个样本也是随机的)。下面的伪代码描述了模型训练过程。

其中n为样本数量。可以看到,对于每个模型,训练过程不直接使用所有样本,所有![]() 的初值都被设置为0。每次gradient boosting的迭代包括:一开始,当前训练数据集为空,也是说
的初值都被设置为0。每次gradient boosting的迭代包括:一开始,当前训练数据集为空,也是说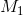 是一个无效的模型;之后添加1个样本,并且在已添加的1个样本上通过对原来的
是一个无效的模型;之后添加1个样本,并且在已添加的1个样本上通过对原来的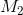 进行gradient boosting而训练出新;之后添加1个样本,并且在已添加的2个样本上通过对原来的
进行gradient boosting而训练出新;之后添加1个样本,并且在已添加的2个样本上通过对原来的![]() 进行gradient boosting而训练出新
进行gradient boosting而训练出新![]() ;继续直到在n-1个样本上通过gradient boosting训练出
;继续直到在n-1个样本上通过gradient boosting训练出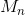 。M应该就是上面说的完全二叉树。(这里我有些不明白,伪代码中说I是树的数量,但我理解I是gradient boosting的迭代次数,最终输出总是n个模型)
。M应该就是上面说的完全二叉树。(这里我有些不明白,伪代码中说I是树的数量,但我理解I是gradient boosting的迭代次数,最终输出总是n个模型)
我认为这样可能还有个好处,通过样本的逐个添加,可以检测并剔除干扰样本,因为随着样本的增加,结果应该变得更为准确。
}
结语:
{
看来是特征组合导致的计算耗时。不过在我现有的数据集上,CatBoost的效果确实比lgbm、xgboost和sklearn好。
这些都是自己的理解,可能会有错误。如果你想深入了解,建议浏览并总结多个人的文章。
小技巧:gpu计算单元的使用率可以通过任务管理器查看,如下图。

参考资料:
{
[1] https://arxiv.org/pdf/1810.11363.pdf
[2] https://catboost.ai/docs/concepts/about.html
[3] https://en.wikipedia.org/wiki/Iverson_bracket
[4] http://papers.nips.cc/paper/7898-catboost-unbiased-boosting-with-categorical-features.pdf
[5] https://blog.csdn.net/friyal/article/details/82758532
[6] https://blog.csdn.net/appleyuchi/article/details/85413352
}
}