windows平台下darknet训练自己的数据集
写完前面关于python接口的文章发现忘了写训练自己的数据集的文章了,这里补上,用的还是AlexeyAB版本的darknet。
第一步:首先就是用labelimg做标注,这一步是最费时间的,注意这里一张图片是可以同时标注多个物体的,只是要做好对照关系,我之前网上找了一些教程都只标注了一个物体,这里说明一下标注多个物体也是可以的。
第二步:构建训练时可以读取的文件夹目录格式,如下所示:
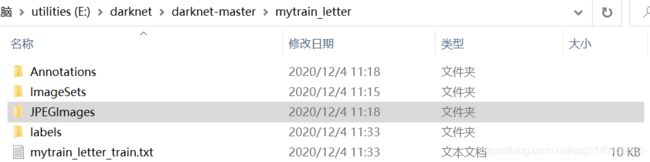
将xml文件放入Annotations文件夹,将图片放入JPEGImages文件夹,利用下面的代码1生成的mytrain_letter_train.txt文件就放在当前目录,代码1同时生成的表示坐标的txt文件放入labels文件夹,利用下面代码2将数据集分割为train、val、test、trainval四个文件。
# -*- coding: utf-8 -*-
"""
Created on Wed Nov 25 16:46:12 2020
@author: SS
"""
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
#源代码sets=[('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
sets=[('mytrain_letter', 'train')] # 改成自己建立的myData
classes = ["B_A","B_B","B_C","B_D","B_E","B_F","B_G","blue_A","blue_B","blue_C","blue_D","blue_E","blue_F","blue_G"] # 改成自己的类别
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('E:/darknet/darknet-master/mytrain_letter/Annotations/%s.xml'%(image_id)) # 源代码VOCdevkit/VOC%s/Annotations/%s.xml
out_file = open('E:/darknet/darknet-master/mytrain_letter/labels/%s.txt'%(image_id), 'w') # 源代码VOCdevkit/VOC%s/labels/%s.txt
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('E:/darknet/darknet-master/mytrain_letter/labels/'): # 改成自己建立的myData
os.makedirs('E:/darknet/darknet-master/mytrain_letter/labels/')
image_ids = open('E:/darknet/darknet-master/mytrain_letter/ImageSets/Main/%s.txt'%(image_set)).read().strip().split()
list_file = open('E:/darknet/darknet-master/mytrain_letter/%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('E:/darknet/darknet-master/mytrain_letter/JPEGImages/%s.jpg\n'%(image_id))
convert_annotation(year, image_id)
list_file.close()import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'E:\\darknet\\darknet-master\\mytrain_letter\\Annotations'
txtsavepath = 'E:\\darknet\\darknet-master\\mytrain_letter\\ImageSets\\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('E:/darknet/darknet-master/mytrain_letter/ImageSets/Main/trainval.txt', 'w')
ftest = open('E:/darknet/darknet-master/mytrain_letter/ImageSets/Main/test.txt', 'w')
ftrain = open('E:/darknet/darknet-master/mytrain_letter/ImageSets/Main/train.txt', 'w')
fval = open('E:/darknet/darknet-master/mytrain_letter/ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()如果自己没有数据集,也可以拍摄一个视频的帧提取成图片进行自己的数据集的制作,可以用下面的代码3进行视频帧提取:
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 20 14:02:07 2020
@author: SS
"""
# coding=utf-8
# 全局变量
VIDEO_PATH = 'C:\\Users\\SS\\Desktop\\sgcai_file\\test5.mp4' # 视频地址
EXTRACT_FOLDER = 'C:\\Users\\SS\Desktop\\sgcai_file\\result_video5\\pic' # 存放帧图片的位置
EXTRACT_FREQUENCY = 2 # 帧提取频率
def extract_frames(video_path, dst_folder, index):
# 主操作
import cv2
video = cv2.VideoCapture()
if not video.open(video_path):
print("can not open the video")
exit(1)
count = 1
while True:
_, frame = video.read()
if frame is None:
break
if count % EXTRACT_FREQUENCY == 0:
save_path = "{}/{:>03d}.jpg".format(dst_folder, index)
cv2.imwrite(save_path, frame)
index += 1
count += 1
video.release()
# 打印出所提取帧的总数
print("Totally save {:d} pics".format(index-1))
def main():
# 递归删除之前存放帧图片的文件夹,并新建一个
import shutil
try:
shutil.rmtree(EXTRACT_FOLDER)
except OSError:
pass
import os
os.mkdir(EXTRACT_FOLDER)
# 抽取帧图片,并保存到指定路径
extract_frames(VIDEO_PATH, EXTRACT_FOLDER, 1)
if __name__ == '__main__':
main()第三步:修改参数:
①cfg文件:修改网络的参数,主要是训练的迭代次数、学习率和要检测的目标类别数量相关的参数
下面分为test和train两种模式,test的时候记得注释掉train的部分,train的时候注释掉test的部分

filters=3*(5+len(classes))=3*(5+14)=57
下面总共有三处,每处都要修改。
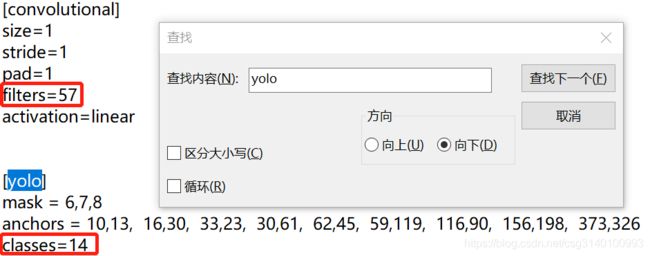
②data文件:检测类别数量、数据集的路径、类别对应名字、训练好的模型放置的路径

③names文件:类别对应的名字

第四步:下载预训练权重之后训练模型
下载:darknet53.conv.74
训练:darknet.exe detector train obj.data cfg/yolov3-obj.cfg darknet53.conv.74
第五步:python接口调用模型处理图片
# -*- coding: utf-8 -*-
"""
Created on Fri Jan 1 18:41:37 2021
@author: SS
"""
#coding:utf-8
import numpy as np
import cv2
import os
#%%
weightsPath='E:\\darknet\\darknet-master\\mytrain_letter\\yolov3-obj_final.weights'# 模型权重文件
configPath="E:\\darknet\\darknet-master\\build\\darknet\\x64\\cfg\\yolov3-obj.cfg"# 模型配置文件
labelsPath = "E:\\darknet\\darknet-master\\build\\darknet\\x64\\obj.names"# 模型类别标签文件
#%%
#初始化一些参数
LABELS = open(labelsPath).read().strip().split("\n")
print(LABELS)
#%%
boxes = []
confidences = []
classIDs = []
#加载 网络配置与训练的权重文件 构建网络
net = cv2.dnn.readNetFromDarknet(configPath,weightsPath)
#读入待检测的图像
image = cv2.imread('E:\\darknet\\darknet-master\\mytrain_letter\\JPEGImages\\001.jpg')
#得到图像的高和宽
(H,W) = image.shape[0:2]
print(H,W)
#%%
# 得到 YOLO需要的输出层
ln = net.getLayerNames()
#%%
print(ln)
#%%
out = net.getUnconnectedOutLayers()#得到未连接层得序号 [[200] /n [267] /n [400] ]
x = []
for i in out: # 1=[200]
x.append(ln[i[0]-1]) # i[0]-1 取out中的数字 [200][0]=200 ln(199)= 'yolo_82'
ln=x
print(ln)
# ln = ['yolo_82', 'yolo_94', 'yolo_106'] 得到 YOLO需要的输出层
#%%
#从输入图像构造一个blob,然后通过加载的模型,给我们提供边界框和相关概率
#blobFromImage(image, scalefactor=None, size=None, mean=None, swapRB=None, crop=None, ddepth=None)
blob = cv2.dnn.blobFromImage(image, 1 / 255.0, (416, 416),swapRB=True, crop=False)#构造了一个blob图像,对原图像进行了图像的归一化,缩放了尺寸 ,对应训练模型
net.setInput(blob) #将blob设为输入??? 具体作用还不是很清楚
layerOutputs = net.forward(ln) #ln此时为输出层名称 ,向前传播 得到检测结果
for output in layerOutputs: #对三个输出层 循环
for detection in output: #对每个输出层中的每个检测框循环
scores=detection[5:] #detection=[x,y,h,w,c,class1,class2] scores取第6位至最后
classID = np.argmax(scores)#np.argmax反馈最大值的索引
confidence = scores[classID]
if confidence >0.5:#过滤掉那些置信度较小的检测结果
box = detection[0:4] * np.array([W, H, W, H])
#print(box)
(centerX, centerY, width, height)= box.astype("int")
# 边框的左上角
x = int(centerX - (width / 2))
y = int(centerY - (height / 2))
# 更新检测出来的框
boxes.append([x, y, int(width), int(height)])
confidences.append(float(confidence))
classIDs.append(classID)
idxs=cv2.dnn.NMSBoxes(boxes, confidences, 0.2,0.3)
box_seq = idxs.flatten()#[ 2 9 7 10 6 5 4]
if len(idxs)>0:
for seq in box_seq:
(x, y) = (boxes[seq][0], boxes[seq][1]) # 框左上角
(w, h) = (boxes[seq][2], boxes[seq][3]) # 框宽高
if classIDs[seq]==0: #根据类别设定框的颜色
color = [0,0,255]
else:
color = [0,255,0]
cv2.rectangle(image, (x, y), (x + w, y + h), color, 2) # 画框
text = "{}: {:.4f}".format(LABELS[classIDs[seq]], confidences[seq])
cv2.putText(image, text, (x, y - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.3, color, 1) # 写字
cv2.namedWindow('Image', cv2.WINDOW_NORMAL)
cv2.imshow("Image", image)
cv2.waitKey(0)